 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Enriched Natural Language Descriptions of Vessel Trajectories
Mar 08, 2026We address the problem of transforming raw vessel trajectory data collected from AIS into structured and semantically enriched representations interpretable by humans and directly usable by machine reasoning systems. We propose a context-aware trajectory abstraction framework that segments noisy AIS sequences into distinct trips each consisting of clean, mobility-annotated episodes. Each episode is further enriched with multi-source contextual information, such as nearby geographic entities, offshore navigation features, and weather conditions. Crucially, such representations can support generation of controlled natural language descriptions using LLMs. We empirically examine the quality of such descriptions generated using several LLMs over AIS data along with open contextual features. By increasing semantic density and reducing spatiotemporal complexity, this abstraction can facilitate downstream analytics and enable integration with LLMs for higher-level maritime reasoning tasks.
Data-Driven Trajectory Imputation for Vessel Mobility Analysis
Feb 12, 2026Modeling vessel activity at sea is critical for a wide range of applications, including route planning, transportation logistics, maritime safety, and environmental monitoring. Over the past two decades, the Automatic Identification System (AIS) has enabled real-time monitoring of hundreds of thousands of vessels, generating huge amounts of data daily. One major challenge in using AIS data is the presence of large gaps in vessel trajectories, often caused by coverage limitations or intentional transmission interruptions. These gaps can significantly degrade data quality, resulting in inaccurate or incomplete analysis. State-of-the-art imputation approaches have mainly been devised to tackle gaps in vehicle trajectories, even when the underlying road network is not considered. But the motion patterns of sailing vessels differ substantially, e.g., smooth turns, maneuvering near ports, or navigating in adverse weather conditions. In this application paper, we propose HABIT, a lightweight, configurable H3 Aggregation-Based Imputation framework for vessel Trajectories. This data-driven framework provides a valuable means to impute missing trajectory segments by extracting, analyzing, and indexing motion patterns from historical AIS data. Our empirical study over AIS data across various timeframes, densities, and vessel types reveals that HABIT produces maritime trajectory imputations performing comparably to baseline methods in terms of accuracy, while performing better in terms of latency while accounting for vessel characteristics and their motion patterns.
Hippasus: Effective and Efficient Automatic Feature Augmentation for Machine Learning Tasks on Relational Data
Feb 02, 2026Machine learning models depend critically on feature quality, yet useful features are often scattered across multiple relational tables. Feature augmentation enriches a base table by discovering and integrating features from related tables through join operations. However, scaling this process to complex schemas with many tables and multi-hop paths remains challenging. Feature augmentation must address three core tasks: identify promising join paths that connect the base table to candidate tables, execute these joins to materialize augmented data, and select the most informative features from the results. Existing approaches face a fundamental tradeoff between effectiveness and efficiency: achieving high accuracy requires exploring many candidate paths, but exhaustive exploration is computationally prohibitive. Some methods compromise by considering only immediate neighbors, limiting their effectiveness, while others employ neural models that require expensive training data and introduce scalability limitations. We present Hippasus, a modular framework that achieves both goals through three key contributions. First, we combine lightweight statistical signals with semantic reasoning from Large Language Models to prune unpromising join paths before execution, focusing computational resources on high-quality candidates. Second, we employ optimized multi-way join algorithms and consolidate features from multiple paths, substantially reducing execution time. Third, we integrate LLM-based semantic understanding with statistical measures to select features that are both semantically meaningful and empirically predictive. Our experimental evaluation on publicly available datasets shows that Hippasus substantially improves feature augmentation accuracy by up to 26.8% over state-of-the-art baselines while also offering high runtime performance.
MultiCast: Zero-Shot Multivariate Time Series Forecasting Using LLMs
May 23, 2024Predicting future values in multivariate time series is vital across various domains. This work explores the use of large language models (LLMs) for this task. However, LLMs typically handle one-dimensional data. We introduce MultiCast, a zero-shot LLM-based approach for multivariate time series forecasting. It allows LLMs to receive multivariate time series as input, through three novel token multiplexing solutions that effectively reduce dimensionality while preserving key repetitive patterns. Additionally, a quantization scheme helps LLMs to better learn these patterns, while significantly reducing token use for practical applications. We showcase the performance of our approach in terms of RMSE and execution time against state-of-the-art approaches on three real-world datasets.
Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]
Apr 24, 2023![Figure 1 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F3-Table1-1.png&w=640&q=75)
![Figure 2 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F6-Figure1-1.png&w=640&q=75)
![Figure 3 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for Pre-trained Embeddings for Entity Resolution: An Experimental Analysis [Experiment, Analysis & Benchmark]](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F91317e9bf86ea710fcdbfb3dbb8d1c19c5602182%2F7-Figure2-1.png&w=640&q=75)
Many recent works on Entity Resolution (ER) leverage Deep Learning techniques involving language models to improve effectiveness. This is applied to both main steps of ER, i.e., blocking and matching. Several pre-trained embeddings have been tested, with the most popular ones being fastText and variants of the BERT model. However, there is no detailed analysis of their pros and cons. To cover this gap, we perform a thorough experimental analysis of 12 popular language models over 17 established benchmark datasets. First, we assess their vectorization overhead for converting all input entities into dense embeddings vectors. Second, we investigate their blocking performance, performing a detailed scalability analysis, and comparing them with the state-of-the-art deep learning-based blocking method. Third, we conclude with their relative performance for both supervised and unsupervised matching. Our experimental results provide novel insights into the strengths and weaknesses of the main language models, facilitating researchers and practitioners to select the most suitable ones in practice.
ATRAPOS: Evaluating Metapath Query Workloads in Real Time
Jan 11, 2022



Heterogeneous information networks (HINs) represent different types of entities and relationships between them. Exploring, analysing, and extracting knowledge from such networks relies on metapath queries that identify pairs of entities connected by relationships of diverse semantics. While the real-time evaluation of metapath query workloads on large, web-scale HINs is highly demanding in computational cost, current approaches do not exploit interrelationships among the queries. In this paper, we present ATRAPOS, a new approach for the real-time evaluation of metapath query workloads that leverages a combination of efficient sparse matrix multiplication and intermediate result caching. ATRAPOS selects intermediate results to cache and reuse by detecting frequent sub-metapaths among workload queries in real time, using a tailor-made data structure, the Overlap Tree, and an associated caching policy. Our experimental study on real data shows that ATRAPOS accelerates exploratory data analysis and mining on HINs, outperforming off-the-shelf caching approaches and state-of-the-art research prototypes in all examined scenarios.
INODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
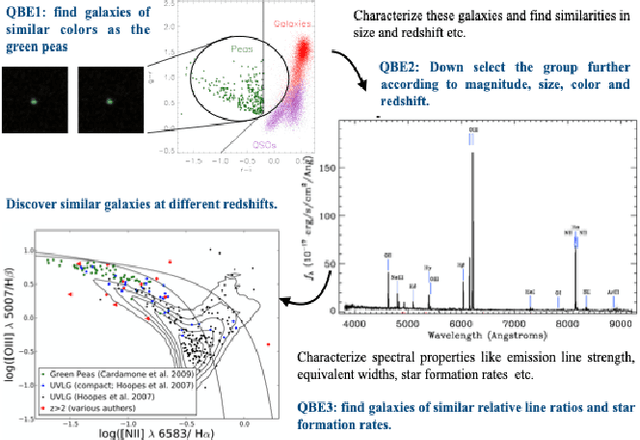
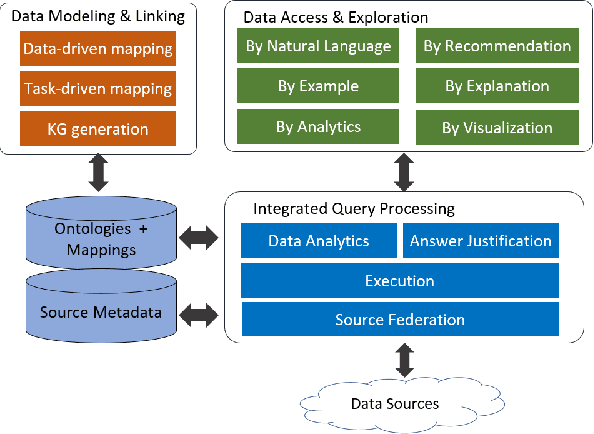

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.