 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Evaluation of Large Language Models for Multi-Requirement Software Engineering Tasks
Aug 26, 2025Standard single-turn, static benchmarks fall short in evaluating the nuanced capabilities of Large Language Models (LLMs) on complex tasks such as software engineering. In this work, we propose a novel interactive evaluation framework that assesses LLMs on multi-requirement programming tasks through structured, feedback-driven dialogue. Each task is modeled as a requirement dependency graph, and an ``interviewer'' LLM, aware of the ground-truth solution, provides minimal, targeted hints to an ``interviewee'' model to help correct errors and fulfill target constraints. This dynamic protocol enables fine-grained diagnostic insights into model behavior, uncovering strengths and systematic weaknesses that static benchmarks fail to measure. We build on DevAI, a benchmark of 55 curated programming tasks, by adding ground-truth solutions and evaluating the relevance and utility of interviewer hints through expert annotation. Our results highlight the importance of dynamic evaluation in advancing the development of collaborative code-generating agents.
GLANCE: Global Actions in a Nutshell for Counterfactual Explainability
May 29, 2024



Counterfactual explanations have emerged as an important tool to understand, debug, and audit complex machine learning models. To offer global counterfactual explainability, state-of-the-art methods construct summaries of local explanations, offering a trade-off among conciseness, counterfactual effectiveness, and counterfactual cost or burden imposed on instances. In this work, we provide a concise formulation of the problem of identifying global counterfactuals and establish principled criteria for comparing solutions, drawing inspiration from Pareto dominance. We introduce innovative algorithms designed to address the challenge of finding global counterfactuals for either the entire input space or specific partitions, employing clustering and decision trees as key components. Additionally, we conduct a comprehensive experimental evaluation, considering various instances of the problem and comparing our proposed algorithms with state-of-the-art methods. The results highlight the consistent capability of our algorithms to generate meaningful and interpretable global counterfactual explanations.
A Framework for Feasible Counterfactual Exploration incorporating Causality, Sparsity and Density
Apr 20, 2024
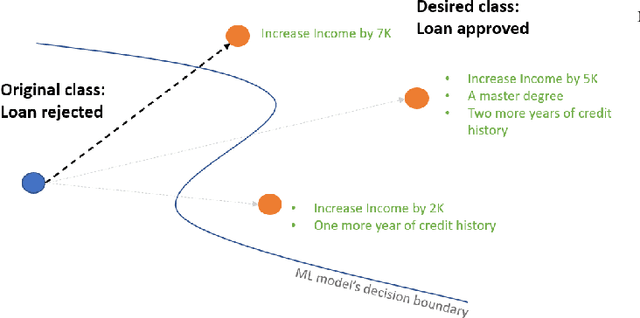
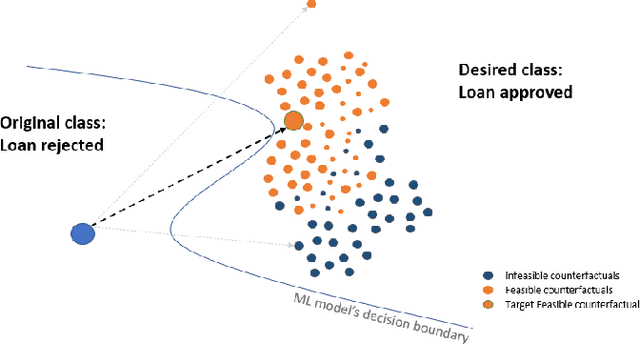
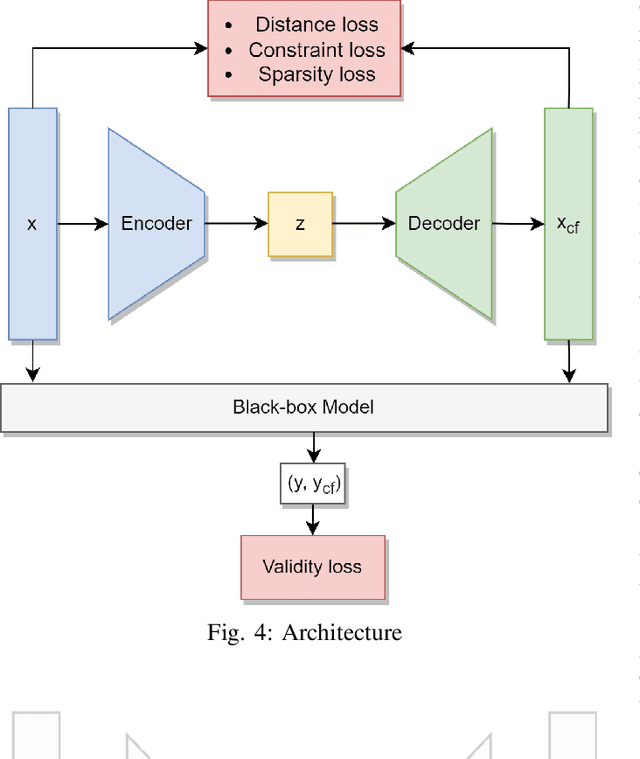
