 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT
Feb 03, 2026To enable personalized and context-aware interactions, conversational AI systems have introduced a new mechanism: Memory. Memory creates what we refer to as the Algorithmic Self-portrait - a new form of personalization derived from users' self-disclosed information divulged within private conversations. While memory enables more coherent exchanges, the underlying processes of memory creation remain opaque, raising critical questions about data sensitivity, user agency, and the fidelity of the resulting portrait. To bridge this research gap, we analyze 2,050 memory entries from 80 real-world ChatGPT users. Our analyses reveal three key findings: (1) A striking 96% of memories in our dataset are created unilaterally by the conversational system, potentially shifting agency away from the user; (2) Memories, in our dataset, contain a rich mix of GDPR-defined personal data (in 28% memories) along with psychological insights about participants (in 52% memories); and (3)~A significant majority of the memories (84%) are directly grounded in user context, indicating faithful representation of the conversations. Finally, we introduce a framework-Attribution Shield-that anticipates these inferences, alerts about potentially sensitive memory inferences, and suggests query reformulations to protect personal information without sacrificing utility.
Sponsored is the New Organic: Implications of Sponsored Results on Quality of Search Results in the Amazon Marketplace
Jul 26, 2024



Interleaving sponsored results (advertisements) amongst organic results on search engine result pages (SERP) has become a common practice across multiple digital platforms. Advertisements have catered to consumer satisfaction and fostered competition in digital public spaces; making them an appealing gateway for businesses to reach their consumers. However, especially in the context of digital marketplaces, due to the competitive nature of the sponsored results with the organic ones, multiple unwanted repercussions have surfaced affecting different stakeholders. From the consumers' perspective the sponsored ads/results may cause degradation of search quality and nudge consumers to potentially irrelevant and costlier products. The sponsored ads may also affect the level playing field of the competition in the marketplaces among sellers. To understand and unravel these potential concerns, we analyse the Amazon digital marketplace in four different countries by simulating 4,800 search operations. Our analyses over SERPs consisting 2M organic and 638K sponsored results show items with poor organic ranks (beyond 100th position) appear as sponsored results even before the top organic results on the first page of Amazon SERP. Moreover, we also observe that in majority of the cases, these top sponsored results are costlier and are of poorer quality than the top organic results. We believe these observations can motivate researchers for further deliberation to bring in more transparency and guard rails in the advertising practices followed in digital marketplaces.
Breaking the Global North Stereotype: A Global South-centric Benchmark Dataset for Auditing and Mitigating Biases in Facial Recognition Systems
Jul 26, 2024Facial Recognition Systems (FRSs) are being developed and deployed globally at unprecedented rates. Most platforms are designed in a limited set of countries but deployed in worldwide, without adequate checkpoints. This is especially problematic for Global South countries which lack strong legislation to safeguard persons facing disparate performance of these systems. A combination of unavailability of datasets, lack of understanding of FRS functionality and low-resource bias mitigation measures accentuate the problem. In this work, we propose a new face dataset composed of 6,579 unique male and female sportspersons from eight countries around the world. More than 50% of the dataset comprises individuals from the Global South countries and is demographically diverse. To aid adversarial audits and robust model training, each image has four adversarial variants, totaling over 40,000 images. We also benchmark five popular FRSs, both commercial and open-source, for the task of gender prediction (and country prediction for one of the open-source models as an example of red-teaming). Experiments on industrial FRSs reveal accuracies ranging from 98.2%--38.1%, with a large disparity between males and females in the Global South (max difference of 38.5%). Biases are also observed in all FRSs between females of the Global North and South (max difference of ~50%). Grad-CAM analysis identifies the nose, forehead and mouth as the regions of interest on one of the open-source FRSs. Utilizing this insight, we design simple, low-resource bias mitigation solutions using few-shot and novel contrastive learning techniques significantly improving the accuracy with disparity between males and females reducing from 50% to 1.5% in one of the settings. In the red-teaming experiment with the open-source Deepface model, contrastive learning proves more effective than simple fine-tuning.
Auditing the Grid-Based Placement of Private Label Products on E-commerce Search Result Pages
Jul 19, 2024



