 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Scientific Discovery with Multi-Document Summarization of Impact-Ranked Papers
Aug 05, 2025The growing volume of scientific literature makes it challenging for scientists to move from a list of papers to a synthesized understanding of a topic. Because of the constant influx of new papers on a daily basis, even if a scientist identifies a promising set of papers, they still face the tedious task of individually reading through dozens of titles and abstracts to make sense of occasionally conflicting findings. To address this critical bottleneck in the research workflow, we introduce a summarization feature to BIP! Finder, a scholarly search engine that ranks literature based on distinct impact aspects like popularity and influence. Our approach enables users to generate two types of summaries from top-ranked search results: a concise summary for an instantaneous at-a-glance comprehension and a more comprehensive literature review-style summary for greater, better-organized comprehension. This ability dynamically leverages BIP! Finder's already existing impact-based ranking and filtering features to generate context-sensitive, synthesized narratives that can significantly accelerate literature discovery and comprehension.
From raw affiliations to organization identifiers
May 13, 2025Accurate affiliation matching, which links affiliation strings to standardized organization identifiers, is critical for improving research metadata quality, facilitating comprehensive bibliometric analyses, and supporting data interoperability across scholarly knowledge bases. Existing approaches fail to handle the complexity of affiliation strings that often include mentions of multiple organizations or extraneous information. In this paper, we present AffRo, a novel approach designed to address these challenges, leveraging advanced parsing and disambiguation techniques. We also introduce AffRoDB, an expert-curated dataset to systematically evaluate affiliation matching algorithms, ensuring robust benchmarking. Results demonstrate the effectiveness of AffRp in accurately identifying organizations from complex affiliation strings.
Can LLMs Predict Citation Intent? An Experimental Analysis of In-context Learning and Fine-tuning on Open LLMs
Feb 20, 2025This work investigates the ability of open Large Language Models (LLMs) to predict citation intent through in-context learning and fine-tuning. Unlike traditional approaches that rely on pre-trained models like SciBERT, which require extensive domain-specific pretraining and specialized architectures, we demonstrate that general-purpose LLMs can be adapted to this task with minimal task-specific data. We evaluate twelve model variations across five prominent open LLM families using zero, one, few, and many-shot prompting to assess performance across scenarios. Our experimental study identifies the top-performing model through extensive experimentation of in-context learning-related parameters, which we fine-tune to further enhance task performance. The results highlight the strengths and limitations of LLMs in recognizing citation intents, providing valuable insights for model selection and prompt engineering. Additionally, we make our end-to-end evaluation framework and models openly available for future use.
A Crawler Architecture for Harvesting the Clear, Social, and Dark Web for IoT-Related Cyber-Threat Intelligence
Sep 14, 2021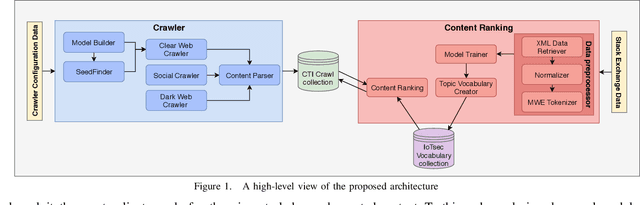


The clear, social, and dark web have lately been identified as rich sources of valuable cyber-security information that -given the appropriate tools and methods-may be identified, crawled and subsequently leveraged to actionable cyber-threat intelligence. In this work, we focus on the information gathering task, and present a novel crawling architecture for transparently harvesting data from security websites in the clear web, security forums in the social web, and hacker forums/marketplaces in the dark web. The proposed architecture adopts a two-phase approach to data harvesting. Initially a machine learning-based crawler is used to direct the harvesting towards websites of interest, while in the second phase state-of-the-art statistical language modelling techniques are used to represent the harvested information in a latent low-dimensional feature space and rank it based on its potential relevance to the task at hand. The proposed architecture is realised using exclusively open-source tools, and a preliminary evaluation with crowdsourced results demonstrates its effectiveness.
* 6 pages, 2 figures
Social Media Monitoring for IoT Cyber-Threats
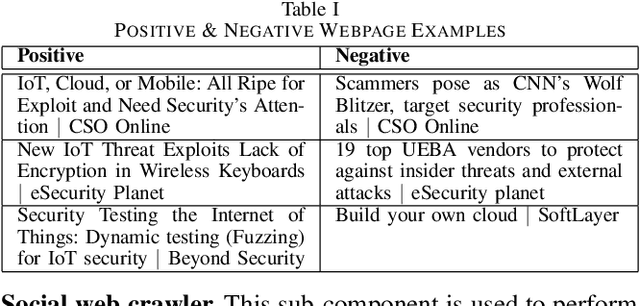
Sep 09, 2021
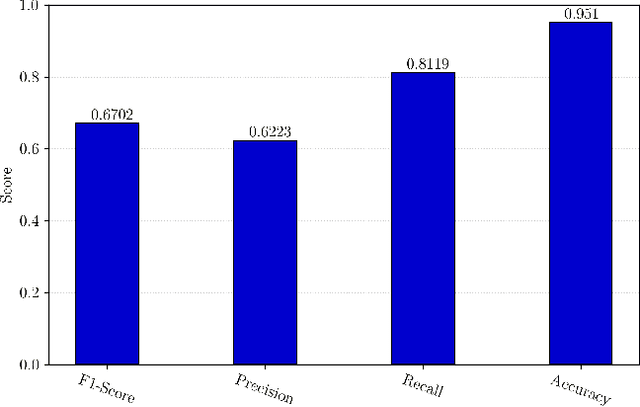


The rapid development of IoT applications and their use in various fields of everyday life has resulted in an escalated number of different possible cyber-threats, and has consequently raised the need of securing IoT devices. Collecting Cyber-Threat Intelligence (e.g., zero-day vulnerabilities or trending exploits) from various online sources and utilizing it to proactively secure IoT systems or prepare mitigation scenarios has proven to be a promising direction. In this work, we focus on social media monitoring and investigate real-time Cyber-Threat Intelligence detection from the Twitter stream. Initially, we compare and extensively evaluate six different machine-learning based classification alternatives trained with vulnerability descriptions and tested with real-world data from the Twitter stream to identify the best-fitting solution. Subsequently, based on our findings, we propose a novel social media monitoring system tailored to the IoT domain; the system allows users to identify recent/trending vulnerabilities and exploits on IoT devices. Finally, to aid research on the field and support the reproducibility of our results we publicly release all annotated datasets created during this process.
* 6 pages, 2 figures