 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Action Localization Crop in Video Retargeting for 3D ConvNets
Paper and Code
Nov 22, 2021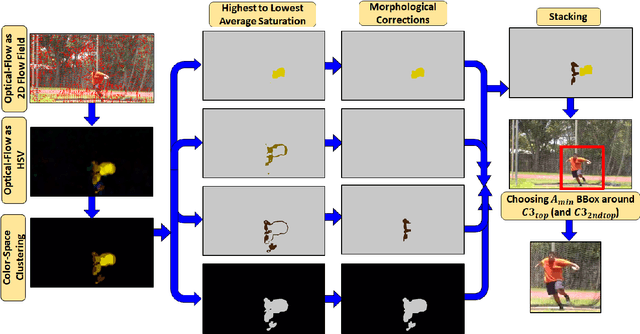
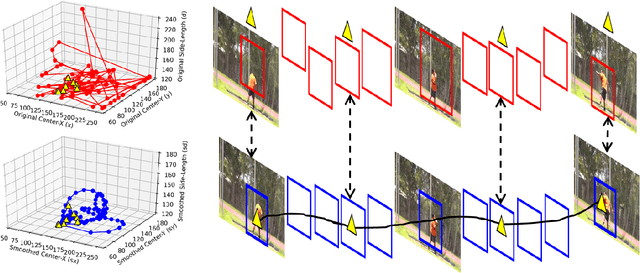

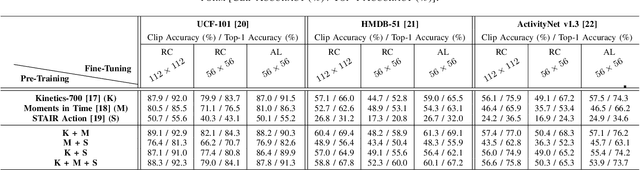
Untrimmed videos on social media or those captured by robots and surveillance cameras are of varied aspect ratios. However, 3D CNNs usually require as input a square-shaped video, whose spatial dimension is smaller than the original. Random- or center-cropping may leave out the video's subject altogether. To address this, we propose an unsupervised video cropping approach by shaping this as a retargeting and video-to-video synthesis problem. The synthesized video maintains a 1:1 aspect ratio, is smaller in size and is targeted at video-subject(s) throughout the entire duration. First, action localization is performed on each frame by identifying patches with homogeneous motion patterns. Thus, a single salient patch is pinpointed per frame. But to avoid viewpoint jitters and flickering, any inter-frame scale or position changes among the patches should be performed gradually over time. This issue is addressed with a polyBezier fitting in 3D space that passes through some chosen pivot timestamps and whose shape is influenced by the in-between control timestamps. To corroborate the effectiveness of the proposed method, we evaluate the video classification task by comparing our dynamic cropping technique with random cropping on three benchmark datasets, viz. UCF-101, HMDB-51 and ActivityNet v1.3. The clip and top-1 accuracy for video classification after our cropping, outperform 3D CNN performances for same-sized random-crop inputs, also surpassing some larger random-crop sizes.