E-commerce platforms support the needs and livelihoods of their two most important stakeholders -- customers and producers/sellers. Multiple algorithmic systems, like ``search'' systems mediate the interactions between these stakeholders by connecting customers to producers with relevant items. Search results include (i) private label (PL) products that are manufactured/sold by the platform itself, as well as (ii) third-party products on advertised / sponsored and organic positions. In this paper, we systematically quantify the extent of PL product promotion on e-commerce search results for the two largest e-commerce platforms operating in India -- Amazon.in and Flipkart. By analyzing snapshots of search results across the two platforms, we discover high PL promotion on the initial result pages (~ 15% PLs are advertised on the first SERP of Amazon). Both platforms use different strategies to promote their PL products, such as placing more PLs on the advertised positions -- while Amazon places them on the first, middle, and last rows of the search results, Flipkart places them on the first two positions and the (entire) last column of the search results. We discover that these product placement strategies of both platforms conform with existing user attention strategies proposed in the literature. Finally, to supplement the findings from the collected data, we conduct a survey among 68 participants on Amazon Mechanical Turk. The click pattern from our survey shows that users strongly prefer to click on products placed at positions that correspond to the PL products on the search results of Amazon, but not so strongly on Flipkart. The click-through rate follows previously proposed theoretically grounded user attention distribution patterns in a two-dimensional layout.
Investigating Nudges toward Related Sellers on E-commerce Marketplaces: A Case Study on Amazon
Jul 01, 2024



E-commerce marketplaces provide business opportunities to millions of sellers worldwide. Some of these sellers have special relationships with the marketplace by virtue of using their subsidiary services (e.g., fulfillment and/or shipping services provided by the marketplace) -- we refer to such sellers collectively as Related Sellers. When multiple sellers offer to sell the same product, the marketplace helps a customer in selecting an offer (by a seller) through (a) a default offer selection algorithm, (b) showing features about each of the offers and the corresponding sellers (price, seller performance metrics, seller's number of ratings etc.), and (c) finally evaluating the sellers along these features. In this paper, we perform an end-to-end investigation into how the above apparatus can nudge customers toward the Related Sellers on Amazon's four different marketplaces in India, USA, Germany and France. We find that given explicit choices, customers' preferred offers and algorithmically selected offers can be significantly different. We highlight that Amazon is adopting different performance metric evaluation policies for different sellers, potentially benefiting Related Sellers. For instance, such policies result in notable discrepancy between the actual performance metric and the presented performance metric of Related Sellers. We further observe that among the seller-centric features visible to customers, sellers' number of ratings influences their decisions the most, yet it may not reflect the true quality of service by the seller, rather reflecting the scale at which the seller operates, thereby implicitly steering customers toward larger Related Sellers. Moreover, when customers are shown the rectified metrics for the different sellers, their preference toward Related Sellers is almost halved.
Antitrust, Amazon, and Algorithmic Auditing
Mar 27, 2024



In digital markets, antitrust law and special regulations aim to ensure that markets remain competitive despite the dominating role that digital platforms play today in everyone's life. Unlike traditional markets, market participant behavior is easily observable in these markets. We present a series of empirical investigations into the extent to which Amazon engages in practices that are typically described as self-preferencing. We discuss how the computer science tools used in this paper can be used in a regulatory environment that is based on algorithmic auditing and requires regulating digital markets at scale.
FaiRIR: Mitigating Exposure Bias from Related Item Recommendations in Two-Sided Platforms
Apr 01, 2022



Related Item Recommendations (RIRs) are ubiquitous in most online platforms today, including e-commerce and content streaming sites. These recommendations not only help users compare items related to a given item, but also play a major role in bringing traffic to individual items, thus deciding the exposure that different items receive. With a growing number of people depending on such platforms to earn their livelihood, it is important to understand whether different items are receiving their desired exposure. To this end, our experiments on multiple real-world RIR datasets reveal that the existing RIR algorithms often result in very skewed exposure distribution of items, and the quality of items is not a plausible explanation for such skew in exposure. To mitigate this exposure bias, we introduce multiple flexible interventions (FaiRIR) in the RIR pipeline. We instantiate these mechanisms with two well-known algorithms for constructing related item recommendations -- rating-SVD and item2vec -- and show on real-world data that our mechanisms allow for a fine-grained control on the exposure distribution, often at a small or no cost in terms of recommendation quality, measured in terms of relatedness and user satisfaction.
Alexa, in you, I trust! Fairness and Interpretability Issues in E-commerce Search through Smart Speakers
Feb 09, 2022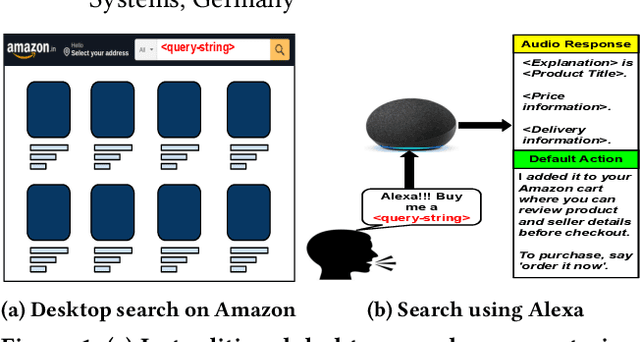


