 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability-by-Design with Accurate Locally Additive Models and Conditional Feature Effects
Feb 18, 2026Generalized additive models (GAMs) offer interpretability through independent univariate feature effects but underfit when interactions are present in data. GA$^2$Ms add selected pairwise interactions which improves accuracy, but sacrifices interpretability and limits model auditing. We propose \emph{Conditionally Additive Local Models} (CALMs), a new model class, that balances the interpretability of GAMs with the accuracy of GA$^2$Ms. CALMs allow multiple univariate shape functions per feature, each active in different regions of the input space. These regions are defined independently for each feature as simple logical conditions (thresholds) on the features it interacts with. As a result, effects remain locally additive while varying across subregions to capture interactions. We further propose a principled distillation-based training pipeline that identifies homogeneous regions with limited interactions and fits interpretable shape functions via region-aware backfitting. Experiments on diverse classification and regression tasks show that CALMs consistently outperform GAMs and achieve accuracy comparable with GA$^2$Ms. Overall, CALMs offer a compelling trade-off between predictive accuracy and interpretability.
Effector: A Python package for regional explanations
Apr 03, 2024Global feature effect methods explain a model outputting one plot per feature. The plot shows the average effect of the feature on the output, like the effect of age on the annual income. However, average effects may be misleading when derived from local effects that are heterogeneous, i.e., they significantly deviate from the average. To decrease the heterogeneity, regional effects provide multiple plots per feature, each representing the average effect within a specific subspace. For interpretability, subspaces are defined as hyperrectangles defined by a chain of logical rules, like age's effect on annual income separately for males and females and different levels of professional experience. We introduce Effector, a Python library dedicated to regional feature effects. Effector implements well-established global effect methods, assesses the heterogeneity of each method and, based on that, provides regional effects. Effector automatically detects subspaces where regional effects have reduced heterogeneity. All global and regional effect methods share a common API, facilitating comparisons between them. Moreover, the library's interface is extensible so new methods can be easily added and benchmarked. The library has been thoroughly tested, ships with many tutorials (https://xai-effector.github.io/) and is available under an open-source license at PyPi (https://pypi.org/project/effector/) and Github (https://github.com/givasile/effector).
Regionally Additive Models: Explainable-by-design models minimizing feature interactions
Sep 21, 2023



Generalized Additive Models (GAMs) are widely used explainable-by-design models in various applications. GAMs assume that the output can be represented as a sum of univariate functions, referred to as components. However, this assumption fails in ML problems where the output depends on multiple features simultaneously. In these cases, GAMs fail to capture the interaction terms of the underlying function, leading to subpar accuracy. To (partially) address this issue, we propose Regionally Additive Models (RAMs), a novel class of explainable-by-design models. RAMs identify subregions within the feature space where interactions are minimized. Within these regions, it is more accurate to express the output as a sum of univariate functions (components). Consequently, RAMs fit one component per subregion of each feature instead of one component per feature. This approach yields a more expressive model compared to GAMs while retaining interpretability. The RAM framework consists of three steps. Firstly, we train a black-box model. Secondly, using Regional Effect Plots, we identify subregions where the black-box model exhibits near-local additivity. Lastly, we fit a GAM component for each identified subregion. We validate the effectiveness of RAMs through experiments on both synthetic and real-world datasets. The results confirm that RAMs offer improved expressiveness compared to GAMs while maintaining interpretability.
RHALE: Robust and Heterogeneity-aware Accumulated Local Effects
Sep 20, 2023



