 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanorama: Fast-Track Nearest Neighbors
Oct 01, 2025Approximate Nearest-Neighbor Search (ANNS) efficiently finds data items whose embeddings are close to that of a given query in a high-dimensional space, aiming to balance accuracy with speed. Used in recommendation systems, image and video retrieval, natural language processing, and retrieval-augmented generation (RAG), ANNS algorithms such as IVFPQ, HNSW graphs, Annoy, and MRPT utilize graph, tree, clustering, and quantization techniques to navigate large vector spaces. Despite this progress, ANNS systems spend up to 99\% of query time to compute distances in their final refinement phase. In this paper, we present PANORAMA, a machine learning-driven approach that tackles the ANNS verification bottleneck through data-adaptive learned orthogonal transforms that facilitate the accretive refinement of distance bounds. Such transforms compact over 90\% of signal energy into the first half of dimensions, enabling early candidate pruning with partial distance computations. We integrate PANORAMA into state-of-the-art ANNS methods, namely IVFPQ/Flat, HNSW, MRPT, and Annoy, without index modification, using level-major memory layouts, SIMD-vectorized partial distance computations, and cache-aware access patterns. Experiments across diverse datasets -- from image-based CIFAR-10 and GIST to modern embedding spaces including OpenAI's Ada 2 and Large 3 -- demonstrate that PANORAMA affords a 2--30$\times$ end-to-end speedup with no recall loss.
Highly Efficient Direct Analytics on Semantic-aware Time Series Data Compression
Mar 17, 2025



Semantic communication has emerged as a promising paradigm to tackle the challenges of massive growing data traffic and sustainable data communication. It shifts the focus from data fidelity to goal-oriented or task-oriented semantic transmission. While deep learning-based methods are commonly used for semantic encoding and decoding, they struggle with the sequential nature of time series data and high computation cost, particularly in resource-constrained IoT environments. Data compression plays a crucial role in reducing transmission and storage costs, yet traditional data compression methods fall short of the demands of goal-oriented communication systems. In this paper, we propose a novel method for direct analytics on time series data compressed by the SHRINK compression algorithm. Through experimentation using outlier detection as a case study, we show that our method outperforms baselines running on uncompressed data in multiple cases, with merely 1% difference in the worst case. Additionally, it achieves four times lower runtime on average and accesses approximately 10% of the data volume, which enables edge analytics with limited storage and computation power. These results demonstrate that our approach offers reliable, high-speed outlier detection analytics for diverse IoT applications while extracting semantics from time-series data, achieving high compression, and reducing data transmission.
Mining Path Association Rules in Large Property Graphs (with Appendix)
Aug 04, 2024How can we mine frequent path regularities from a graph with edge labels and vertex attributes? The task of association rule mining successfully discovers regular patterns in item sets and substructures. Still, to our best knowledge, this concept has not yet been extended to path patterns in large property graphs. In this paper, we introduce the problem of path association rule mining (PARM). Applied to any \emph{reachability path} between two vertices within a large graph, PARM discovers regular ways in which path patterns, identified by vertex attributes and edge labels, co-occur with each other. We develop an efficient and scalable algorithm PIONEER that exploits an anti-monotonicity property to effectively prune the search space. Further, we devise approximation techniques and employ parallelization to achieve scalable path association rule mining. Our experimental study using real-world graph data verifies the significance of path association rules and the efficiency of our solutions.
An autoencoder for compressing angle-resolved photoemission spectroscopy data
Jul 05, 2024Angle-resolved photoemission spectroscopy (ARPES) is a powerful experimental technique to determine the electronic structure of solids. Advances in light sources for ARPES experiments are currently leading to a vast increase of data acquisition rates and data quantity. On the other hand, access time to the most advanced ARPES instruments remains strictly limited, calling for fast, effective, and on-the-fly data analysis tools to exploit this time. In response to this need, we introduce ARPESNet, a versatile autoencoder network that efficiently summmarises and compresses ARPES datasets. We train ARPESNet on a large and varied dataset of 2-dimensional ARPES data extracted by cutting standard 3-dimensional ARPES datasets along random directions in $\mathbf{k}$. To test the data representation capacity of ARPESNet, we compare $k$-means clustering quality between data compressed by ARPESNet, data compressed by discrete cosine transform, and raw data, at different noise levels. ARPESNet data excels in clustering quality despite its high compression ratio.
EUGENE: Explainable Unsupervised Approximation of Graph Edit Distance
Feb 08, 2024The need to identify graphs having small structural distance from a query arises in biology, chemistry, recommender systems, and social network analysis. Among several methods to measure inter graph distance, Graph Edit Distance (GED) is preferred for its comprehensibility, yet hindered by the NP-hardness of its computation. State-of-the-art GED approximations predominantly employ neural methods, which, however, (i) lack an explanatory edit path corresponding to the approximated GED; (ii) require the NP-hard generation of ground-truth GEDs for training; and (iii) necessitate separate training on each dataset. In this paper, we propose an efficient algebraic unsuper vised method, EUGENE, that approximates GED and yields edit paths corresponding to the approx imated cost, while eliminating the need for ground truth generation and data-specific training. Extensive experimental evaluation demonstrates that the aforementioned benefits of EUGENE do not come at the cost of efficacy. Specifically, EUGENE consistently ranks among the most accurate methods across all of the benchmark datasets and outperforms majority of the neural approaches.
Data-driven prediction of tool wear using Bayesian-regularized artificial neural networks
Nov 30, 2023The prediction of tool wear helps minimize costs and enhance product quality in manufacturing. While existing data-driven models using machine learning and deep learning have contributed to the accurate prediction of tool wear, they often lack generality and require substantial training data for high accuracy. In this paper, we propose a new data-driven model that uses Bayesian Regularized Artificial Neural Networks (BRANNs) to precisely predict milling tool wear. BRANNs combine the strengths and leverage the benefits of artificial neural networks (ANNs) and Bayesian regularization, whereby ANNs learn complex patterns and Bayesian regularization handles uncertainty and prevents overfitting, resulting in a more generalized model. We treat both process parameters and monitoring sensor signals as BRANN input parameters. We conducted an extensive experimental study featuring four different experimental data sets, including the NASA Ames milling dataset, the 2010 PHM Data Challenge dataset, the NUAA Ideahouse tool wear dataset, and an in-house performed end-milling of the Ti6Al4V dataset. We inspect the impact of input features, training data size, hidden units, training algorithms, and transfer functions on the performance of the proposed BRANN model and demonstrate that it outperforms existing state-of-the-art models in terms of accuracy and reliability.
MCWDST: a Minimum-Cost Weighted Directed Spanning Tree Algorithm for Real-Time Fake News Mitigation in Social Media
Feb 23, 2023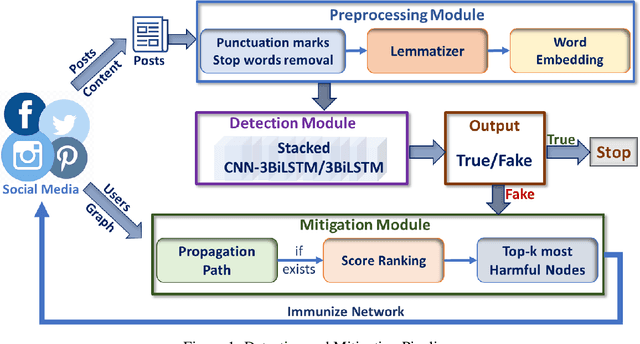



