 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Scientific Discovery with Multi-Document Summarization of Impact-Ranked Papers
Aug 05, 2025The growing volume of scientific literature makes it challenging for scientists to move from a list of papers to a synthesized understanding of a topic. Because of the constant influx of new papers on a daily basis, even if a scientist identifies a promising set of papers, they still face the tedious task of individually reading through dozens of titles and abstracts to make sense of occasionally conflicting findings. To address this critical bottleneck in the research workflow, we introduce a summarization feature to BIP! Finder, a scholarly search engine that ranks literature based on distinct impact aspects like popularity and influence. Our approach enables users to generate two types of summaries from top-ranked search results: a concise summary for an instantaneous at-a-glance comprehension and a more comprehensive literature review-style summary for greater, better-organized comprehension. This ability dynamically leverages BIP! Finder's already existing impact-based ranking and filtering features to generate context-sensitive, synthesized narratives that can significantly accelerate literature discovery and comprehension.
Open and Sustainable AI: challenges, opportunities and the road ahead in the life sciences
May 22, 2025Artificial intelligence (AI) has recently seen transformative breakthroughs in the life sciences, expanding possibilities for researchers to interpret biological information at an unprecedented capacity, with novel applications and advances being made almost daily. In order to maximise return on the growing investments in AI-based life science research and accelerate this progress, it has become urgent to address the exacerbation of long-standing research challenges arising from the rapid adoption of AI methods. We review the increased erosion of trust in AI research outputs, driven by the issues of poor reusability and reproducibility, and highlight their consequent impact on environmental sustainability. Furthermore, we discuss the fragmented components of the AI ecosystem and lack of guiding pathways to best support Open and Sustainable AI (OSAI) model development. In response, this perspective introduces a practical set of OSAI recommendations directly mapped to over 300 components of the AI ecosystem. Our work connects researchers with relevant AI resources, facilitating the implementation of sustainable, reusable and transparent AI. Built upon life science community consensus and aligned to existing efforts, the outputs of this perspective are designed to aid the future development of policy and structured pathways for guiding AI implementation.
From raw affiliations to organization identifiers
May 13, 2025Accurate affiliation matching, which links affiliation strings to standardized organization identifiers, is critical for improving research metadata quality, facilitating comprehensive bibliometric analyses, and supporting data interoperability across scholarly knowledge bases. Existing approaches fail to handle the complexity of affiliation strings that often include mentions of multiple organizations or extraneous information. In this paper, we present AffRo, a novel approach designed to address these challenges, leveraging advanced parsing and disambiguation techniques. We also introduce AffRoDB, an expert-curated dataset to systematically evaluate affiliation matching algorithms, ensuring robust benchmarking. Results demonstrate the effectiveness of AffRp in accurately identifying organizations from complex affiliation strings.
Can LLMs Predict Citation Intent? An Experimental Analysis of In-context Learning and Fine-tuning on Open LLMs
Feb 20, 2025This work investigates the ability of open Large Language Models (LLMs) to predict citation intent through in-context learning and fine-tuning. Unlike traditional approaches that rely on pre-trained models like SciBERT, which require extensive domain-specific pretraining and specialized architectures, we demonstrate that general-purpose LLMs can be adapted to this task with minimal task-specific data. We evaluate twelve model variations across five prominent open LLM families using zero, one, few, and many-shot prompting to assess performance across scenarios. Our experimental study identifies the top-performing model through extensive experimentation of in-context learning-related parameters, which we fine-tune to further enhance task performance. The results highlight the strengths and limitations of LLMs in recognizing citation intents, providing valuable insights for model selection and prompt engineering. Additionally, we make our end-to-end evaluation framework and models openly available for future use.
Piloting topic-aware research impact assessment features in BIP! Services
May 10, 2023Various research activities rely on citation-based impact indicators. However these indicators are usually globally computed, hindering their proper interpretation in applications like research assessment and knowledge discovery. In this work, we advocate for the use of topic-aware categorical impact indicators, to alleviate the aforementioned problem. In addition, we extend BIP! Services to support those indicators and showcase their benefits in real-world research activities.
