 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Haet Bhasha aur Diskrimineshun": Phonetic Perturbations in Code-Mixed Hinglish to Red-Team LLMs
May 20, 2025Large Language Models (LLMs) have become increasingly powerful, with multilingual and multimodal capabilities improving by the day. These models are being evaluated through audits, alignment studies and red-teaming efforts to expose model vulnerabilities towards generating harmful, biased and unfair content. Existing red-teaming efforts have previously focused on the English language, using fixed template-based attacks; thus, models continue to be susceptible to multilingual jailbreaking strategies, especially in the multimodal context. In this study, we introduce a novel strategy that leverages code-mixing and phonetic perturbations to jailbreak LLMs for both text and image generation tasks. We also introduce two new jailbreak strategies that show higher effectiveness than baseline strategies. Our work presents a method to effectively bypass safety filters in LLMs while maintaining interpretability by applying phonetic misspellings to sensitive words in code-mixed prompts. Our novel prompts achieve a 99% Attack Success Rate for text generation and 78% for image generation, with Attack Relevance Rate of 100% for text generation and 95% for image generation when using the phonetically perturbed code-mixed prompts. Our interpretability experiments reveal that phonetic perturbations impact word tokenization, leading to jailbreak success. Our study motivates increasing the focus towards more generalizable safety alignment for multilingual multimodal models, especially in real-world settings wherein prompts can have misspelt words.
Exploring Disparity-Accuracy Trade-offs in Face Recognition Systems: The Role of Datasets, Architectures, and Loss Functions
Mar 18, 2025Automated Face Recognition Systems (FRSs), developed using deep learning models, are deployed worldwide for identity verification and facial attribute analysis. The performance of these models is determined by a complex interdependence among the model architecture, optimization/loss function and datasets. Although FRSs have surpassed human-level accuracy, they continue to be disparate against certain demographics. Due to the ubiquity of applications, it is extremely important to understand the impact of the three components -- model architecture, loss function and face image dataset on the accuracy-disparity trade-off to design better, unbiased platforms. In this work, we perform an in-depth analysis of three FRSs for the task of gender prediction, with various architectural modifications resulting in ten deep-learning models coupled with four loss functions and benchmark them on seven face datasets across 266 evaluation configurations. Our results show that all three components have an individual as well as a combined impact on both accuracy and disparity. We identify that datasets have an inherent property that causes them to perform similarly across models, independent of the choice of loss functions. Moreover, the choice of dataset determines the model's perceived bias -- the same model reports bias in opposite directions for three gender-balanced datasets of ``in-the-wild'' face images of popular individuals. Studying the facial embeddings shows that the models are unable to generalize a uniform definition of what constitutes a ``female face'' as opposed to a ``male face'', due to dataset diversity. We provide recommendations to model developers on using our study as a blueprint for model development and subsequent deployment.
DENOASR: Debiasing ASRs through Selective Denoising
Oct 22, 2024Automatic Speech Recognition (ASR) systems have been examined and shown to exhibit biases toward particular groups of individuals, influenced by factors such as demographic traits, accents, and speech styles. Noise can disproportionately impact speakers with certain accents, dialects, or speaking styles, leading to biased error rates. In this work, we introduce a novel framework DENOASR, which is a selective denoising technique to reduce the disparity in the word error rates between the two gender groups, male and female. We find that a combination of two popular speech denoising techniques, viz. DEMUCS and LE, can be effectively used to mitigate ASR disparity without compromising their overall performance. Experiments using two state-of-the-art open-source ASRs - OpenAI WHISPER and NVIDIA NEMO - on multiple benchmark datasets, including TIE, VOX-POPULI, TEDLIUM, and FLEURS, show that there is a promising reduction in the average word error rate gap across the two gender groups. For a given dataset, the denoising is selectively applied on speech samples having speech intelligibility below a certain threshold, estimated using a small validation sample, thus ameliorating the need for large-scale human-written ground-truth transcripts. Our findings suggest that selective denoising can be an elegant approach to mitigate biases in present-day ASR systems.