In traditional (desktop) e-commerce search, a customer issues a specific query and the system returns a ranked list of products in order of relevance to the query. An increasingly popular alternative in e-commerce search is to issue a voice-query to a smart speaker (e.g., Amazon Echo) powered by a voice assistant (VA, e.g., Alexa). In this situation, the VA usually spells out the details of only one product, an explanation citing the reason for its selection, and a default action of adding the product to the customer's cart. This reduced autonomy of the customer in the choice of a product during voice-search makes it necessary for a VA to be far more responsible and trustworthy in its explanation and default action. In this paper, we ask whether the explanation presented for a product selection by the Alexa VA installed on an Amazon Echo device is consistent with human understanding as well as with the observations on other traditional mediums (e.g., desktop ecommerce search). Through a user survey, we find that in 81% cases the interpretation of 'a top result' by the users is different from that of Alexa. While investigating for the fairness of the default action, we observe that over a set of as many as 1000 queries, in nearly 68% cases, there exist one or more products which are more relevant (as per Amazon's own desktop search results) than the product chosen by Alexa. Finally, we conducted a survey over 30 queries for which the Alexa-selected product was different from the top desktop search result, and observed that in nearly 73% cases, the participants preferred the top desktop search result as opposed to the product chosen by Alexa. Our results raise several concerns and necessitates more discussions around the related fairness and interpretability issues of VAs for e-commerce search.
Two-Face: Adversarial Audit of Commercial Face Recognition Systems
Nov 17, 2021


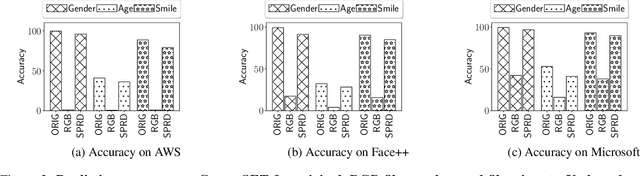
Computer vision applications like automated face detection are used for a variety of purposes ranging from unlocking smart devices to tracking potential persons of interest for surveillance. Audits of these applications have revealed that they tend to be biased against minority groups which result in unfair and concerning societal and political outcomes. Despite multiple studies over time, these biases have not been mitigated completely and have in fact increased for certain tasks like age prediction. While such systems are audited over benchmark datasets, it becomes necessary to evaluate their robustness for adversarial inputs. In this work, we perform an extensive adversarial audit on multiple systems and datasets, making a number of concerning observations - there has been a drop in accuracy for some tasks on CELEBSET dataset since a previous audit. While there still exists a bias in accuracy against individuals from minority groups for multiple datasets, a more worrying observation is that these biases tend to get exorbitantly pronounced with adversarial inputs toward the minority group. We conclude with a discussion on the broader societal impacts in light of these observations and a few suggestions on how to collectively deal with this issue.
Fairness for Whom? Understanding the Reader's Perception of Fairness in Text Summarization
Feb 02, 2021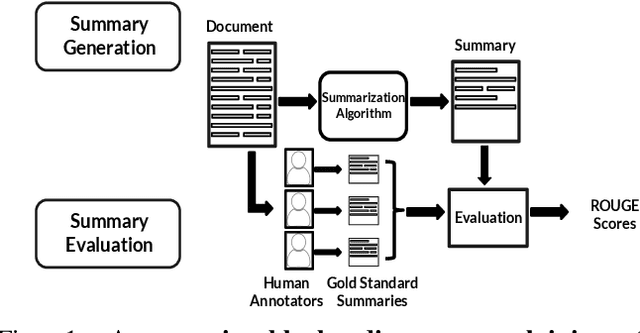

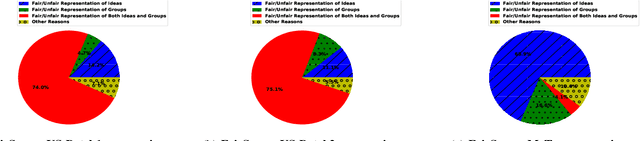

With the surge in user-generated textual information, there has been a recent increase in the use of summarization algorithms for providing an overview of the extensive content. Traditional metrics for evaluation of these algorithms (e.g. ROUGE scores) rely on matching algorithmic summaries to human-generated ones. However, it has been shown that when the textual contents are heterogeneous, e.g., when they come from different socially salient groups, most existing summarization algorithms represent the social groups very differently compared to their distribution in the original data. To mitigate such adverse impacts, some fairness-preserving summarization algorithms have also been proposed. All of these studies have considered normative notions of fairness from the perspective of writers of the contents, neglecting the readers' perceptions of the underlying fairness notions. To bridge this gap, in this work, we study the interplay between the fairness notions and how readers perceive them in textual summaries. Through our experiments, we show that reader's perception of fairness is often context-sensitive. Moreover, standard ROUGE evaluation metrics are unable to quantify the perceived (un)fairness of the summaries. To this end, we propose a human-in-the-loop metric and an automated graph-based methodology to quantify the perceived bias in textual summaries. We demonstrate their utility by quantifying the (un)fairness of several summaries of heterogeneous socio-political microblog datasets.