 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Anomaly Detection with Anomaly-Free Regions
Sep 30, 2024



We propose the novel concept of anomaly-free regions (AFR) to improve anomaly detection. An AFR is a region in the data space for which it is known that there are no anomalies inside it, e.g., via domain knowledge. This region can contain any number of normal data points and can be anywhere in the data space. AFRs have the key advantage that they constrain the estimation of the distribution of non-anomalies: The estimated probability mass inside the AFR must be consistent with the number of normal data points inside the AFR. Based on this insight, we provide a solid theoretical foundation and a reference implementation of anomaly detection using AFRs. Our empirical results confirm that anomaly detection constrained via AFRs improves upon unconstrained anomaly detection. Specifically, we show that, when equipped with an estimated AFR, an efficient algorithm based on random guessing becomes a strong baseline that several widely-used methods struggle to overcome. On a dataset with a ground-truth AFR available, the current state of the art is outperformed.
Activation Bottleneck: Sigmoidal Neural Networks Cannot Forecast a Straight Line
Jun 04, 2024A neural network has an activation bottleneck if one of its hidden layers has a bounded image. We show that networks with an activation bottleneck cannot forecast unbounded sequences such as straight lines, random walks, or any sequence with a trend: The difference between prediction and ground truth becomes arbitrary large, regardless of the training procedure. Widely-used neural network architectures such as LSTM and GRU suffer from this limitation. In our analysis, we characterize activation bottlenecks and explain why they prevent sigmoidal networks from learning unbounded sequences. We experimentally validate our findings and discuss modifications to network architectures which mitigate the effects of activation bottlenecks.
Recommendation Fairness in Social Networks Over Time
Feb 05, 2024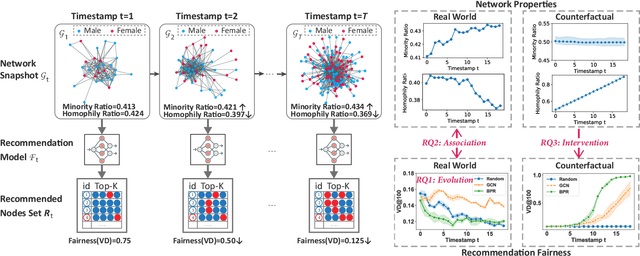
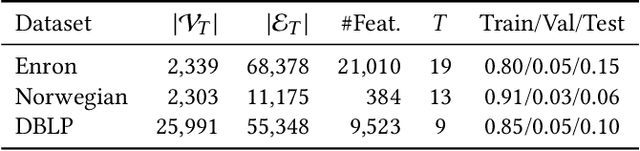
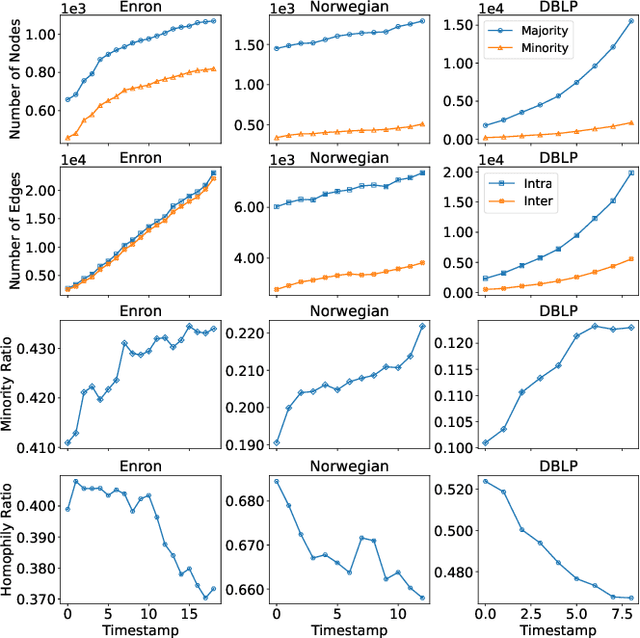
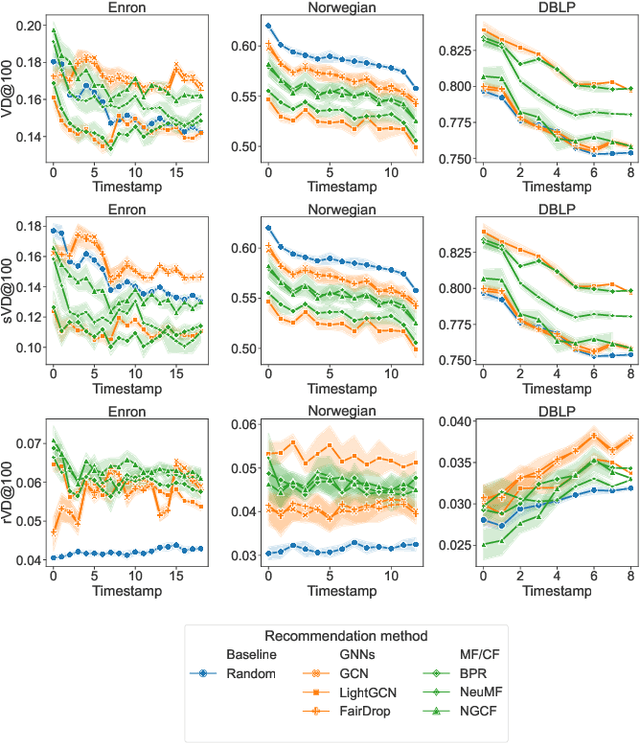
