 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScienceBenchmark: A Complex Real-World Benchmark for Evaluating Natural Language to SQL Systems
Jun 07, 2023



Natural Language to SQL systems (NL-to-SQL) have recently shown a significant increase in accuracy for natural language to SQL query translation. This improvement is due to the emergence of transformer-based language models, and the popularity of the Spider benchmark - the de-facto standard for evaluating NL-to-SQL systems. The top NL-to-SQL systems reach accuracies of up to 85\%. However, Spider mainly contains simple databases with few tables, columns, and entries, which does not reflect a realistic setting. Moreover, complex real-world databases with domain-specific content have little to no training data available in the form of NL/SQL-pairs leading to poor performance of existing NL-to-SQL systems. In this paper, we introduce ScienceBenchmark, a new complex NL-to-SQL benchmark for three real-world, highly domain-specific databases. For this new benchmark, SQL experts and domain experts created high-quality NL/SQL-pairs for each domain. To garner more data, we extended the small amount of human-generated data with synthetic data generated using GPT-3. We show that our benchmark is highly challenging, as the top performing systems on Spider achieve a very low performance on our benchmark. Thus, the challenge is many-fold: creating NL-to-SQL systems for highly complex domains with a small amount of hand-made training data augmented with synthetic data. To our knowledge, ScienceBenchmark is the first NL-to-SQL benchmark designed with complex real-world scientific databases, containing challenging training and test data carefully validated by domain experts.
INODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
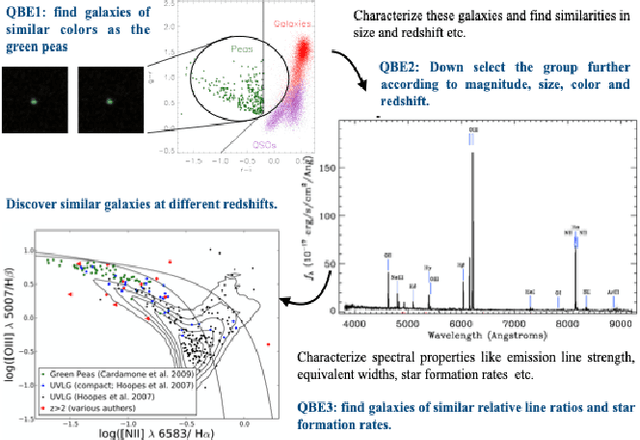
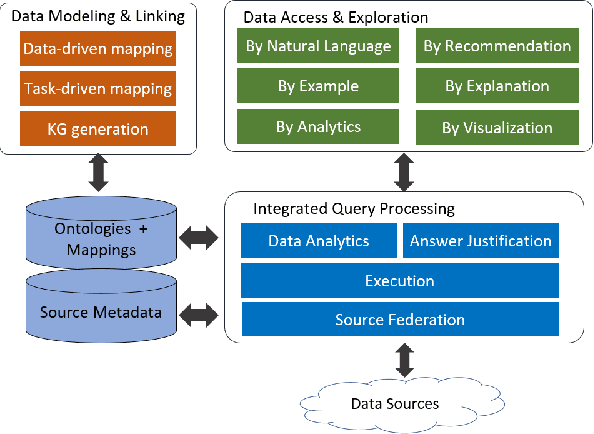

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.