 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Real-Time Classification of Early Media in Voice Communications
Oct 28, 2024This paper investigates the industrial setting of real-time classification of early media exchanged during the initialization phase of voice calls. We explore the application of state-of-the-art audio tagging models and highlight some limitations when applied to the classification of early media. While most existing approaches leverage convolutional neural networks, we propose a novel approach for low-resource requirements based on gradient-boosted trees. Our approach not only demonstrates a substantial improvement in runtime performance, but also exhibits a comparable accuracy. We show that leveraging knowledge distillation and class aggregation techniques to train a simpler and smaller model accelerates the classification of early media in voice calls. We provide a detailed analysis of the results on a proprietary and publicly available dataset, regarding accuracy and runtime performance. We additionally report a case study of the achieved performance improvements at a regional data center in India.
Beyond-Accuracy: A Review on Diversity, Serendipity and Fairness in Recommender Systems Based on Graph Neural Networks
Oct 03, 2023

By providing personalized suggestions to users, recommender systems have become essential to numerous online platforms. Collaborative filtering, particularly graph-based approaches using Graph Neural Networks (GNNs), have demonstrated great results in terms of recommendation accuracy. However, accuracy may not always be the most important criterion for evaluating recommender systems' performance, since beyond-accuracy aspects such as recommendation diversity, serendipity, and fairness can strongly influence user engagement and satisfaction. This review paper focuses on addressing these dimensions in GNN-based recommender systems, going beyond the conventional accuracy-centric perspective. We begin by reviewing recent developments in approaches that improve not only the accuracy-diversity trade-off but also promote serendipity and fairness in GNN-based recommender systems. We discuss different stages of model development including data preprocessing, graph construction, embedding initialization, propagation layers, embedding fusion, score computation, and training methodologies. Furthermore, we present a look into the practical difficulties encountered in assuring diversity, serendipity, and fairness, while retaining high accuracy. Finally, we discuss potential future research directions for developing more robust GNN-based recommender systems that go beyond the unidimensional perspective of focusing solely on accuracy. This review aims to provide researchers and practitioners with an in-depth understanding of the multifaceted issues that arise when designing GNN-based recommender systems, setting our work apart by offering a comprehensive exploration of beyond-accuracy dimensions.
Uptrendz: API-Centric Real-time Recommendations in Multi-Domain Settings
Jan 03, 2023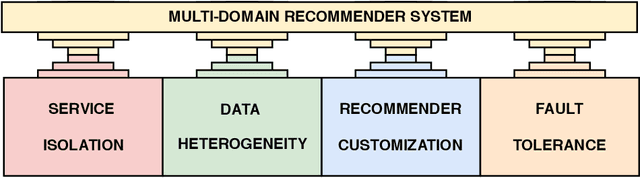
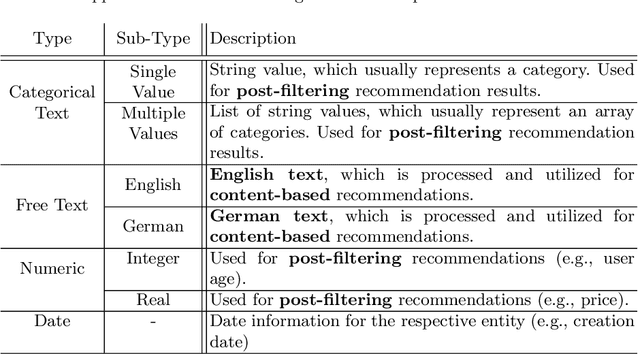
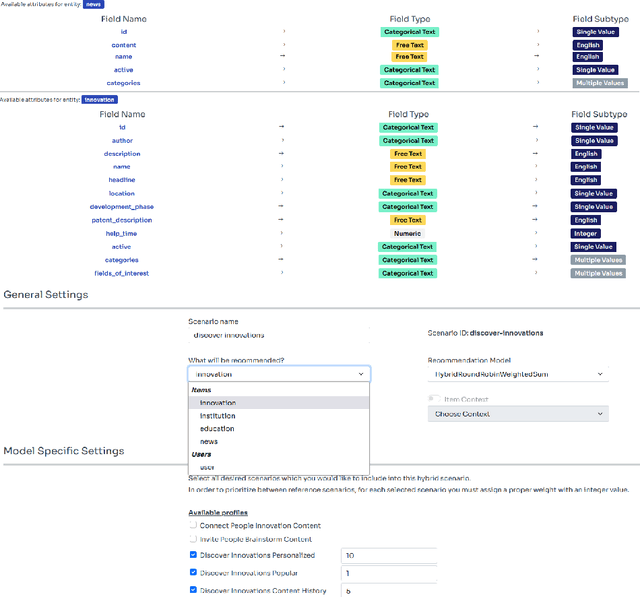

In this work, we tackle the problem of adapting a real-time recommender system to multiple application domains, and their underlying data models and customization requirements. To do that, we present Uptrendz, a multi-domain recommendation platform that can be customized to provide real-time recommendations in an API-centric way. We demonstrate (i) how to set up a real-time movie recommender using the popular MovieLens-100k dataset, and (ii) how to simultaneously support multiple application domains based on the use-case of recommendations in entrepreneurial start-up founding. For that, we differentiate between domains on the item- and system-level. We believe that our demonstration shows a convenient way to adapt, deploy and evaluate a recommender system in an API-centric way. The source-code and documentation that demonstrates how to utilize the configured Uptrendz API is available on GitHub.
