 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Powered Immersive Assistance for Interactive Task Execution in Industrial Environments
Jul 12, 2024Many industrial sectors rely on well-trained employees that are able to operate complex machinery. In this work, we demonstrate an AI-powered immersive assistance system that supports users in performing complex tasks in industrial environments. Specifically, our system leverages a VR environment that resembles a juice mixer setup. This digital twin of a physical setup simulates complex industrial machinery used to mix preparations or liquids (e.g., similar to the pharmaceutical industry) and includes various containers, sensors, pumps, and flow controllers. This setup demonstrates our system's capabilities in a controlled environment while acting as a proof-of-concept for broader industrial applications. The core components of our multimodal AI assistant are a large language model and a speech-to-text model that process a video and audio recording of an expert performing the task in a VR environment. The video and speech input extracted from the expert's video enables it to provide step-by-step guidance to support users in executing complex tasks. This demonstration showcases the potential of our AI-powered assistant to reduce cognitive load, increase productivity, and enhance safety in industrial environments.
Beyond-Accuracy: A Review on Diversity, Serendipity and Fairness in Recommender Systems Based on Graph Neural Networks
Oct 03, 2023

By providing personalized suggestions to users, recommender systems have become essential to numerous online platforms. Collaborative filtering, particularly graph-based approaches using Graph Neural Networks (GNNs), have demonstrated great results in terms of recommendation accuracy. However, accuracy may not always be the most important criterion for evaluating recommender systems' performance, since beyond-accuracy aspects such as recommendation diversity, serendipity, and fairness can strongly influence user engagement and satisfaction. This review paper focuses on addressing these dimensions in GNN-based recommender systems, going beyond the conventional accuracy-centric perspective. We begin by reviewing recent developments in approaches that improve not only the accuracy-diversity trade-off but also promote serendipity and fairness in GNN-based recommender systems. We discuss different stages of model development including data preprocessing, graph construction, embedding initialization, propagation layers, embedding fusion, score computation, and training methodologies. Furthermore, we present a look into the practical difficulties encountered in assuring diversity, serendipity, and fairness, while retaining high accuracy. Finally, we discuss potential future research directions for developing more robust GNN-based recommender systems that go beyond the unidimensional perspective of focusing solely on accuracy. This review aims to provide researchers and practitioners with an in-depth understanding of the multifaceted issues that arise when designing GNN-based recommender systems, setting our work apart by offering a comprehensive exploration of beyond-accuracy dimensions.