In social recommender systems, it is crucial that the recommendation models provide equitable visibility for different demographic groups, such as gender or race. Most existing research has addressed this problem by only studying individual static snapshots of networks that typically change over time. To address this gap, we study the evolution of recommendation fairness over time and its relation to dynamic network properties. We examine three real-world dynamic networks by evaluating the fairness of six recommendation algorithms and analyzing the association between fairness and network properties over time. We further study how interventions on network properties influence fairness by examining counterfactual scenarios with alternative evolution outcomes and differing network properties. Our results on empirical datasets suggest that recommendation fairness improves over time, regardless of the recommendation method. We also find that two network properties, minority ratio, and homophily ratio, exhibit stable correlations with fairness over time. Our counterfactual study further suggests that an extreme homophily ratio potentially contributes to unfair recommendations even with a balanced minority ratio. Our work provides insights into the evolution of fairness within dynamic networks in social science. We believe that our findings will help system operators and policymakers to better comprehend the implications of temporal changes and interventions targeting fairness in social networks.
Adversarial Inter-Group Link Injection Degrades the Fairness of Graph Neural Networks
Sep 13, 2022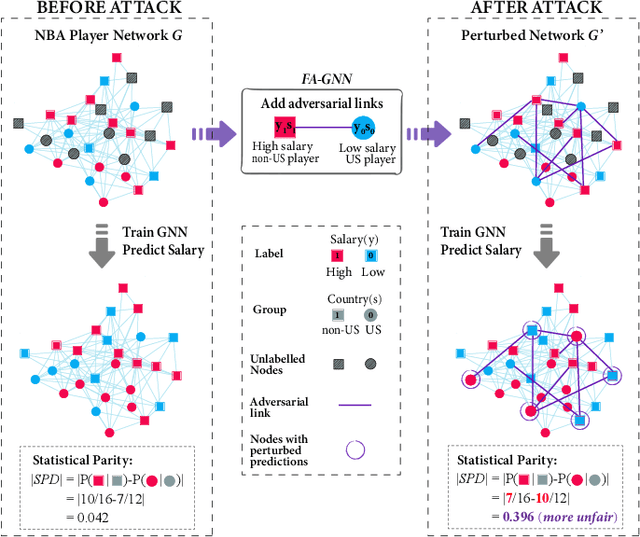
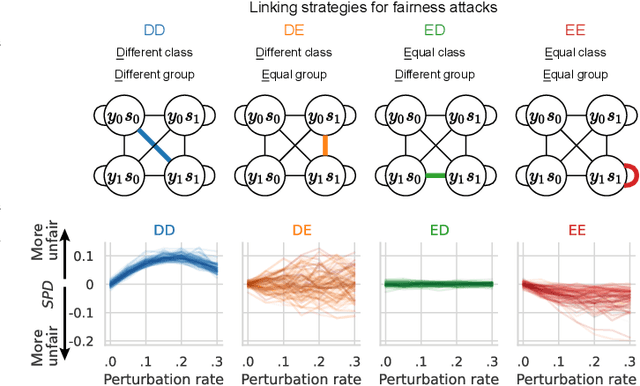
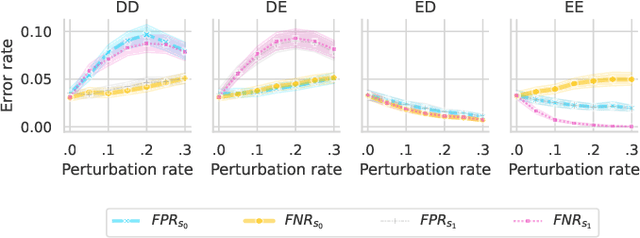
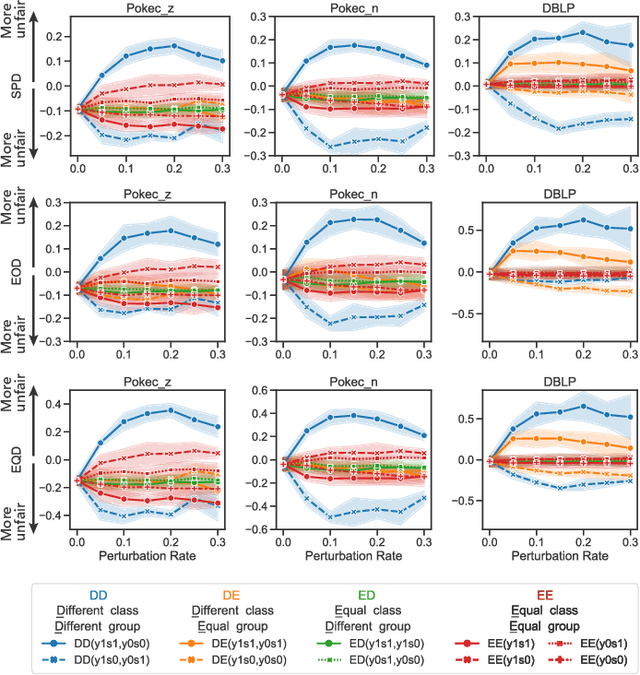
We present evidence for the existence and effectiveness of adversarial attacks on graph neural networks (GNNs) that aim to degrade fairness. These attacks can disadvantage a particular subgroup of nodes in GNN-based node classification, where nodes of the underlying network have sensitive attributes, such as race or gender. We conduct qualitative and experimental analyses explaining how adversarial link injection impairs the fairness of GNN predictions. For example, an attacker can compromise the fairness of GNN-based node