Accumulated Local Effects (ALE) is a widely-used explainability method for isolating the average effect of a feature on the output, because it handles cases with correlated features well. However, it has two limitations. First, it does not quantify the deviation of instance-level (local) effects from the average (global) effect, known as heterogeneity. Second, for estimating the average effect, it partitions the feature domain into user-defined, fixed-sized bins, where different bin sizes may lead to inconsistent ALE estimations. To address these limitations, we propose Robust and Heterogeneity-aware ALE (RHALE). RHALE quantifies the heterogeneity by considering the standard deviation of the local effects and automatically determines an optimal variable-size bin-splitting. In this paper, we prove that to achieve an unbiased approximation of the standard deviation of local effects within each bin, bin splitting must follow a set of sufficient conditions. Based on these conditions, we propose an algorithm that automatically determines the optimal partitioning, balancing the estimation bias and variance. Through evaluations on synthetic and real datasets, we demonstrate the superiority of RHALE compared to other methods, including the advantages of automatic bin splitting, especially in cases with correlated features.
DALE: Differential Accumulated Local Effects for efficient and accurate global explanations
Oct 10, 2022

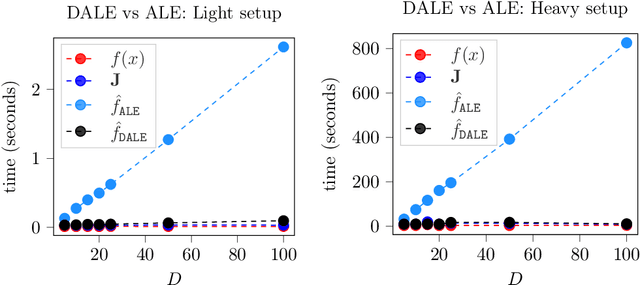

Accumulated Local Effect (ALE) is a method for accurately estimating feature effects, overcoming fundamental failure modes of previously-existed methods, such as Partial Dependence Plots. However, ALE's approximation, i.e. the method for estimating ALE from the limited samples of the training set, faces two weaknesses. First, it does not scale well in cases where the input has high dimensionality, and, second, it is vulnerable to out-of-distribution (OOD) sampling when the training set is relatively small. In this paper, we propose a novel ALE approximation, called Differential Accumulated Local Effects (DALE), which can be used in cases where the ML model is differentiable and an auto-differentiable framework is accessible. Our proposal has significant computational advantages, making feature effect estimation applicable to high-dimensional Machine Learning scenarios with near-zero computational overhead. Furthermore, DALE does not create artificial points for calculating the feature effect, resolving misleading estimations due to OOD sampling. Finally, we formally prove that, under some hypotheses, DALE is an unbiased estimator of ALE and we present a method for quantifying the standard error of the explanation. Experiments using both synthetic and real datasets demonstrate the value of the proposed approach.
ATRAPOS: Evaluating Metapath Query Workloads in Real Time
Jan 11, 2022



Heterogeneous information networks (HINs) represent different types of entities and relationships between them. Exploring, analysing, and extracting knowledge from such networks relies on metapath queries that identify pairs of entities connected by relationships of diverse semantics. While the real-time evaluation of metapath query workloads on large, web-scale HINs is highly demanding in computational cost, current approaches do not exploit interrelationships among the queries. In this paper, we present ATRAPOS, a new approach for the real-time evaluation of metapath query workloads that leverages a combination of efficient sparse matrix multiplication and intermediate result caching. ATRAPOS selects intermediate results to cache and reuse by detecting frequent sub-metapaths among workload queries in real time, using a tailor-made data structure, the Overlap Tree, and an associated caching policy. Our experimental study on real data shows that ATRAPOS accelerates exploratory data analysis and mining on HINs, outperforming off-the-shelf caching approaches and state-of-the-art research prototypes in all examined scenarios.
Simplifying Impact Prediction for Scientific Articles
Dec 30, 2020



Estimating the expected impact of an article is valuable for various applications (e.g., article/cooperator recommendation). Most existing approaches attempt to predict the exact number of citations each article will receive in the near future, however this is a difficult regression analysis problem. Moreover, most approaches rely on the existence of rich metadata for each article, a requirement that cannot be adequately fulfilled for a large number of them. In this work, we take advantage of the fact that solving a simpler machine learning problem, that of classifying articles based on their expected impact, is adequate for many real world applications and we propose a simplified model that can be trained using minimal article metadata. Finally, we examine various configurations of this model and evaluate their effectiveness in solving the aforementioned classification problem.