 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Action Localization Crop in Video Retargeting for 3D ConvNets
Nov 22, 2021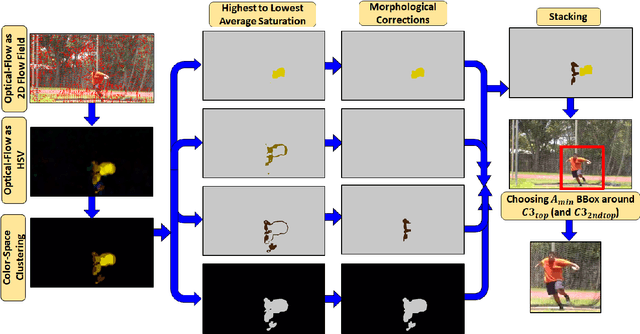
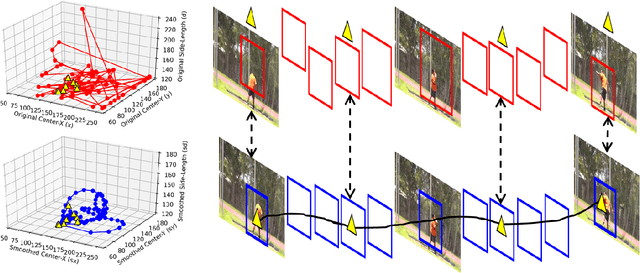

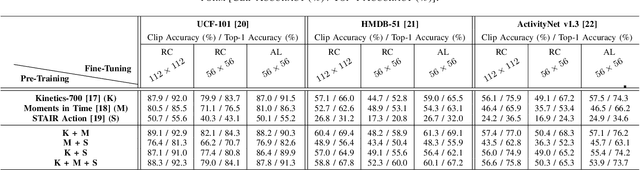
Untrimmed videos on social media or those captured by robots and surveillance cameras are of varied aspect ratios. However, 3D CNNs usually require as input a square-shaped video, whose spatial dimension is smaller than the original. Random- or center-cropping may leave out the video's subject altogether. To address this, we propose an unsupervised video cropping approach by shaping this as a retargeting and video-to-video synthesis problem. The synthesized video maintains a 1:1 aspect ratio, is smaller in size and is targeted at video-subject(s) throughout the entire duration. First, action localization is performed on each frame by identifying patches with homogeneous motion patterns. Thus, a single salient patch is pinpointed per frame. But to avoid viewpoint jitters and flickering, any inter-frame scale or position changes among the patches should be performed gradually over time. This issue is addressed with a polyBezier fitting in 3D space that passes through some chosen pivot timestamps and whose shape is influenced by the in-between control timestamps. To corroborate the effectiveness of the proposed method, we evaluate the video classification task by comparing our dynamic cropping technique with random cropping on three benchmark datasets, viz. UCF-101, HMDB-51 and ActivityNet v1.3. The clip and top-1 accuracy for video classification after our cropping, outperform 3D CNN performances for same-sized random-crop inputs, also surpassing some larger random-crop sizes.