Recommendations in a Multi-Domain Setting: Adapting for Customization, Scalability and Real-Time Performance
Mar 02, 2022
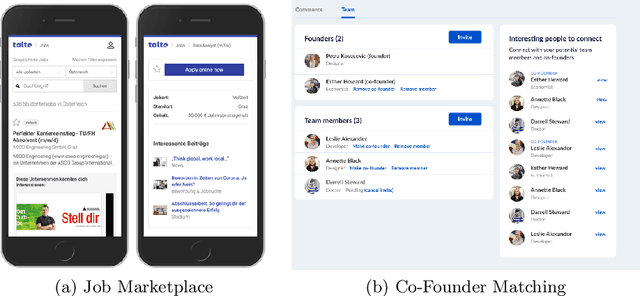
In this industry talk at ECIR'2022, we illustrate how to build a modern recommender system that can serve recommendations in real-time for a diverse set of application domains. Specifically, we present our system architecture that utilizes popular recommendation algorithms from the literature such as Collaborative Filtering, Content-based Filtering as well as various neural embedding approaches (e.g., Doc2Vec, Autoencoders, etc.). We showcase the applicability of our system architecture using two real-world use-cases, namely providing recommendations for the domains of (i) job marketplaces, and (ii) entrepreneurial start-up founding. We strongly believe that our experiences from both research- and industry-oriented settings should be of interest for practitioners in the field of real-time multi-domain recommender systems.
Popularity Bias in Collaborative Filtering-Based Multimedia Recommender Systems
Mar 01, 2022



Multimedia recommender systems suggest media items, e.g., songs, (digital) books and movies, to users by utilizing concepts of traditional recommender systems such as collaborative filtering. In this paper, we investigate a potential issue of such collaborative-filtering based multimedia recommender systems, namely popularity bias that leads to the underrepresentation of unpopular items in the recommendation lists. Therefore, we study four multimedia datasets, i.e., LastFm, MovieLens, BookCrossing and MyAnimeList, that we each split into three user groups differing in their inclination to popularity, i.e., LowPop, MedPop and HighPop. Using these user groups, we evaluate four collaborative filtering-based algorithms with respect to popularity bias on the item and the user level. Our findings are three-fold: firstly, we show that users with little interest into popular items tend to have large user profiles and thus, are important data sources for multimedia recommender systems. Secondly, we find that popular items are recommended more frequently than unpopular ones. Thirdly, we find that users with little interest into popular items receive significantly worse recommendations than users with medium or high interest into popularity.