The widespread availability of internet access and handheld devices confers to social media a power similar to the one newspapers used to have. People seek affordable information on social media and can reach it within seconds. Yet this convenience comes with dangers; any user may freely post whatever they please and the content can stay online for a long period, regardless of its truthfulness. A need to detect untruthful information, also known as fake news, arises. In this paper, we present an end-to-end solution that accurately detects fake news and immunizes network nodes that spread them in real-time. To detect fake news, we propose two new stack deep learning architectures that utilize convolutional and bidirectional LSTM layers. To mitigate the spread of fake news, we propose a real-time network-aware strategy that (1) constructs a minimum-cost weighted directed spanning tree for a detected node, and (2) immunizes nodes in that tree by scoring their harmfulness using a novel ranking function. We demonstrate the effectiveness of our solution on five real-world datasets.
DANES: Deep Neural Network Ensemble Architecture for Social and Textual Context-aware Fake News Detection
Feb 01, 2023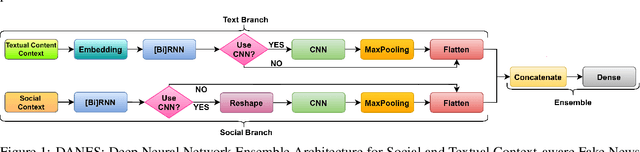