Breaking the Global North Stereotype: A Global South-centric Benchmark Dataset for Auditing and Mitigating Biases in Facial Recognition Systems
Jul 26, 2024Facial Recognition Systems (FRSs) are being developed and deployed globally at unprecedented rates. Most platforms are designed in a limited set of countries but deployed in worldwide, without adequate checkpoints. This is especially problematic for Global South countries which lack strong legislation to safeguard persons facing disparate performance of these systems. A combination of unavailability of datasets, lack of understanding of FRS functionality and low-resource bias mitigation measures accentuate the problem. In this work, we propose a new face dataset composed of 6,579 unique male and female sportspersons from eight countries around the world. More than 50% of the dataset comprises individuals from the Global South countries and is demographically diverse. To aid adversarial audits and robust model training, each image has four adversarial variants, totaling over 40,000 images. We also benchmark five popular FRSs, both commercial and open-source, for the task of gender prediction (and country prediction for one of the open-source models as an example of red-teaming). Experiments on industrial FRSs reveal accuracies ranging from 98.2%--38.1%, with a large disparity between males and females in the Global South (max difference of 38.5%). Biases are also observed in all FRSs between females of the Global North and South (max difference of ~50%). Grad-CAM analysis identifies the nose, forehead and mouth as the regions of interest on one of the open-source FRSs. Utilizing this insight, we design simple, low-resource bias mitigation solutions using few-shot and novel contrastive learning techniques significantly improving the accuracy with disparity between males and females reducing from 50% to 1.5% in one of the settings. In the red-teaming experiment with the open-source Deepface model, contrastive learning proves more effective than simple fine-tuning.
Auditing the Grid-Based Placement of Private Label Products on E-commerce Search Result Pages
Jul 19, 2024



E-commerce platforms support the needs and livelihoods of their two most important stakeholders -- customers and producers/sellers. Multiple algorithmic systems, like ``search'' systems mediate the interactions between these stakeholders by connecting customers to producers with relevant items. Search results include (i) private label (PL) products that are manufactured/sold by the platform itself, as well as (ii) third-party products on advertised / sponsored and organic positions. In this paper, we systematically quantify the extent of PL product promotion on e-commerce search results for the two largest e-commerce platforms operating in India -- Amazon.in and Flipkart. By analyzing snapshots of search results across the two platforms, we discover high PL promotion on the initial result pages (~ 15% PLs are advertised on the first SERP of Amazon). Both platforms use different strategies to promote their PL products, such as placing more PLs on the advertised positions -- while Amazon places them on the first, middle, and last rows of the search results, Flipkart places them on the first two positions and the (entire) last column of the search results. We discover that these product placement strategies of both platforms conform with existing user attention strategies proposed in the literature. Finally, to supplement the findings from the collected data, we conduct a survey among 68 participants on Amazon Mechanical Turk. The click pattern from our survey shows that users strongly prefer to click on products placed at positions that correspond to the PL products on the search results of Amazon, but not so strongly on Flipkart. The click-through rate follows previously proposed theoretically grounded user attention distribution patterns in a two-dimensional layout.
Mask-up: Investigating Biases in Face Re-identification for Masked Faces
Feb 21, 2024AI based Face Recognition Systems (FRSs) are now widely distributed and deployed as MLaaS solutions all over the world, moreso since the COVID-19 pandemic for tasks ranging from validating individuals' faces while buying SIM cards to surveillance of citizens. Extensive biases have been reported against marginalized groups in these systems and have led to highly discriminatory outcomes. The post-pandemic world has normalized wearing face masks but FRSs have not kept up with the changing times. As a result, these systems are susceptible to mask based face occlusion. In this study, we audit four commercial and nine open-source FRSs for the task of face re-identification between different varieties of masked and unmasked images across five benchmark datasets (total 14,722 images). These simulate a realistic validation/surveillance task as deployed in all major countries around the world. Three of the commercial and five of the open-source FRSs are highly inaccurate; they further perpetuate biases against non-White individuals, with the lowest accuracy being 0%. A survey for the same task with 85 human participants also results in a low accuracy of 40%. Thus a human-in-the-loop moderation in the pipeline does not alleviate the concerns, as has been frequently hypothesized in literature. Our large-scale study shows that developers, lawmakers and users of such services need to rethink the design principles behind FRSs, especially for the task of face re-identification, taking cognizance of observed biases.