The imminent need to interpret the output of a Machine Learning model with counterfactual (CF) explanations - via small perturbations to the input - has been notable in the research community. Although the variety of CF examples is important, the aspect of them being feasible at the same time, does not necessarily apply in their entirety. This work uses different benchmark datasets to examine through the preservation of the logical causal relations of their attributes, whether CF examples can be generated after a small amount of changes to the original input, be feasible and actually useful to the end-user in a real-world case. To achieve this, we used a black box model as a classifier, to distinguish the desired from the input class and a Variational Autoencoder (VAE) to generate feasible CF examples. As an extension, we also extracted two-dimensional manifolds (one for each dataset) that located the majority of the feasible examples, a representation that adequately distinguished them from infeasible ones. For our experimentation we used three commonly used datasets and we managed to generate feasible and at the same time sparse, CF examples that satisfy all possible predefined causal constraints, by confirming their importance with the attributes in a dataset.
A Novel Framework for Handling Sparse Data in Traffic Forecast
Jan 12, 2023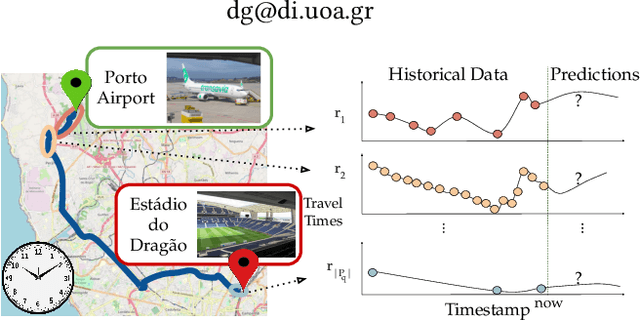

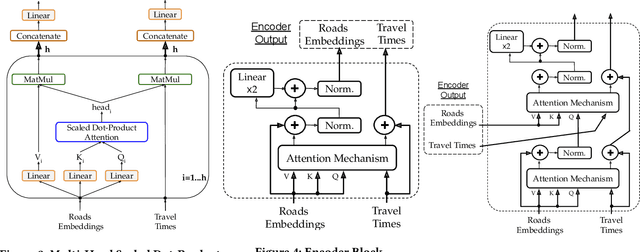
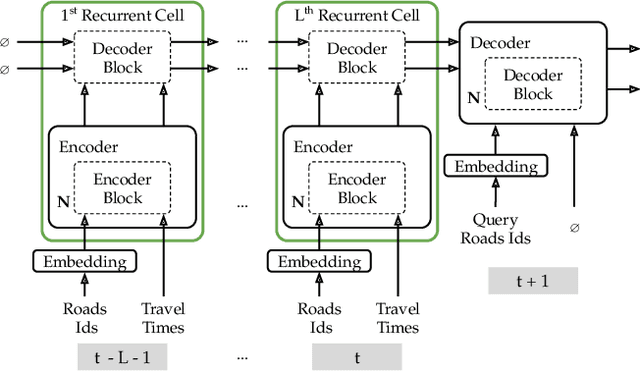
The ever increasing amount of GPS-equipped vehicles provides in real-time valuable traffic information for the roads traversed by the moving vehicles. In this way, a set of sparse and time evolving traffic reports is generated for each road. These time series are a valuable asset in order to forecast the future traffic condition. In this paper we present a deep learning framework that encodes the sparse recent traffic information and forecasts the future traffic condition. Our framework consists of a recurrent part and a decoder. The recurrent part employs an attention mechanism that encodes the traffic reports that are available at a particular time window. The decoder is responsible to forecast the future traffic condition.
HTTE: A Hybrid Technique For Travel Time Estimation In Sparse Data Environments
Jan 12, 2023



Travel time estimation is a critical task, useful to many urban applications at the individual citizen and the stakeholder level. This paper presents a novel hybrid algorithm for travel time estimation that leverages historical and sparse real-time trajectory data. Given a path and a departure time we estimate the travel time taking into account the historical information, the real-time trajectory data and the correlations among different road segments. We detect similar road segments using historical trajectories, and use a latent representation to model the similarities. Our experimental evaluation demonstrates the effectiveness of our approach.