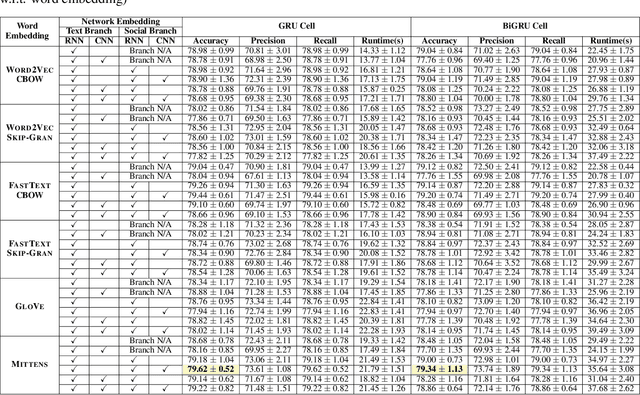

The growing popularity of social media platforms has simplified the creation and distribution of news articles but also creates a conduit for spreading fake news. In consequence, the need arises for effective context-aware fake news detection mechanisms, where the contextual information can be built either from the textual content of posts or from available social data (e.g., information about the users, reactions to posts, or the social network). In this paper, we propose DANES, a Deep Neural Network Ensemble Architecture for Social and Textual Context-aware Fake News Detection. DANES comprises a Text Branch for a textual content-based context and a Social Branch for the social context. These two branches are used to create a novel Network Embedding. Preliminary ablation results on 3 real-world datasets, i.e., BuzzFace, Twitter15, and Twitter16, are promising, with an accuracy that outperforms state-of-the-art solutions when employing both social and textual content features.
ATRAPOS: Evaluating Metapath Query Workloads in Real Time
Jan 11, 2022Heterogeneous information networks (HINs) represent different types of entities and relationships between them. Exploring, analysing, and extracting knowledge from such networks relies on metapath queries that identify pairs of entities connected by relationships of diverse semantics. While the real-time evaluation of metapath query workloads on large, web-scale HINs is highly demanding in computational cost, current approaches do not exploit interrelationships among the queries. In this paper, we present ATRAPOS, a new approach for the real-time evaluation of metapath query workloads that leverages a combination of efficient sparse matrix multiplication and intermediate result caching. ATRAPOS selects intermediate results to cache and reuse by detecting frequent sub-metapaths among workload queries in real time, using a tailor-made data structure, the Overlap Tree, and an associated caching policy. Our experimental study on real data shows that ATRAPOS accelerates exploratory data analysis and mining on HINs, outperforming off-the-shelf caching approaches and state-of-the-art research prototypes in all examined scenarios.
GRASP: Graph Alignment through Spectral Signatures
Jun 11, 2021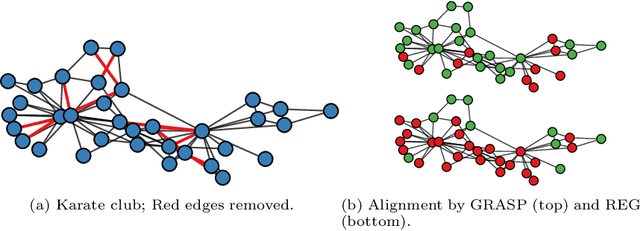

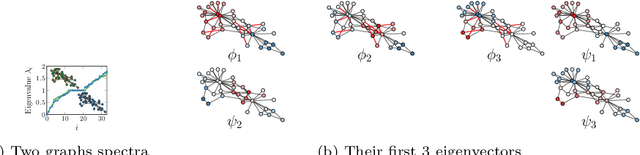
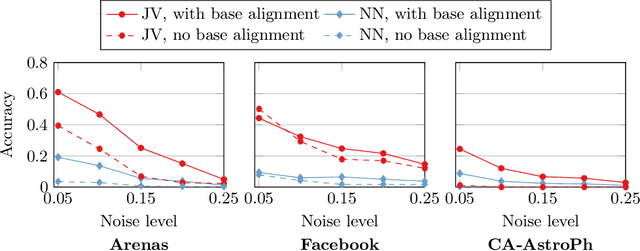
What is the best way to match the nodes of two graphs? This graph alignment problem generalizes graph isomorphism and arises in applications from social network analysis to bioinformatics. Some solutions assume that auxiliary information on known matches or node or edge attributes is available, or utilize arbitrary graph features. Such methods fare poorly in the pure form of the problem, in which only graph structures are given. Other proposals translate the problem to one of aligning node embeddings, yet, by doing so, provide only a single-scale view of the graph. In this paper, we transfer the shape-analysis concept of functional maps from the continuous to the discrete case, and treat the graph alignment problem as a special case of the problem of finding a mapping between functions on graphs. We present GRASP, a method that first establishes a correspondence between functions derived from Laplacian matrix eigenvectors, which capture multiscale structural characteristics, and then exploits this correspondence to align nodes. Our experimental study, featuring noise levels higher than anything used in previous studies, shows that GRASP outperforms state-of-the-art methods for graph alignment across noise levels and graph types.