BIP! Scholar: A Service to Facilitate Fair Researcher Assessment
May 06, 2022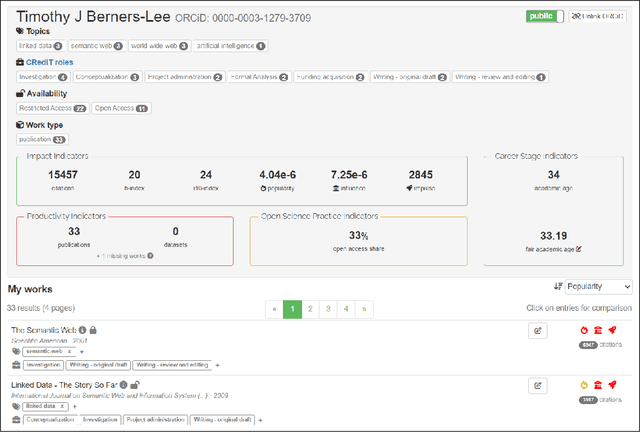

In recent years, assessing the performance of researchers has become a burden due to the extensive volume of the existing research output. As a result, evaluators often end up relying heavily on a selection of performance indicators like the h-index. However, over-reliance on such indicators may result in reinforcing dubious research practices, while overlooking important aspects of a researcher's career, such as their exact role in the production of particular research works or their contribution to other important types of academic or research activities (e.g., production of datasets, peer reviewing). In response, a number of initiatives that attempt to provide guidelines towards fairer research assessment frameworks have been established. In this work, we present BIP! Scholar, a Web-based service that offers researchers the opportunity to set up profiles that summarise their research careers taking into consideration well-established guidelines for fair research assessment, facilitating the work of evaluators who want to be more compliant with the respective practices.
ATRAPOS: Evaluating Metapath Query Workloads in Real Time
Jan 11, 2022Heterogeneous information networks (HINs) represent different types of entities and relationships between them. Exploring, analysing, and extracting knowledge from such networks relies on metapath queries that identify pairs of entities connected by relationships of diverse semantics. While the real-time evaluation of metapath query workloads on large, web-scale HINs is highly demanding in computational cost, current approaches do not exploit interrelationships among the queries. In this paper, we present ATRAPOS, a new approach for the real-time evaluation of metapath query workloads that leverages a combination of efficient sparse matrix multiplication and intermediate result caching. ATRAPOS selects intermediate results to cache and reuse by detecting frequent sub-metapaths among workload queries in real time, using a tailor-made data structure, the Overlap Tree, and an associated caching policy. Our experimental study on real data shows that ATRAPOS accelerates exploratory data analysis and mining on HINs, outperforming off-the-shelf caching approaches and state-of-the-art research prototypes in all examined scenarios.
BIP! DB: A Dataset of Impact Measures for Scientific Publications
Jan 28, 2021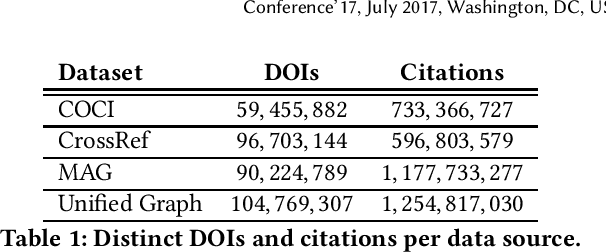
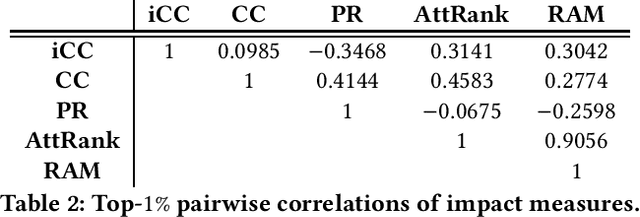
The growth rate of the number of scientific publications is constantly increasing, creating important challenges in the identification of valuable research and in various scholarly data management applications, in general. In this context, measures which can effectively quantify the scientific impact could be invaluable. In this work, we present BIP! DB, an open dataset that contains a variety of impact measures calculated for a large collection of more than 100 million scientific publications from various disciplines.
Simplifying Impact Prediction for Scientific Articles
Dec 30, 2020



Estimating the expected impact of an article is valuable for various applications (e.g., article/cooperator recommendation). Most existing approaches attempt to predict the exact number of citations each article will receive in the near future, however this is a difficult regression analysis problem. Moreover, most approaches rely on the existence of rich metadata for each article, a requirement that cannot be adequately fulfilled for a large number of them. In this work, we take advantage of the fact that solving a simpler machine learning problem, that of classifying articles based on their expected impact, is adequate for many real world applications and we propose a simplified model that can be trained using minimal article metadata. Finally, we examine various configurations of this model and evaluate their effectiveness in solving the aforementioned classification problem.