 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Vision Transformers for Distortion-Robust Representation Learning
Apr 24, 2026Self-supervised learning has achieved remarkable success in learning visual representations from clean data, yet remains challenging when clean observations are sparse or not available at all. In this paper, we demonstrate that pretrained vision models can be leveraged to learn distortion-robust representations, which can then be effectively applied to downstream tasks operating on distorted observations. In particular, we propose an asymmetric knowledge distillation framework in which both teacher and student are initialized from the same pretrained Vision Transformer but receive different views of each image: the teacher processes clean images, while the student sees their distorted versions. We introduce multi-level distillation that aligns global embeddings, patch-level features, and attention maps and show that the student is able to approximate clean-image representations despite never directly accessing clean data. We evaluate our approach on image classification tasks across several datasets and under various distortions, consistently outperforming existing alternatives for the same amount of human supervision.
HighFM: Towards a Foundation Model for Learning Representations from High-Frequency Earth Observation Data
Apr 05, 2026The increasing frequency and severity of climate related disasters have intensified the need for real time monitoring, early warning, and informed decision-making. Earth Observation (EO), powered by satellite data and Machine Learning (ML), offers powerful tools to meet these challenges. Foundation Models (FMs) have revolutionized EO ML by enabling general-purpose pretraining on large scale remote sensing datasets. However most existing models rely on high-resolution satellite imagery with low revisit rates limiting their suitability for fast-evolving phenomena and time critical emergency response. In this work, we present HighFM, a first cut approach towards a FM for high temporal resolution, multispectral EO data. Leveraging over 2 TB of SEVIRI imagery from the Meteosat Second Generation (MSG) platform, we adapt the SatMAE masked autoencoding framework to learn robust spatiotemporal representations. To support real time monitoring, we enhance the original architecture with fine grained temporal encodings to capture short term variability. The pretrained models are then finetuned on cloud masking and active fire detection tasks. We benchmark our SEVIRI pretrained Vision Transformers against traditional baselines and recent geospatial FMs, demonstrating consistent gains across both balanced accuracy and IoU metrics. Our results highlight the potential of temporally dense geostationary data for real-time EO, offering a scalable path toward foundation models for disaster detection and tracking.
GLANCE: Global Actions in a Nutshell for Counterfactual Explainability
May 29, 2024



Counterfactual explanations have emerged as an important tool to understand, debug, and audit complex machine learning models. To offer global counterfactual explainability, state-of-the-art methods construct summaries of local explanations, offering a trade-off among conciseness, counterfactual effectiveness, and counterfactual cost or burden imposed on instances. In this work, we provide a concise formulation of the problem of identifying global counterfactuals and establish principled criteria for comparing solutions, drawing inspiration from Pareto dominance. We introduce innovative algorithms designed to address the challenge of finding global counterfactuals for either the entire input space or specific partitions, employing clustering and decision trees as key components. Additionally, we conduct a comprehensive experimental evaluation, considering various instances of the problem and comparing our proposed algorithms with state-of-the-art methods. The results highlight the consistent capability of our algorithms to generate meaningful and interpretable global counterfactual explanations.
FALE: Fairness-Aware ALE Plots for Auditing Bias in Subgroups
Apr 29, 2024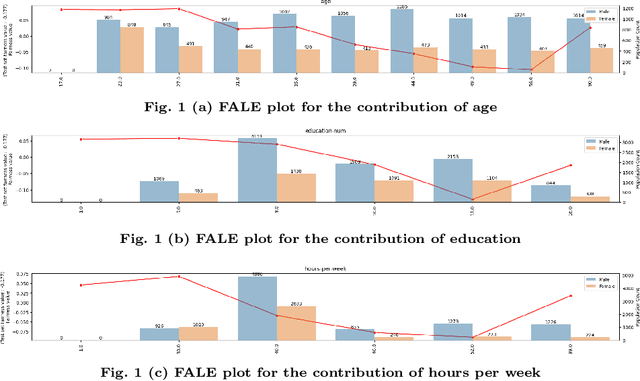
Fairness is steadily becoming a crucial requirement of Machine Learning (ML) systems. A particularly important notion is subgroup fairness, i.e., fairness in subgroups of individuals that are defined by more than one attributes. Identifying bias in subgroups can become both computationally challenging, as well as problematic with respect to comprehensibility and intuitiveness of the finding to end users. In this work we focus on the latter aspects; we propose an explainability method tailored to identifying potential bias in subgroups and visualizing the findings in a user friendly manner to end users. In particular, we extend the ALE plots explainability method, proposing FALE (Fairness aware Accumulated Local Effects) plots, a method for measuring the change in fairness for an affected population corresponding to different values of a feature (attribute). We envision FALE to function as an efficient, user friendly, comprehensible and reliable first-stage tool for identifying subgroups with potential bias issues.
Next day fire prediction via semantic segmentation
Mar 20, 2024