Uptrendz: API-Centric Real-time Recommendations in Multi-Domain Settings
Jan 03, 2023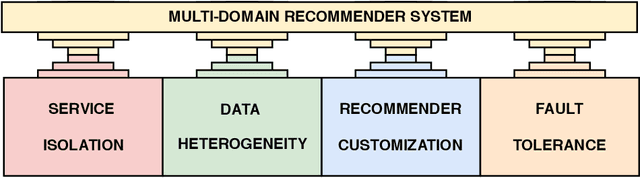
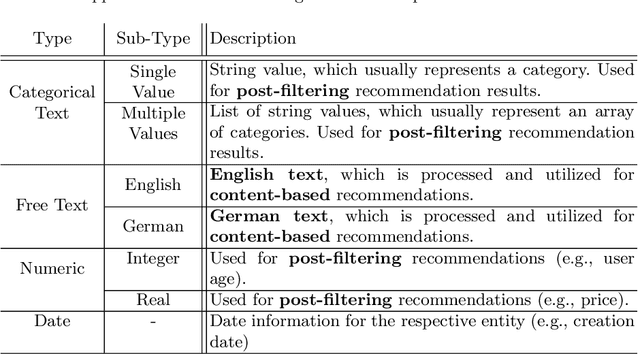
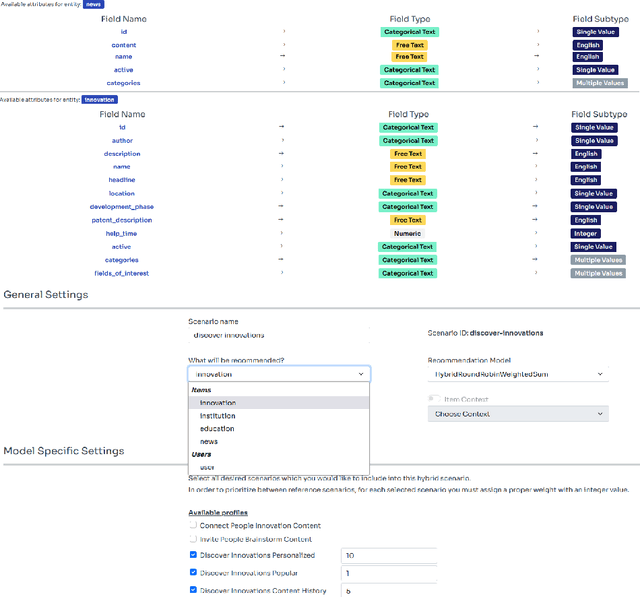

In this work, we tackle the problem of adapting a real-time recommender system to multiple application domains, and their underlying data models and customization requirements. To do that, we present Uptrendz, a multi-domain recommendation platform that can be customized to provide real-time recommendations in an API-centric way. We demonstrate (i) how to set up a real-time movie recommender using the popular MovieLens-100k dataset, and (ii) how to simultaneously support multiple application domains based on the use-case of recommendations in entrepreneurial start-up founding. For that, we differentiate between domains on the item- and system-level. We believe that our demonstration shows a convenient way to adapt, deploy and evaluate a recommender system in an API-centric way. The source-code and documentation that demonstrates how to utilize the configured Uptrendz API is available on GitHub.
Structack: Structure-based Adversarial Attacks on Graph Neural Networks
Jul 28, 2021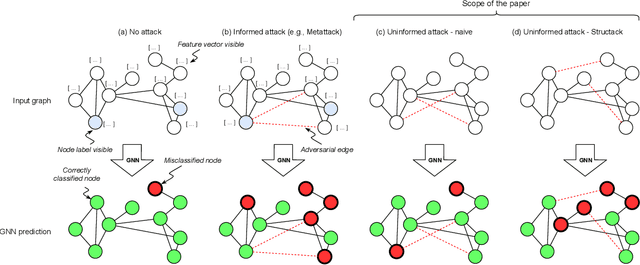
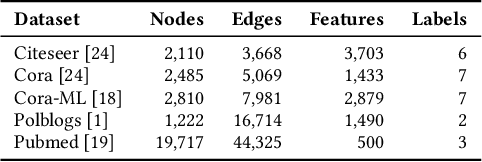

Recent work has shown that graph neural networks (GNNs) are vulnerable to adversarial attacks on graph data. Common attack approaches are typically informed, i.e. they have access to information about node attributes such as labels and feature vectors. In this work, we study adversarial attacks that are uninformed, where an attacker only has access to the graph structure, but no information about node attributes. Here the attacker aims to exploit structural knowledge and assumptions, which GNN models make about graph data. In particular, literature has shown that structural node centrality and similarity have a strong influence on learning with GNNs. Therefore, we study the impact of centrality and similarity on adversarial attacks on GNNs. We demonstrate that attackers can exploit this information to decrease the performance of GNNs by focusing on injecting links between nodes of low similarity and, surprisingly, low centrality. We show that structure-based uninformed attacks can approach the performance of informed attacks, while being computationally more efficient. With our paper, we present a new attack strategy on GNNs that we refer to as Structack. Structack can successfully manipulate the performance of GNNs with very limited information while operating under tight computational constraints. Our work contributes towards building more robust machine learning approaches on graphs.