What Drives Readership? An Online Study on User Interface Types and Popularity Bias Mitigation in News Article Recommendations
Nov 29, 2021
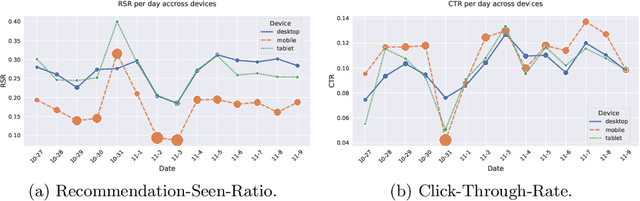
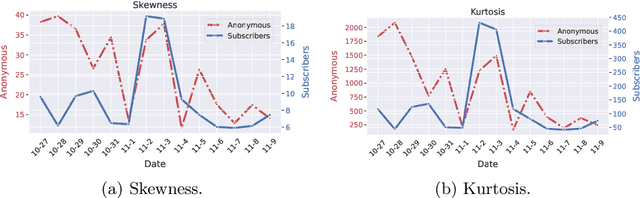
Personalized news recommender systems support readers in finding the right and relevant articles in online news platforms. In this paper, we discuss the introduction of personalized, content-based news recommendations on DiePresse, a popular Austrian online news platform, focusing on two specific aspects: (i) user interface type, and (ii) popularity bias mitigation. Therefore, we conducted a two-weeks online study that started in October 2020, in which we analyzed the impact of recommendations on two user groups, i.e., anonymous and subscribed users, and three user interface types, i.e., on a desktop, mobile and tablet device. With respect to user interface types, we find that the probability of a recommendation to be seen is the highest for desktop devices, while the probability of interacting with recommendations is the highest for mobile devices. With respect to popularity bias mitigation, we find that personalized, content-based news recommendations can lead to a more balanced distribution of news articles' readership popularity in the case of anonymous users. Apart from that, we find that significant events (e.g., the COVID-19 lockdown announcement in Austria and the Vienna terror attack) influence the general consumption behavior of popular articles for both, anonymous and subscribed users.
Empirical Comparison of Graph Embeddings for Trust-Based Collaborative Filtering
Mar 30, 2020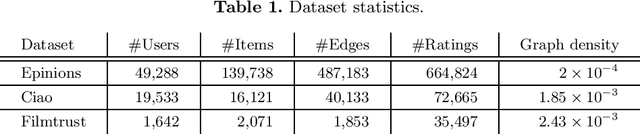
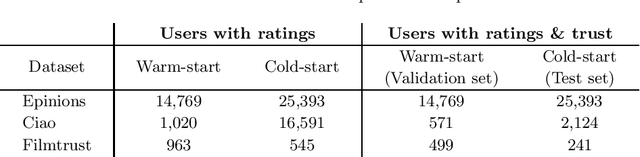
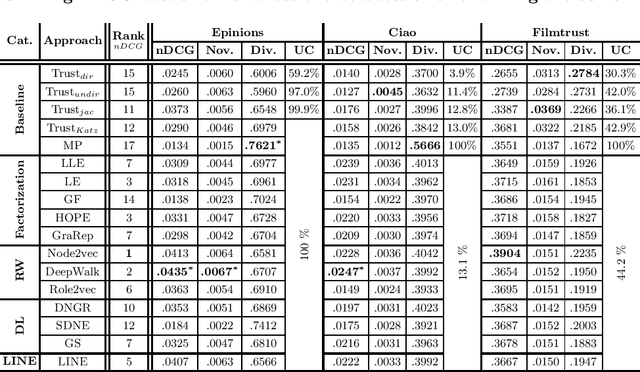
In this work, we study the utility of graph embeddings to generate latent user representations for trust-based collaborative filtering. In a cold-start setting, on three publicly available datasets, we evaluate approaches from four method families: (i) factorization-based, (ii) random walk-based, (iii) deep learning-based, and (iv) the Large-scale Information Network Embedding (LINE) approach. We find that across the four families, random-walk-based approaches consistently achieve the best accuracy. Besides, they result in highly novel and diverse recommendations. Furthermore, our results show that the use of graph embeddings in trust-based collaborative filtering significantly improves user coverage.
Evaluating Tag Recommendations for E-Book Annotation Using a Semantic Similarity Metric
Aug 12, 2019


In this paper, we present our work to support publishers and editors in finding descriptive tags for e-books through tag recommendations. We propose a hybrid tag recommendation system for e-books, which leverages search query terms from Amazon users and e-book metadata, which is assigned by publishers and editors. Our idea is to mimic the vocabulary of users in Amazon, who search for and review e-books, and to combine these search terms with editor tags in a hybrid tag recommendation approach. In total, we evaluate 19 tag recommendation algorithms on the review content of Amazon users, which reflects the readers' vocabulary. Our results show that we can improve the performance of tag recommender systems for e-books both concerning tag recommendation accuracy, diversity as well as a novel semantic similarity metric, which we also propose in this paper.