In this paper we present a deep learning pipeline for next day fire prediction. The next day fire prediction task consists in learning models that receive as input the available information for an area up until a certain day, in order to predict the occurrence of fire for the next day. Starting from our previous problem formulation as a binary classification task on instances (daily snapshots of each area) represented by tabular feature vectors, we reformulate the problem as a semantic segmentation task on images; there, each pixel corresponds to a daily snapshot of an area, while its channels represent the formerly tabular training features. We demonstrate that this problem formulation, built within a thorough pipeline achieves state of the art results.
Fairness Aware Counterfactuals for Subgroups
Jun 26, 2023
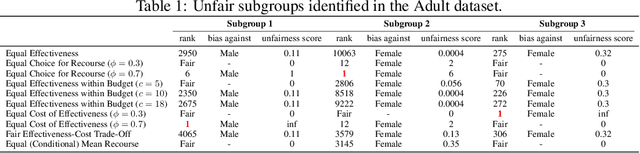

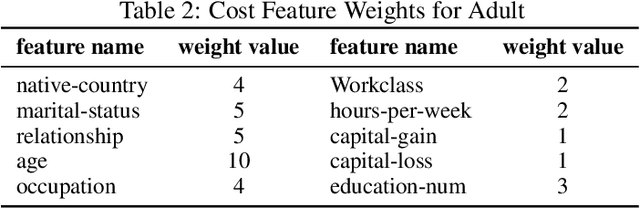
In this work, we present Fairness Aware Counterfactuals for Subgroups (FACTS), a framework for auditing subgroup fairness through counterfactual explanations. We start with revisiting (and generalizing) existing notions and introducing new, more refined notions of subgroup fairness. We aim to (a) formulate different aspects of the difficulty of individuals in certain subgroups to achieve recourse, i.e. receive the desired outcome, either at the micro level, considering members of the subgroup individually, or at the macro level, considering the subgroup as a whole, and (b) introduce notions of subgroup fairness that are robust, if not totally oblivious, to the cost of achieving recourse. We accompany these notions with an efficient, model-agnostic, highly parameterizable, and explainable framework for evaluating subgroup fairness. We demonstrate the advantages, the wide applicability, and the efficiency of our approach through a thorough experimental evaluation of different benchmark datasets.
Auditing for Spatial Fairness
Feb 23, 2023



This paper studies algorithmic fairness when the protected attribute is location. To handle protected attributes that are continuous, such as age or income, the standard approach is to discretize the domain into predefined groups, and compare algorithmic outcomes across groups. However, applying this idea to location raises concerns of gerrymandering and may introduce statistical bias. Prior work addresses these concerns but only for regularly spaced locations, while raising other issues, most notably its inability to discern regions that are likely to exhibit spatial unfairness. Similar to established notions of algorithmic fairness, we define spatial fairness as the statistical independence of outcomes from location. This translates into requiring that for each region of space, the distribution of outcomes is identical inside and outside the region. To allow for localized discrepancies in the distribution of outcomes, we compare how well two competing hypotheses explain the observed outcomes. The null hypothesis assumes spatial fairness, while the alternate allows different distributions inside and outside regions. Their goodness of fit is then assessed by a likelihood ratio test. If there is no significant difference in how well the two hypotheses explain the observed outcomes, we conclude that the algorithm is spatially fair.
Data-driven soiling detection in PV modules
Jan 30, 2023



Soiling is the accumulation of dirt in solar panels which leads to a decreasing trend in solar energy yield and may be the cause of vast revenue losses. The effect of soiling can be reduced by washing the panels, which is, however, a procedure of non-negligible cost. Moreover, soiling monitoring systems are often unreliable or very costly. We study the problem of estimating the soiling ratio in photo-voltaic (PV) modules, i.e., the ratio of the real power output to the power output that would be produced if solar panels were clean. A key advantage of our algorithms is that they estimate soiling, without needing to train on labelled data, i.e., periods of explicitly monitoring the soiling in each park, and without relying on generic analytical formulas which do not take into account the peculiarities of each installation. We consider as input a time series comprising a minimum set of measurements, that are available to most PV park operators. Our experimental evaluation shows that we significantly outperform current state-of-the-art methods for estimating soiling ratio.
Simplifying Impact Prediction for Scientific Articles
Dec 30, 2020



Estimating the expected impact of an article is valuable for various applications (e.g., article/cooperator recommendation). Most existing approaches attempt to predict the exact number of citations each article will receive in the near future, however this is a difficult regression analysis problem. Moreover, most approaches rely on the existence of rich metadata for each article, a requirement that cannot be adequately fulfilled for a large number of them. In this work, we take advantage of the fact that solving a simpler machine learning problem, that of classifying articles based on their expected impact, is adequate for many real world applications and we propose a simplified model that can be trained using minimal article metadata. Finally, we examine various configurations of this model and evaluate their effectiveness in solving the aforementioned classification problem.