Event and Activity Recognition in Video Surveillance for Cyber-Physical Systems
Nov 03, 2021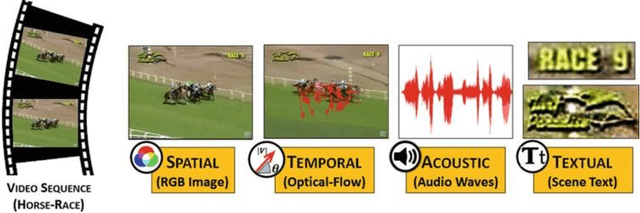
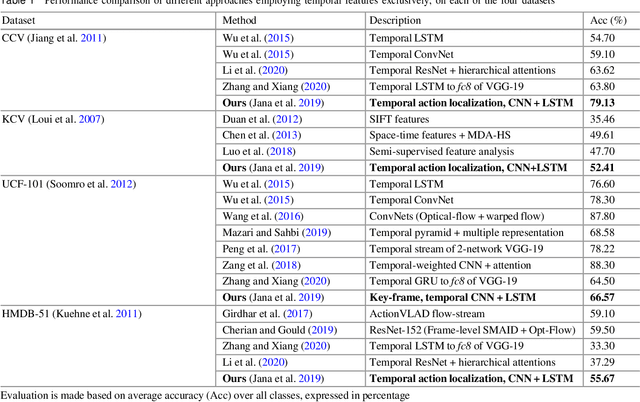

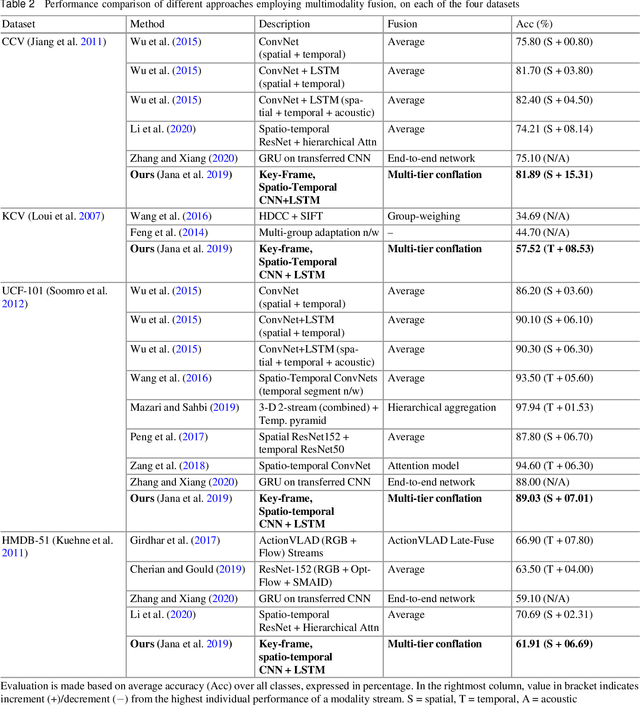
This chapter aims to aid the development of Cyber-Physical Systems (CPS) in automated understanding of events and activities in various applications of video-surveillance. These events are mostly captured by drones, CCTVs or novice and unskilled individuals on low-end devices. Being unconstrained, these videos are immensely challenging due to a number of quality factors. We present an extensive account of the various approaches taken to solve the problem over the years. This ranges from methods as early as Structure from Motion (SFM) based approaches to recent solution frameworks involving deep neural networks. We show that the long-term motion patterns alone play a pivotal role in the task of recognizing an event. Consequently each video is significantly represented by a fixed number of key-frames using a graph-based approach. Only the temporal features are exploited using a hybrid Convolutional Neural Network (CNN) + Recurrent Neural Network (RNN) architecture. The results we obtain are encouraging as they outperform standard temporal CNNs and are at par with those using spatial information along with motion cues. Further exploring multistream models, we conceive a multi-tier fusion strategy for the spatial and temporal wings of a network. A consolidated representation of the respective individual prediction vectors on video and frame levels is obtained using a biased conflation technique. The fusion strategy endows us with greater rise in precision on each stage as compared to the state-of-the-art methods, and thus a powerful consensus is achieved in classification. Results are recorded on four benchmark datasets widely used in the domain of action recognition, namely CCV, HMDB, UCF-101 and KCV. It is inferable that focusing on better classification of the video sequences certainly leads to robust actuation of a system designed for event surveillance and object cum activity tracking.
* This is a preprint of the chapter:S Bhaumik, P Jana, PP Mohanta, Event and Activity Recognition in Video Surveillance for Cyber-Physical Systems, published in Emergence of Cyber Physical System.., edited by KK Singh et al, 2021, Springer reproduced with permission of Springer Nature Switzerland AG. The final authenticated version is available online at http://dx.doi.org/10.1007/978-3-030-66222-6_4