 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability-by-Design with Accurate Locally Additive Models and Conditional Feature Effects
Feb 18, 2026Generalized additive models (GAMs) offer interpretability through independent univariate feature effects but underfit when interactions are present in data. GA$^2$Ms add selected pairwise interactions which improves accuracy, but sacrifices interpretability and limits model auditing. We propose \emph{Conditionally Additive Local Models} (CALMs), a new model class, that balances the interpretability of GAMs with the accuracy of GA$^2$Ms. CALMs allow multiple univariate shape functions per feature, each active in different regions of the input space. These regions are defined independently for each feature as simple logical conditions (thresholds) on the features it interacts with. As a result, effects remain locally additive while varying across subregions to capture interactions. We further propose a principled distillation-based training pipeline that identifies homogeneous regions with limited interactions and fits interpretable shape functions via region-aware backfitting. Experiments on diverse classification and regression tasks show that CALMs consistently outperform GAMs and achieve accuracy comparable with GA$^2$Ms. Overall, CALMs offer a compelling trade-off between predictive accuracy and interpretability.
GLANCE: Global Actions in a Nutshell for Counterfactual Explainability
May 29, 2024



Counterfactual explanations have emerged as an important tool to understand, debug, and audit complex machine learning models. To offer global counterfactual explainability, state-of-the-art methods construct summaries of local explanations, offering a trade-off among conciseness, counterfactual effectiveness, and counterfactual cost or burden imposed on instances. In this work, we provide a concise formulation of the problem of identifying global counterfactuals and establish principled criteria for comparing solutions, drawing inspiration from Pareto dominance. We introduce innovative algorithms designed to address the challenge of finding global counterfactuals for either the entire input space or specific partitions, employing clustering and decision trees as key components. Additionally, we conduct a comprehensive experimental evaluation, considering various instances of the problem and comparing our proposed algorithms with state-of-the-art methods. The results highlight the consistent capability of our algorithms to generate meaningful and interpretable global counterfactual explanations.
FALE: Fairness-Aware ALE Plots for Auditing Bias in Subgroups
Apr 29, 2024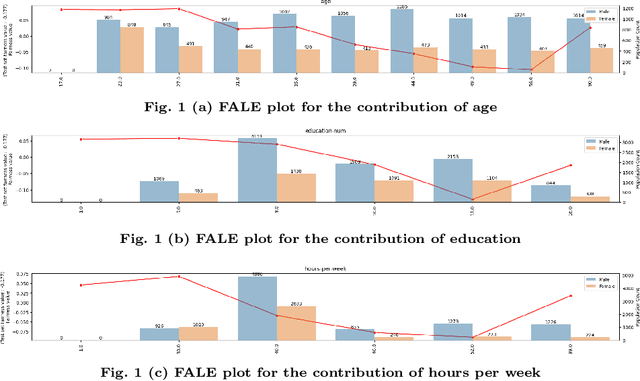
Fairness is steadily becoming a crucial requirement of Machine Learning (ML) systems. A particularly important notion is subgroup fairness, i.e., fairness in subgroups of individuals that are defined by more than one attributes. Identifying bias in subgroups can become both computationally challenging, as well as problematic with respect to comprehensibility and intuitiveness of the finding to end users. In this work we focus on the latter aspects; we propose an explainability method tailored to identifying potential bias in subgroups and visualizing the findings in a user friendly manner to end users. In particular, we extend the ALE plots explainability method, proposing FALE (Fairness aware Accumulated Local Effects) plots, a method for measuring the change in fairness for an affected population corresponding to different values of a feature (attribute). We envision FALE to function as an efficient, user friendly, comprehensible and reliable first-stage tool for identifying subgroups with potential bias issues.
Fairness Aware Counterfactuals for Subgroups
Jun 26, 2023
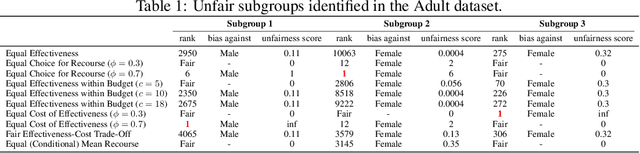

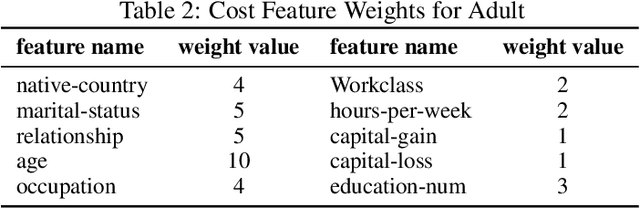
In this work, we present Fairness Aware Counterfactuals for Subgroups (FACTS), a framework for auditing subgroup fairness through counterfactual explanations. We start with revisiting (and generalizing) existing notions and introducing new, more refined notions of subgroup fairness. We aim to (a) formulate different aspects of the difficulty of individuals in certain subgroups to achieve recourse, i.e. receive the desired outcome, either at the micro level, considering members of the subgroup individually, or at the macro level, considering the subgroup as a whole, and (b) introduce notions of subgroup fairness that are robust, if not totally oblivious, to the cost of achieving recourse. We accompany these notions with an efficient, model-agnostic, highly parameterizable, and explainable framework for evaluating subgroup fairness. We demonstrate the advantages, the wide applicability, and the efficiency of our approach through a thorough experimental evaluation of different benchmark datasets.