 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Susceptibility of Example-Based Explainability Methods to Class Outliers
Aug 01, 2024



This study explores the impact of class outliers on the effectiveness of example-based explainability methods for black-box machine learning models. We reformulate existing explainability evaluation metrics, such as correctness and relevance, specifically for example-based methods, and introduce a new metric, distinguishability. Using these metrics, we highlight the shortcomings of current example-based explainability methods, including those who attempt to suppress class outliers. We conduct experiments on two datasets, a text classification dataset and an image classification dataset, and evaluate the performance of four state-of-the-art explainability methods. Our findings underscore the need for robust techniques to tackle the challenges posed by class outliers.
AIDE: Antithetical, Intent-based, and Diverse Example-Based Explanations
Jul 22, 2024



For many use-cases, it is often important to explain the prediction of a black-box model by identifying the most influential training data samples. Existing approaches lack customization for user intent and often provide a homogeneous set of explanation samples, failing to reveal the model's reasoning from different angles. In this paper, we propose AIDE, an approach for providing antithetical (i.e., contrastive), intent-based, diverse explanations for opaque and complex models. AIDE distinguishes three types of explainability intents: interpreting a correct, investigating a wrong, and clarifying an ambiguous prediction. For each intent, AIDE selects an appropriate set of influential training samples that support or oppose the prediction either directly or by contrast. To provide a succinct summary, AIDE uses diversity-aware sampling to avoid redundancy and increase coverage of the training data. We demonstrate the effectiveness of AIDE on image and text classification tasks, in three ways: quantitatively, assessing correctness and continuity; qualitatively, comparing anecdotal evidence from AIDE and other example-based approaches; and via a user study, evaluating multiple aspects of AIDE. The results show that AIDE addresses the limitations of existing methods and exhibits desirable traits for an explainability method.