On the Impact of Communities on Semi-supervised Classification Using Graph Neural Networks
Oct 30, 2020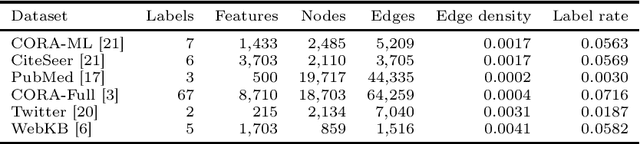
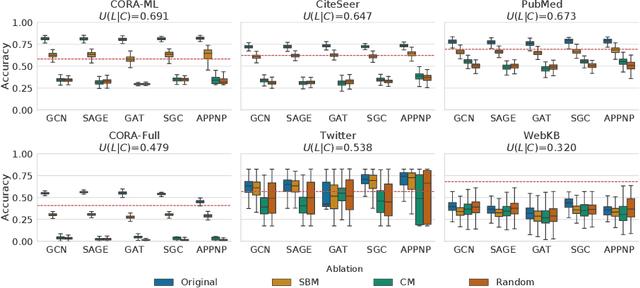
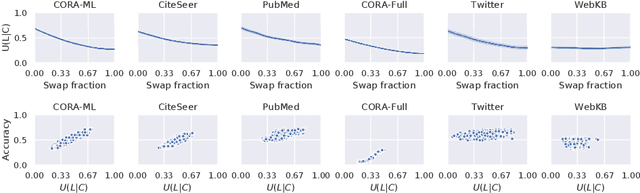
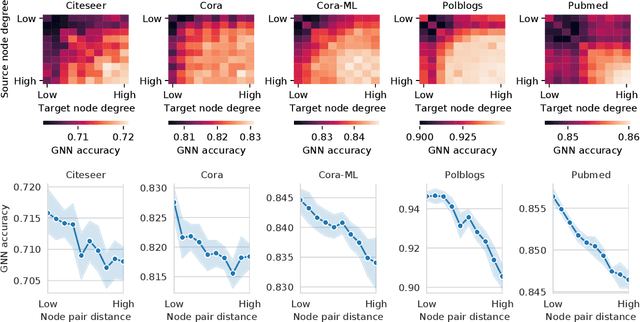
Graph Neural Networks (GNNs) are effective in many applications. Still, there is a limited understanding of the effect of common graph structures on the learning process of GNNs. In this work, we systematically study the impact of community structure on the performance of GNNs in semi-supervised node classification on graphs. Following an ablation study on six datasets, we measure the performance of GNNs on the original graphs, and the change in performance in the presence and the absence of community structure. Our results suggest that communities typically have a major impact on the learning process and classification performance. For example, in cases where the majority of nodes from one community share a single classification label, breaking up community structure results in a significant performance drop. On the other hand, for cases where labels show low correlation with communities, we find that the graph structure is rather irrelevant to the learning process, and a feature-only baseline becomes hard to beat. With our work, we provide deeper insights in the abilities and limitations of GNNs, including a set of general guidelines for model selection based on the graph structure.
Empirical Comparison of Graph Embeddings for Trust-Based Collaborative Filtering
Mar 30, 2020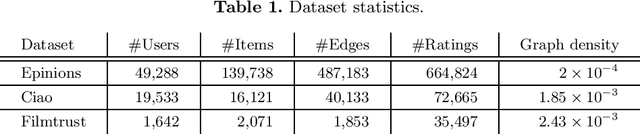
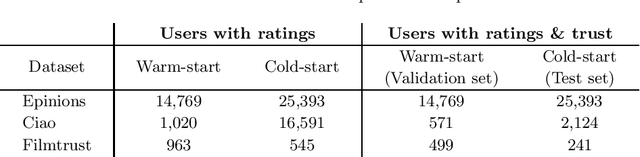
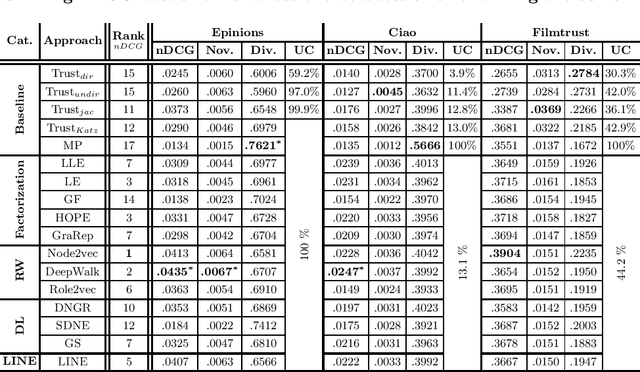
In this work, we study the utility of graph embeddings to generate latent user representations for trust-based collaborative filtering. In a cold-start setting, on three publicly available datasets, we evaluate approaches from four method families: (i) factorization-based, (ii) random walk-based, (iii) deep learning-based, and (iv) the Large-scale Information Network Embedding (LINE) approach. We find that across the four families, random-walk-based approaches consistently achieve the best accuracy. Besides, they result in highly novel and diverse recommendations. Furthermore, our results show that the use of graph embeddings in trust-based collaborative filtering significantly improves user coverage.