 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Data Integration
Mar 28, 2026Data comes in many forms. From a shallow perspective, they can be viewed as being either in structured (e.g., as a relation, as key-value pairs) or unstructured (e.g., text, image) formats. So far, machines have been fairly good at processing and reasoning over structured data that follows a precise schema. However, the heterogeneity of data poses a significant challenge on how well diverse categories of data can be meaningfully stored and processed. Data Integration, a crucial part of the data engineering pipeline, addresses this by combining disparate data sources and providing unified data access to end-users. Until now, most data integration systems have leaned on only combining structured data sources. Nevertheless, unstructured data (a.k.a. free text) also contains a plethora of knowledge waiting to be utilized. Thus, in this chapter, we firstly make the case for the integration of textual data, to later present its challenges, state of the art and open problems.
The Susceptibility of Example-Based Explainability Methods to Class Outliers
Aug 01, 2024



This study explores the impact of class outliers on the effectiveness of example-based explainability methods for black-box machine learning models. We reformulate existing explainability evaluation metrics, such as correctness and relevance, specifically for example-based methods, and introduce a new metric, distinguishability. Using these metrics, we highlight the shortcomings of current example-based explainability methods, including those who attempt to suppress class outliers. We conduct experiments on two datasets, a text classification dataset and an image classification dataset, and evaluate the performance of four state-of-the-art explainability methods. Our findings underscore the need for robust techniques to tackle the challenges posed by class outliers.
AIDE: Antithetical, Intent-based, and Diverse Example-Based Explanations
Jul 22, 2024



For many use-cases, it is often important to explain the prediction of a black-box model by identifying the most influential training data samples. Existing approaches lack customization for user intent and often provide a homogeneous set of explanation samples, failing to reveal the model's reasoning from different angles. In this paper, we propose AIDE, an approach for providing antithetical (i.e., contrastive), intent-based, diverse explanations for opaque and complex models. AIDE distinguishes three types of explainability intents: interpreting a correct, investigating a wrong, and clarifying an ambiguous prediction. For each intent, AIDE selects an appropriate set of influential training samples that support or oppose the prediction either directly or by contrast. To provide a succinct summary, AIDE uses diversity-aware sampling to avoid redundancy and increase coverage of the training data. We demonstrate the effectiveness of AIDE on image and text classification tasks, in three ways: quantitatively, assessing correctness and continuity; qualitatively, comparing anecdotal evidence from AIDE and other example-based approaches; and via a user study, evaluating multiple aspects of AIDE. The results show that AIDE addresses the limitations of existing methods and exhibits desirable traits for an explainability method.
GLANCE: Global Actions in a Nutshell for Counterfactual Explainability
May 29, 2024



