 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDENOASR: Debiasing ASRs through Selective Denoising
Oct 22, 2024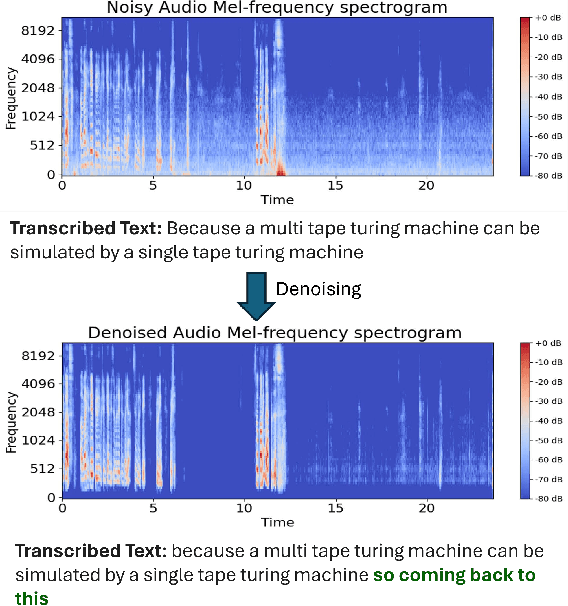
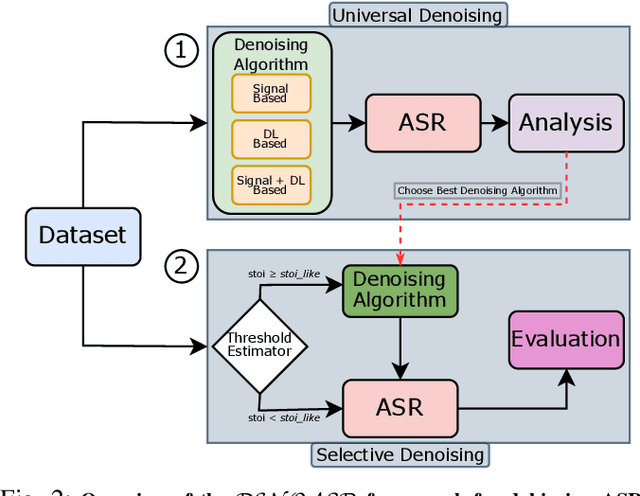
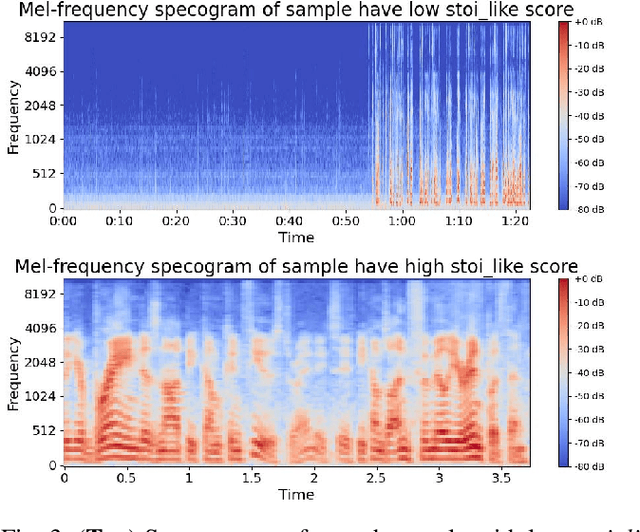
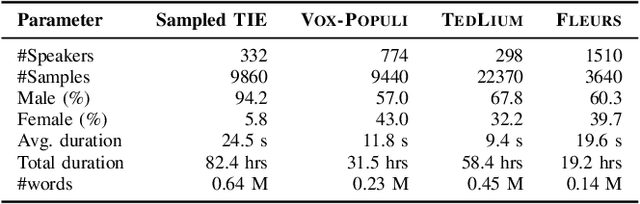
Automatic Speech Recognition (ASR) systems have been examined and shown to exhibit biases toward particular groups of individuals, influenced by factors such as demographic traits, accents, and speech styles. Noise can disproportionately impact speakers with certain accents, dialects, or speaking styles, leading to biased error rates. In this work, we introduce a novel framework DENOASR, which is a selective denoising technique to reduce the disparity in the word error rates between the two gender groups, male and female. We find that a combination of two popular speech denoising techniques, viz. DEMUCS and LE, can be effectively used to mitigate ASR disparity without compromising their overall performance. Experiments using two state-of-the-art open-source ASRs - OpenAI WHISPER and NVIDIA NEMO - on multiple benchmark datasets, including TIE, VOX-POPULI, TEDLIUM, and FLEURS, show that there is a promising reduction in the average word error rate gap across the two gender groups. For a given dataset, the denoising is selectively applied on speech samples having speech intelligibility below a certain threshold, estimated using a small validation sample, thus ameliorating the need for large-scale human-written ground-truth transcripts. Our findings suggest that selective denoising can be an elegant approach to mitigate biases in present-day ASR systems.
A Deep Dive into the Disparity of Word Error Rates Across Thousands of NPTEL MOOC Videos
Jul 20, 2023
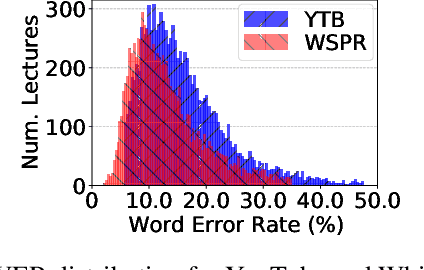


Automatic speech recognition (ASR) systems are designed to transcribe spoken language into written text and find utility in a variety of applications including voice assistants and transcription services. However, it has been observed that state-of-the-art ASR systems which deliver impressive benchmark results, struggle with speakers of certain regions or demographics due to variation in their speech properties. In this work, we describe the curation of a massive speech dataset of 8740 hours consisting of $\sim9.8$K technical lectures in the English language along with their transcripts delivered by instructors representing various parts of Indian demography. The dataset is sourced from the very popular NPTEL MOOC platform. We use the curated dataset to measure the existing disparity in YouTube Automatic Captions and OpenAI Whisper model performance across the diverse demographic traits of speakers in India. While there exists disparity due to gender, native region, age and speech rate of speakers, disparity based on caste is non-existent. We also observe statistically significant disparity across the disciplines of the lectures. These results indicate the need of more inclusive and robust ASR systems and more representational datasets for disparity evaluation in them.