Particle-based Fast Jet Simulation at the LHC with Variational Autoencoders
Mar 01, 2022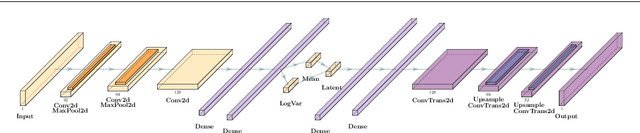
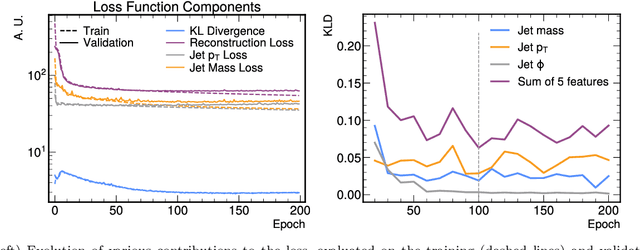
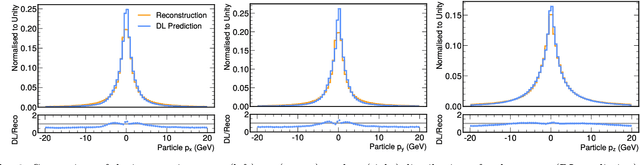
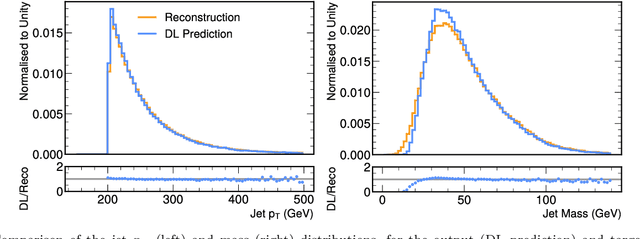
We study how to use Deep Variational Autoencoders for a fast simulation of jets of particles at the LHC. We represent jets as a list of constituents, characterized by their momenta. Starting from a simulation of the jet before detector effects, we train a Deep Variational Autoencoder to return the corresponding list of constituents after detection. Doing so, we bypass both the time-consuming detector simulation and the collision reconstruction steps of a traditional processing chain, speeding up significantly the events generation workflow. Through model optimization and hyperparameter tuning, we achieve state-of-the-art precision on the jet four-momentum, while providing an accurate description of the constituents momenta, and an inference time comparable to that of a rule-based fast simulation.
Particle Cloud Generation with Message Passing Generative Adversarial Networks
Jun 22, 2021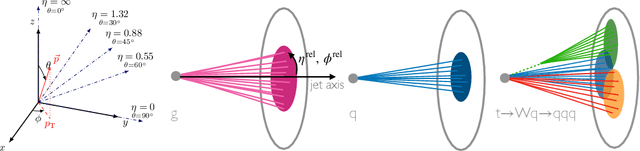

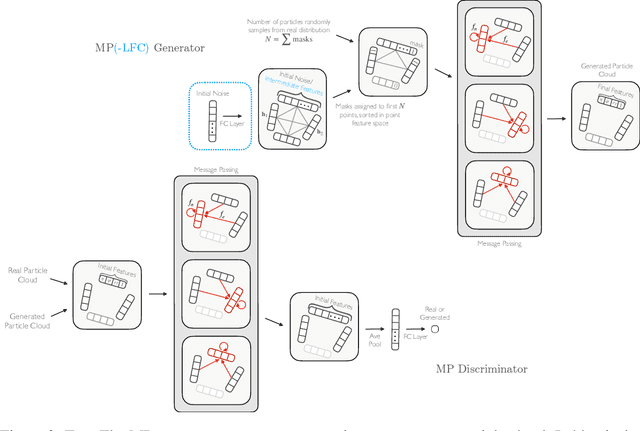
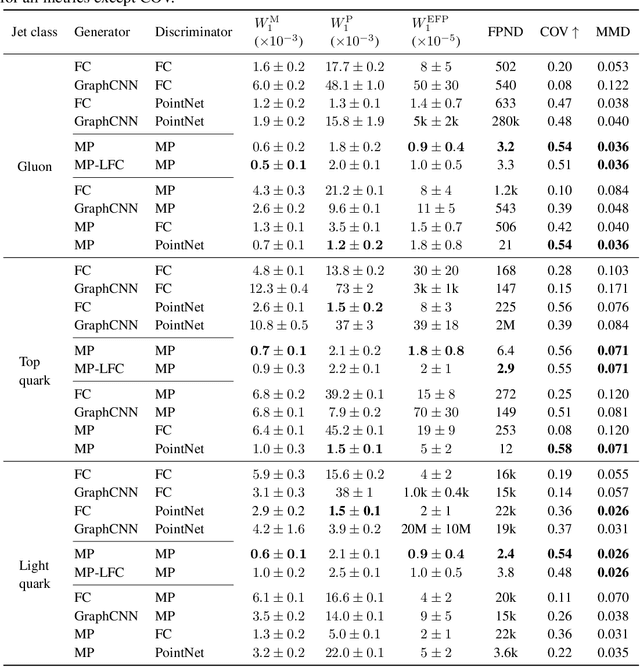
In high energy physics (HEP), jets are collections of correlated particles produced ubiquitously in particle collisions such as those at the CERN Large Hadron Collider (LHC). Machine-learning-based generative models, such as generative adversarial networks (GANs), have the potential to significantly accelerate LHC jet simulations. However, despite jets having a natural representation as a set of particles in momentum-space, a.k.a. a particle cloud, to our knowledge there exist no generative models applied to such a dataset. We introduce a new particle cloud dataset (JetNet), and, due to similarities between particle