Counterfactual explanations have emerged as an important tool to understand, debug, and audit complex machine learning models. To offer global counterfactual explainability, state-of-the-art methods construct summaries of local explanations, offering a trade-off among conciseness, counterfactual effectiveness, and counterfactual cost or burden imposed on instances. In this work, we provide a concise formulation of the problem of identifying global counterfactuals and establish principled criteria for comparing solutions, drawing inspiration from Pareto dominance. We introduce innovative algorithms designed to address the challenge of finding global counterfactuals for either the entire input space or specific partitions, employing clustering and decision trees as key components. Additionally, we conduct a comprehensive experimental evaluation, considering various instances of the problem and comparing our proposed algorithms with state-of-the-art methods. The results highlight the consistent capability of our algorithms to generate meaningful and interpretable global counterfactual explanations.
FALE: Fairness-Aware ALE Plots for Auditing Bias in Subgroups
Apr 29, 2024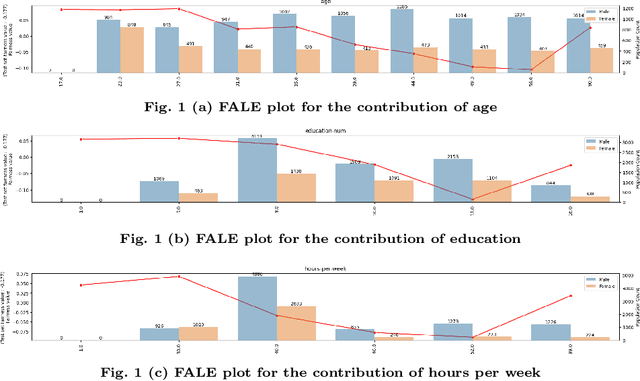
Fairness is steadily becoming a crucial requirement of Machine Learning (ML) systems. A particularly important notion is subgroup fairness, i.e., fairness in subgroups of individuals that are defined by more than one attributes. Identifying bias in subgroups can become both computationally challenging, as well as problematic with respect to comprehensibility and intuitiveness of the finding to end users. In this work we focus on the latter aspects; we propose an explainability method tailored to identifying potential bias in subgroups and visualizing the findings in a user friendly manner to end users. In particular, we extend the ALE plots explainability method, proposing FALE (Fairness aware Accumulated Local Effects) plots, a method for measuring the change in fairness for an affected population corresponding to different values of a feature (attribute). We envision FALE to function as an efficient, user friendly, comprehensible and reliable first-stage tool for identifying subgroups with potential bias issues.
Fairness Aware Counterfactuals for Subgroups
Jun 26, 2023
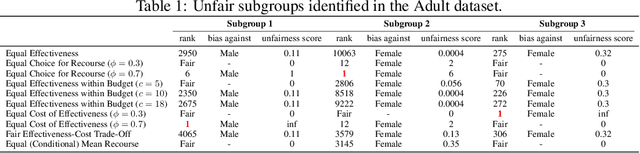

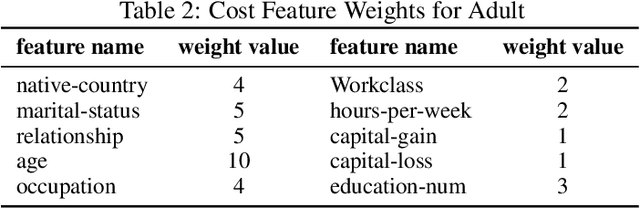
In this work, we present Fairness Aware Counterfactuals for Subgroups (FACTS), a framework for auditing subgroup fairness through counterfactual explanations. We start with revisiting (and generalizing) existing notions and introducing new, more refined notions of subgroup fairness. We aim to (a) formulate different aspects of the difficulty of individuals in certain subgroups to achieve recourse, i.e. receive the desired outcome, either at the micro level, considering members of the subgroup individually, or at the macro level, considering the subgroup as a whole, and (b) introduce notions of subgroup fairness that are robust, if not totally oblivious, to the cost of achieving recourse. We accompany these notions with an efficient, model-agnostic, highly parameterizable, and explainable framework for evaluating subgroup fairness. We demonstrate the advantages, the wide applicability, and the efficiency of our approach through a thorough experimental evaluation of different benchmark datasets.
Auditing for Spatial Fairness
Feb 23, 2023



This paper studies algorithmic fairness when the protected attribute is location. To handle protected attributes that are continuous, such as age or income, the standard approach is to discretize the domain into predefined groups, and compare algorithmic outcomes across groups. However, applying this idea to location raises concerns of gerrymandering and may introduce statistical bias. Prior work addresses these concerns but only for regularly spaced locations, while raising other issues, most notably its inability to discern regions that are likely to exhibit spatial unfairness. Similar to established notions of algorithmic fairness, we define spatial fairness as the statistical independence of outcomes from location. This translates into requiring that for each region of space, the distribution of outcomes is identical inside and outside the region. To allow for localized discrepancies in the distribution of outcomes, we compare how well two competing hypotheses explain the observed outcomes. The null hypothesis assumes spatial fairness, while the alternate allows different distributions inside and outside regions. Their goodness of fit is then assessed by a likelihood ratio test. If there is no significant difference in how well the two hypotheses explain the observed outcomes, we conclude that the algorithm is spatially fair.