Can Large Language Models Augment a Biomedical Ontology with missing Concepts and Relations?
Nov 12, 2023
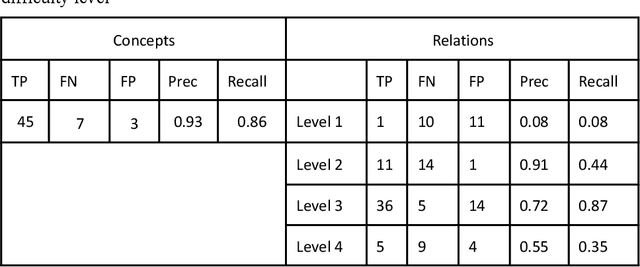
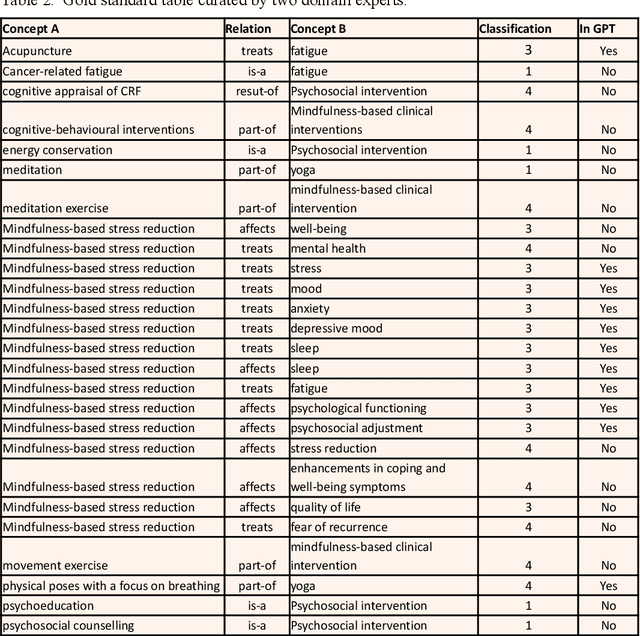
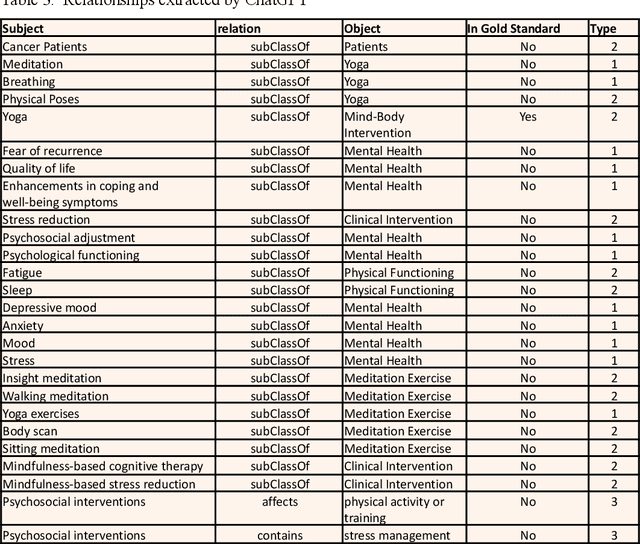
Ontologies play a crucial role in organizing and representing knowledge. However, even current ontologies do not encompass all relevant concepts and relationships. Here, we explore the potential of large language models (LLM) to expand an existing ontology in a semi-automated fashion. We demonstrate our approach on the biomedical ontology SNOMED-CT utilizing semantic relation types from the widely used UMLS semantic network. We propose a method that uses conversational interactions with an LLM to analyze clinical practice guidelines (CPGs) and detect the relationships among the new medical concepts that are not present in SNOMED-CT. Our initial experimentation with the conversational prompts yielded promising preliminary results given a manually generated gold standard, directing our future potential improvements.
Hospitalization Length of Stay Prediction using Patient Event Sequences
Mar 20, 2023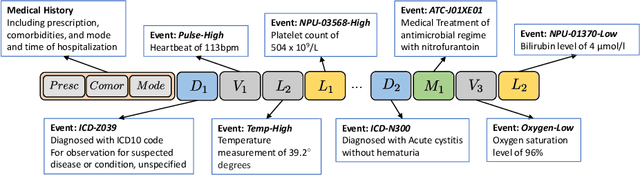
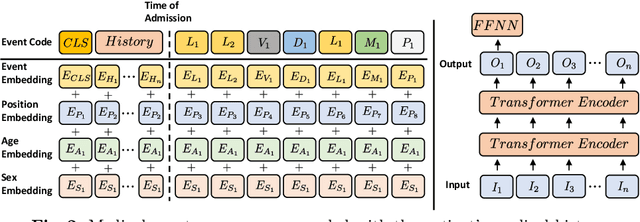
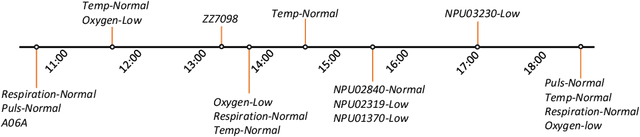
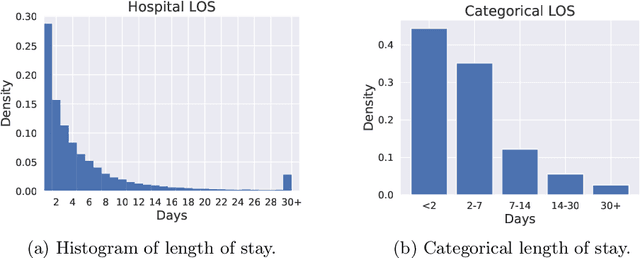
Predicting patients hospital length of stay (LOS) is essential for improving resource allocation and supporting decision-making in healthcare organizations. This paper proposes a novel approach for predicting LOS by modeling patient information as sequences of events. Specifically, we present a transformer-based model, termed Medic-BERT (M-BERT), for LOS prediction using the unique features describing patients medical event sequences. We performed empirical experiments on a cohort of more than 45k emergency care patients from a large Danish hospital. Experimental results show that M-BERT can achieve high accuracy on a variety of LOS problems and outperforms traditional nonsequence-based machine learning approaches.