and point clouds, apply to it existing point cloud GANs. Results are evaluated using (1) the 1-Wasserstein distance between high- and low-level feature distributions, (2) a newly developed Fr\'{e}chet ParticleNet Distance, and (3) the coverage and (4) minimum matching distance metrics. Existing GANs are found to be inadequate for physics applications, hence we develop a new message passing GAN (MPGAN), which outperforms existing point cloud GANs on virtually every metric and shows promise for use in HEP. We propose JetNet as a novel point-cloud-style dataset for the machine learning community to experiment with, and set MPGAN as a benchmark to improve upon for future generative models.
Infant Mortality Prediction using Birth Certificate Data
Jul 25, 2019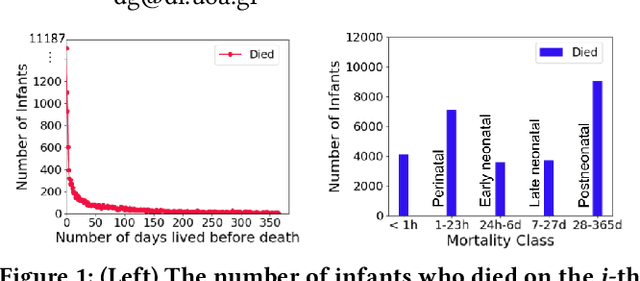
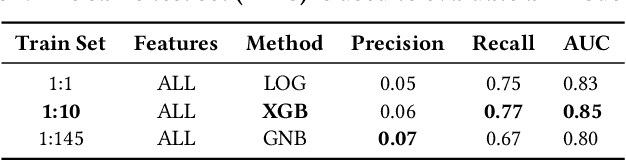
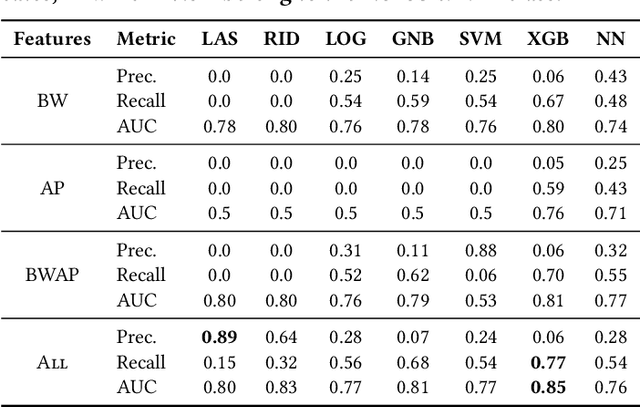
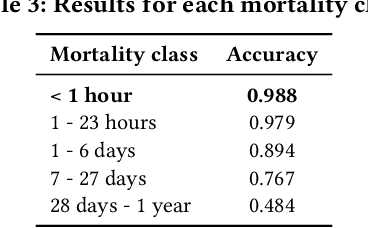
The Infant Mortality Rate (IMR) is the number of infants per 1000 that do not survive until their first birthday. It is an important metric providing information about infant health but it also measures the society's general health status. Despite the high level of prosperity in the U.S.A., the country's IMR is higher than that of many other developed countries. Additionally, the U.S.A. exhibits persistent inequalities in the IMR across different racial and ethnic groups. In this paper, we study the infant mortality prediction using features extracted from birth certificates. We are interested in training classification models to decide whether an infant will survive or not. We focus on exploring and understanding the importance of features in subsets of the population; we compare models trained for individual races to general models. Our evaluation shows that our methodology outperforms standard classification methods used by epidemiology researchers.