 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAI: Evaluating TxAgent's Therapeutic Agentic Reasoning in the NeurIPS CURE-Bench Competition
Dec 12, 2025
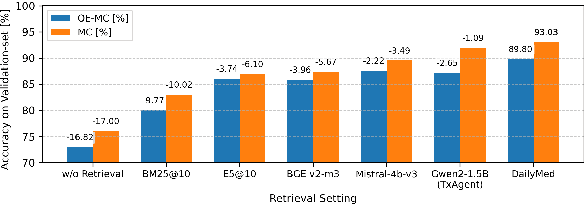
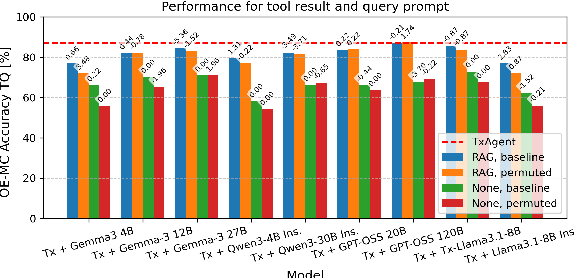
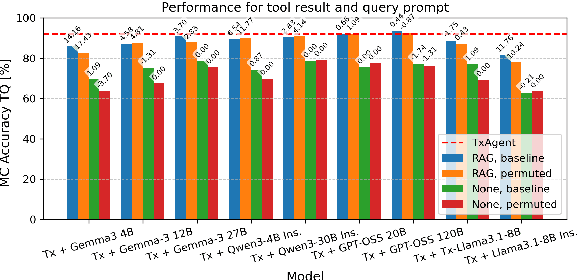
Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions among patient characteristics, disease processes, and pharmacological agents. Tasks such as drug recommendation, treatment planning, and adverse-effect prediction demand robust, multi-step reasoning grounded in reliable biomedical knowledge. Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG). TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse), integrating FDA Drug API, OpenTargets, and Monarch resources to ensure access to current therapeutic information. In contrast to general-purpose RAG systems, medical applications impose stringent safety constraints, rendering the accuracy of both the reasoning trace and the sequence of tool invocations critical. These considerations motivate evaluation protocols treating token-level reasoning and tool-usage behaviors as explicit supervision signals. This work presents insights derived from our participation in the CURE-Bench NeurIPS 2025 Challenge, which benchmarks therapeutic-reasoning systems using metrics that assess correctness, tool utilization, and reasoning quality. We analyze how retrieval quality for function (tool) calls influences overall model performance and demonstrate performance gains achieved through improved tool-retrieval strategies. Our work was awarded the Excellence Award in Open Science. Complete information can be found at https://curebench.ai/.
SCOOTER: A Human Evaluation Framework for Unrestricted Adversarial Examples
Jul 10, 2025Unrestricted adversarial attacks aim to fool computer vision models without being constrained by $\ell_p$-norm bounds to remain imperceptible to humans, for example, by changing an object's color. This allows attackers to circumvent traditional, norm-bounded defense strategies such as adversarial training or certified defense strategies. However, due to their unrestricted nature, there are also no guarantees of norm-based imperceptibility, necessitating human evaluations to verify just how authentic these adversarial examples look. While some related work assesses this vital quality of adversarial attacks, none provide statistically significant insights. This issue necessitates a unified framework that supports and streamlines such an assessment for evaluating and comparing unrestricted attacks. To close this gap, we introduce SCOOTER - an open-source, statistically powered framework for evaluating unrestricted adversarial examples. Our contributions are: $(i)$ best-practice guidelines for crowd-study power, compensation, and Likert equivalence bounds to measure imperceptibility; $(ii)$ the first large-scale human vs. model comparison across 346 human participants showing that three color-space attacks and three diffusion-based attacks fail to produce imperceptible images. Furthermore, we found that GPT-4o can serve as a preliminary test for imperceptibility, but it only consistently detects adversarial examples for four out of six tested attacks; $(iii)$ open-source software tools, including a browser-based task template to collect annotations and analysis scripts in Python and R; $(iv)$ an ImageNet-derived benchmark dataset containing 3K real images, 7K adversarial examples, and over 34K human ratings. Our findings demonstrate that automated vision systems do not align with human perception, reinforcing the need for a ground-truth SCOOTER benchmark.
How Real Is Real? A Human Evaluation Framework for Unrestricted Adversarial Examples
Apr 19, 2024


With an ever-increasing reliance on machine learning (ML) models in the real world, adversarial examples threaten the safety of AI-based systems such as autonomous vehicles. In the image domain, they represent maliciously perturbed data points that look benign to humans (i.e., the image modification is not noticeable) but greatly mislead state-of-the-art ML models. Previously, researchers ensured the imperceptibility of their altered data points by restricting perturbations via $\ell_p$ norms. However, recent publications claim that creating natural-looking adversarial examples without such restrictions is also possible. With much more freedom to instill malicious information into data, these unrestricted adversarial examples can potentially overcome traditional defense strategies as they are not constrained by the limitations or patterns these defenses typically recognize and mitigate. This allows attackers to operate outside of expected threat models. However, surveying existing image-based methods, we noticed a need for more human evaluations of the proposed image modifications. Based on existing human-assessment frameworks for image generation quality, we propose SCOOTER - an evaluation framework for unrestricted image-based attacks. It provides researchers with guidelines for conducting statistically significant human experiments, standardized questions, and a ready-to-use implementation. We propose a framework that allows researchers to analyze how imperceptible their unrestricted attacks truly are.
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023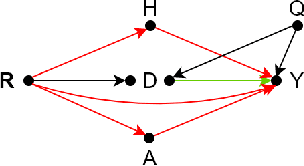
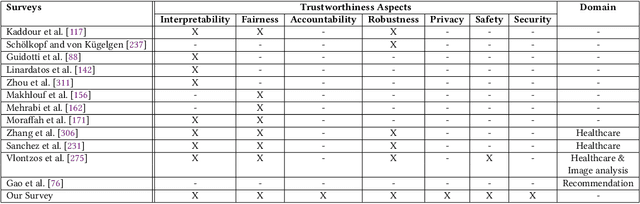
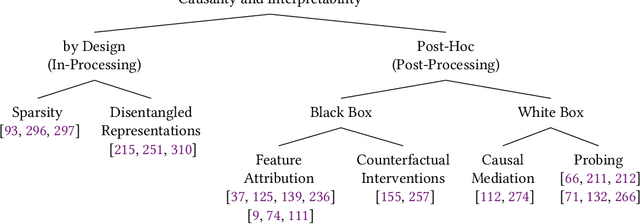
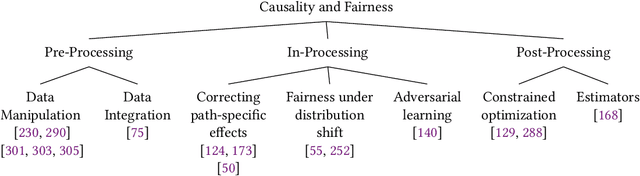
State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.