classification by injecting adversarial links between nodes belonging to opposite subgroups and opposite class labels. Our experiments on empirical datasets demonstrate that adversarial fairness attacks can significantly degrade the fairness of GNN predictions (attacks are effective) with a low perturbation rate (attacks are efficient) and without a significant drop in accuracy (attacks are deceptive). This work demonstrates the vulnerability of GNN models to adversarial fairness attacks. We hope our findings raise awareness about this issue in our community and lay a foundation for the future development of GNN models that are more robust to such attacks.
Structack: Structure-based Adversarial Attacks on Graph Neural Networks
Jul 28, 2021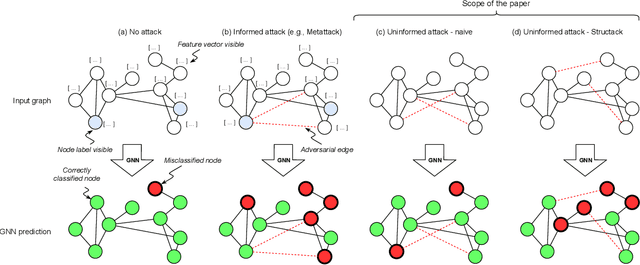
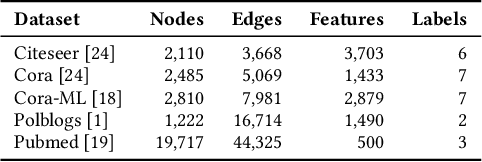
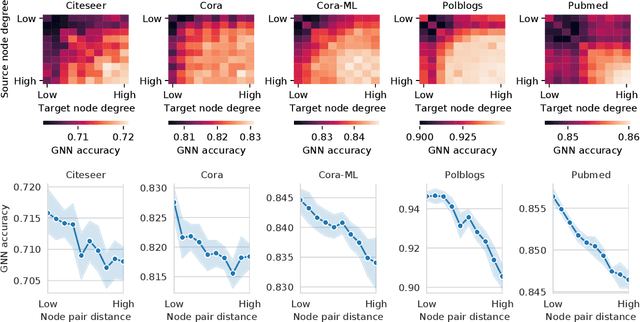

Recent work has shown that graph neural networks (GNNs) are vulnerable to adversarial attacks on graph data. Common attack approaches are typically informed, i.e. they have access to information about node attributes such as labels and feature vectors. In this work, we study adversarial attacks that are uninformed, where an attacker only has access to the graph structure, but no information about node attributes. Here the attacker aims to exploit structural knowledge and assumptions, which GNN models make about graph data. In particular, literature has shown that structural node centrality and similarity have a strong influence on learning with GNNs. Therefore, we study the impact of centrality and similarity on adversarial attacks on GNNs. We demonstrate that attackers can exploit this information to decrease the performance of GNNs by focusing on injecting links between nodes of low similarity and, surprisingly, low centrality. We show that structure-based uninformed attacks can approach the performance of informed attacks, while being computationally more efficient. With our paper, we present a new attack strategy on GNNs that we refer to as Structack. Structack can successfully manipulate the performance of GNNs with very limited information while operating under tight computational constraints. Our work contributes towards building more robust machine learning approaches on graphs.
