 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLANCE: Global Actions in a Nutshell for Counterfactual Explainability
May 29, 2024



Counterfactual explanations have emerged as an important tool to understand, debug, and audit complex machine learning models. To offer global counterfactual explainability, state-of-the-art methods construct summaries of local explanations, offering a trade-off among conciseness, counterfactual effectiveness, and counterfactual cost or burden imposed on instances. In this work, we provide a concise formulation of the problem of identifying global counterfactuals and establish principled criteria for comparing solutions, drawing inspiration from Pareto dominance. We introduce innovative algorithms designed to address the challenge of finding global counterfactuals for either the entire input space or specific partitions, employing clustering and decision trees as key components. Additionally, we conduct a comprehensive experimental evaluation, considering various instances of the problem and comparing our proposed algorithms with state-of-the-art methods. The results highlight the consistent capability of our algorithms to generate meaningful and interpretable global counterfactual explanations.
A Framework for Feasible Counterfactual Exploration incorporating Causality, Sparsity and Density
Apr 20, 2024
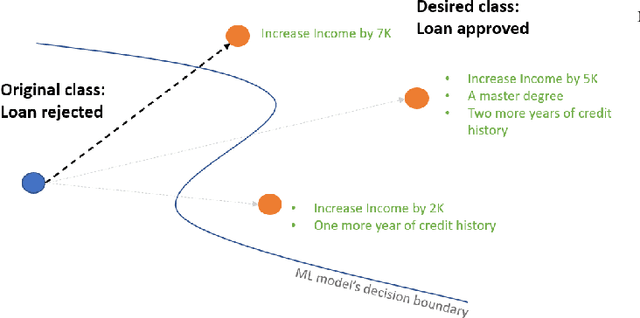
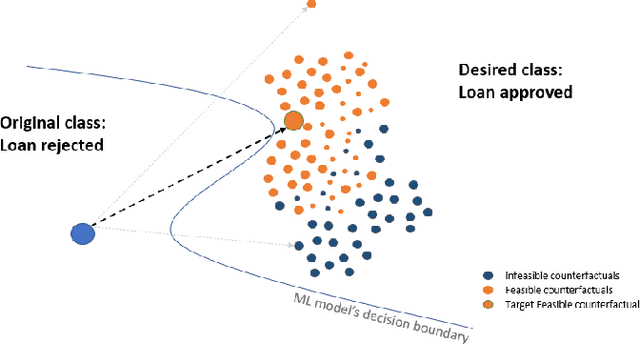
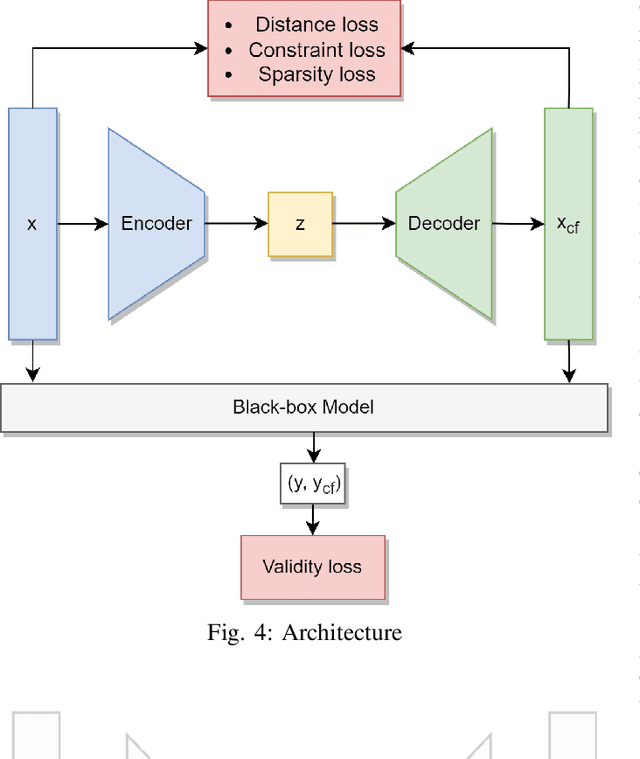
The imminent need to interpret the output of a Machine Learning model with counterfactual (CF) explanations - via small perturbations to the input - has been notable in the research community. Although the variety of CF examples is important, the aspect of them being feasible at the same time, does not necessarily apply in their entirety. This work uses different benchmark datasets to examine through the preservation of the logical causal relations of their attributes, whether CF examples can be generated after a small amount of changes to the original input, be feasible and actually useful to the end-user in a real-world case. To achieve this, we used a black box model as a classifier, to distinguish the desired from the input class and a Variational Autoencoder (VAE) to generate feasible CF examples. As an extension, we also extracted two-dimensional manifolds (one for each dataset) that located the majority of the feasible examples, a representation that adequately distinguished them from infeasible ones. For our experimentation we used three commonly used datasets and we managed to generate feasible and at the same time sparse, CF examples that satisfy all possible predefined causal constraints, by confirming their importance with the attributes in a dataset.