Auditing Gender Analyzers on Text Data
Oct 09, 2023AI models have become extremely popular and accessible to the general public. However, they are continuously under the scanner due to their demonstrable biases toward various sections of the society like people of color and non-binary people. In this study, we audit three existing gender analyzers -- uClassify, Readable and HackerFactor, for biases against non-binary individuals. These tools are designed to predict only the cisgender binary labels, which leads to discrimination against non-binary members of the society. We curate two datasets -- Reddit comments (660k) and, Tumblr posts (2.05M) and our experimental evaluation shows that the tools are highly inaccurate with the overall accuracy being ~50% on all platforms. Predictions for non-binary comments on all platforms are mostly female, thus propagating the societal bias that non-binary individuals are effeminate. To address this, we fine-tune a BERT multi-label classifier on the two datasets in multiple combinations, observe an overall performance of ~77% on the most realistically deployable setting and a surprisingly higher performance of 90% for the non-binary class. We also audit ChatGPT using zero-shot prompts on a small dataset (due to high pricing) and observe an average accuracy of 58% for Reddit and Tumblr combined (with overall better results for Reddit). Thus, we show that existing systems, including highly advanced ones like ChatGPT are biased, and need better audits and moderation and, that such societal biases can be addressed and alleviated through simple off-the-shelf models like BERT trained on more gender inclusive datasets.
A Deep Dive into the Disparity of Word Error Rates Across Thousands of NPTEL MOOC Videos
Jul 20, 2023
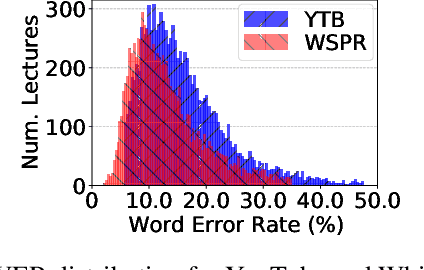


Automatic speech recognition (ASR) systems are designed to transcribe spoken language into written text and find utility in a variety of applications including voice assistants and transcription services. However, it has been observed that state-of-the-art ASR systems which deliver impressive benchmark results, struggle with speakers of certain regions or demographics due to variation in their speech properties. In this work, we describe the curation of a massive speech dataset of 8740 hours consisting of $\sim9.8$K technical lectures in the English language along with their transcripts delivered by instructors representing various parts of Indian demography. The dataset is sourced from the very popular NPTEL MOOC platform. We use the curated dataset to measure the existing disparity in YouTube Automatic Captions and OpenAI Whisper model performance across the diverse demographic traits of speakers in India. While there exists disparity due to gender, native region, age and speech rate of speakers, disparity based on caste is non-existent. We also observe statistically significant disparity across the disciplines of the lectures. These results indicate the need of more inclusive and robust ASR systems and more representational datasets for disparity evaluation in them.
Two-Face: Adversarial Audit of Commercial Face Recognition Systems
Nov 17, 2021


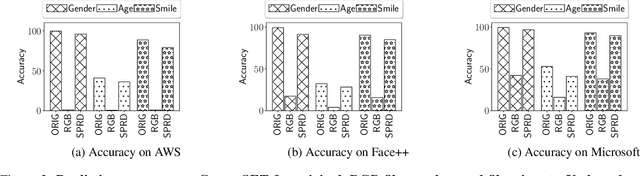
Computer vision applications like automated face detection are used for a variety of purposes ranging from unlocking smart devices to tracking potential persons of interest for surveillance. Audits of these applications have revealed that they tend to be biased against minority groups which result in unfair and concerning societal and political outcomes. Despite multiple studies over time, these biases have not been mitigated completely and have in fact increased for certain tasks like age prediction. While such systems are audited over benchmark datasets, it becomes necessary to evaluate their robustness for adversarial inputs. In this work, we perform an extensive adversarial audit on multiple systems and datasets, making a number of concerning observations - there has been a drop in accuracy for some tasks on CELEBSET dataset since a previous audit. While there still exists a bias in accuracy against individuals from minority groups for multiple datasets, a more worrying observation is that these biases tend to get exorbitantly pronounced with adversarial inputs toward the minority group. We conclude with a discussion on the broader societal impacts in light of these observations and a few suggestions on how to collectively deal with this issue.