On the Impact of Communities on Semi-supervised Classification Using Graph Neural Networks
Oct 30, 2020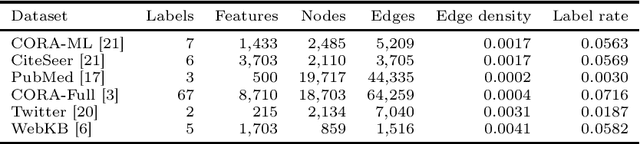
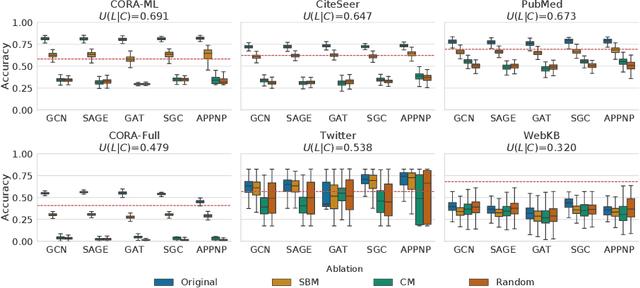
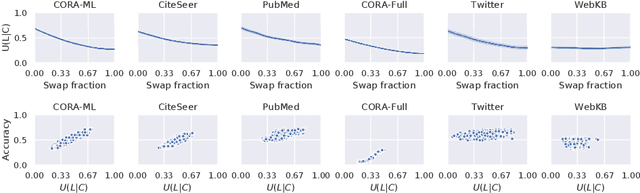
Graph Neural Networks (GNNs) are effective in many applications. Still, there is a limited understanding of the effect of common graph structures on the learning process of GNNs. In this work, we systematically study the impact of community structure on the performance of GNNs in semi-supervised node classification on graphs. Following an ablation study on six datasets, we measure the performance of GNNs on the original graphs, and the change in performance in the presence and the absence of community structure. Our results suggest that communities typically have a major impact on the learning process and classification performance. For example, in cases where the majority of nodes from one community share a single classification label, breaking up community structure results in a significant performance drop. On the other hand, for cases where labels show low correlation with communities, we find that the graph structure is rather irrelevant to the learning process, and a feature-only baseline becomes hard to beat. With our work, we provide deeper insights in the abilities and limitations of GNNs, including a set of general guidelines for model selection based on the graph structure.
Empirical Comparison of Graph Embeddings for Trust-Based Collaborative Filtering
Mar 30, 2020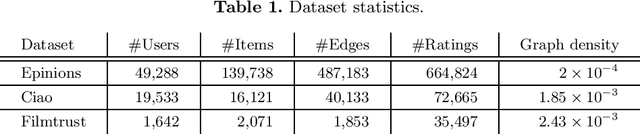
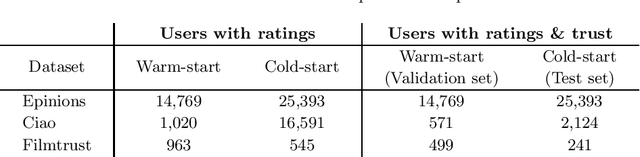
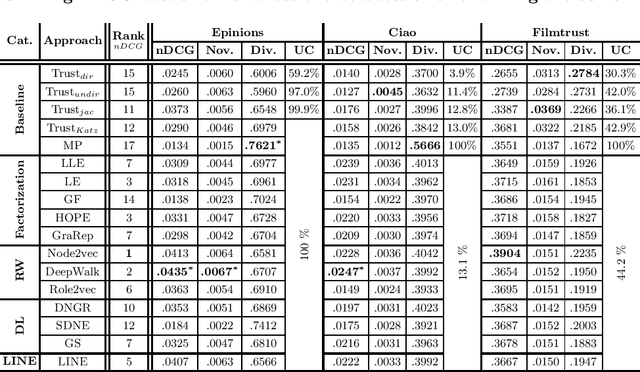
In this work, we study the utility of graph embeddings to generate latent user representations for trust-based collaborative filtering. In a cold-start setting, on three publicly available datasets, we evaluate approaches from four method families: (i) factorization-based, (ii) random walk-based, (iii) deep learning-based, and (iv) the Large-scale Information Network Embedding (LINE) approach. We find that across the four families, random-walk-based approaches consistently achieve the best accuracy. Besides, they result in highly novel and diverse recommendations. Furthermore, our results show that the use of graph embeddings in trust-based collaborative filtering significantly improves user coverage.