 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative SGD with Dynamic Mixing Matrices
Aug 21, 2025One of the most common methods to train machine learning algorithms today is the stochastic gradient descent (SGD). In a distributed setting, SGD-based algorithms have been shown to converge theoretically under specific circumstances. A substantial number of works in the distributed SGD setting assume a fixed topology for the edge devices. These papers also assume that the contribution of nodes to the global model is uniform. However, experiments have shown that such assumptions are suboptimal and a non uniform aggregation strategy coupled with a dynamically shifting topology and client selection can significantly improve the performance of such models. This paper details a unified framework that covers several Local-Update SGD-based distributed algorithms with dynamic topologies and provides improved or matching theoretical guarantees on convergence compared to existing work.
Diversity matters: Robustness of bias measurements in Wikidata
Feb 27, 2023With the widespread use of knowledge graphs (KG) in various automated AI systems and applications, it is very important to ensure that information retrieval algorithms leveraging them are free from societal biases. Previous works have depicted biases that persist in KGs, as well as employed several metrics for measuring the biases. However, such studies lack the systematic exploration of the sensitivity of the bias measurements, through varying sources of data, or the embedding algorithms used. To address this research gap, in this work, we present a holistic analysis of bias measurement on the knowledge graph. First, we attempt to reveal data biases that surface in Wikidata for thirteen different demographics selected from seven continents. Next, we attempt to unfold the variance in the detection of biases by two different knowledge graph embedding algorithms - TransE and ComplEx. We conduct our extensive experiments on a large number of occupations sampled from the thirteen demographics with respect to the sensitive attribute, i.e., gender. Our results show that the inherent data bias that persists in KG can be altered by specific algorithm bias as incorporated by KG embedding learning algorithms. Further, we show that the choice of the state-of-the-art KG embedding algorithm has a strong impact on the ranking of biased occupations irrespective of gender. We observe that the similarity of the biased occupations across demographics is minimal which reflects the socio-cultural differences around the globe. We believe that this full-scale audit of the bias measurement pipeline will raise awareness among the community while deriving insights related to design choices of data and algorithms both and refrain from the popular dogma of ``one-size-fits-all''.
* 11 pages
Quality change: norm or exception? Measurement, Analysis and Detection of Quality Change in Wikipedia
Nov 02, 2021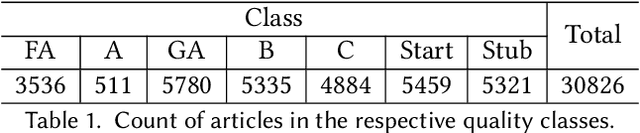
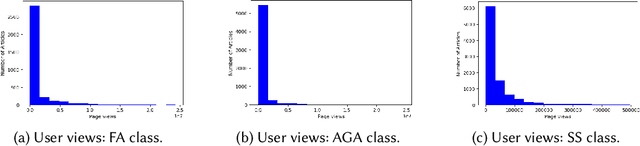

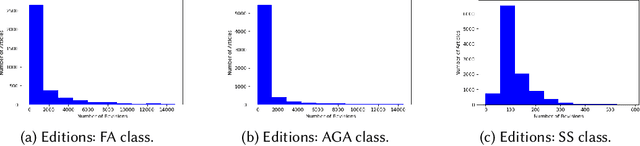
Wikipedia has been turned into an immensely popular crowd-sourced encyclopedia for information dissemination on numerous versatile topics in the form of subscription free content. It allows anyone to contribute so that the articles remain comprehensive and updated. For enrichment of content without compromising standards, the Wikipedia community enumerates a detailed set of guidelines, which should be followed. Based on these, articles are categorized into several quality classes by the Wikipedia editors with increasing adherence to guidelines. This quality assessment task by editors is laborious as well as demands platform expertise. As a first objective, in this paper, we study evolution of a Wikipedia article with respect to such quality scales. Our results show novel non-intuitive patterns emerging from this exploration. As a second objective we attempt to develop an automated data driven approach for the detection of the early signals influencing the quality change of articles. We posit this as a change point detection problem whereby we represent an article as a time series of consecutive revisions and encode every revision by a set of intuitive features. Finally, various change point detection algorithms are used to efficiently and accurately detect the future change points. We also perform various ablation studies to understand which group of features are most effective in identifying the change points. To the best of our knowledge, this is the first work that rigorously explores English Wikipedia article quality life cycle from the perspective of quality indicators and provides a novel unsupervised page level approach to detect quality switch, which can help in automatic content monitoring in Wikipedia thus contributing significantly to the CSCW community.
When expertise gone missing: Uncovering the loss of prolific contributors in Wikipedia
Sep 21, 2021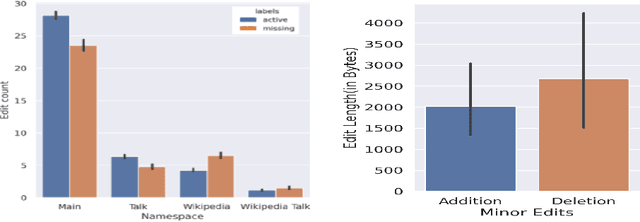

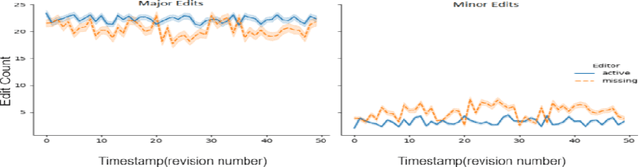

Success of planetary-scale online collaborative platforms such as Wikipedia is hinged on active and continued participation of its voluntary contributors. The phenomenal success of Wikipedia as a valued multilingual source of information is a testament to the possibilities of collective intelligence. Specifically, the sustained and prudent contributions by the experienced prolific editors play a crucial role to operate the platform smoothly for decades. However, it has been brought to light that growth of Wikipedia is stagnating in terms of the number of editors that faces steady decline over time. This decreasing productivity and ever increasing attrition rate in both newcomer and experienced editors is a major concern for not only the future of this platform but also for several industry-scale information retrieval systems such as Siri, Alexa which depend on Wikipedia as knowledge store. In this paper, we have studied the ongoing crisis in which experienced and prolific editors withdraw. We performed extensive analysis of the editor activities and their language usage to identify features that can forecast prolific Wikipedians, who are at risk of ceasing voluntary services. To the best of our knowledge, this is the first work which proposes a scalable prediction pipeline, towards detecting the prolific Wikipedians, who might be at a risk of retiring from the platform and, thereby, can potentially enable moderators to launch appropriate incentive mechanisms to retain such `would-be missing' valued Wikipedians.
StRE: Self Attentive Edit Quality Prediction in Wikipedia
Jun 11, 2019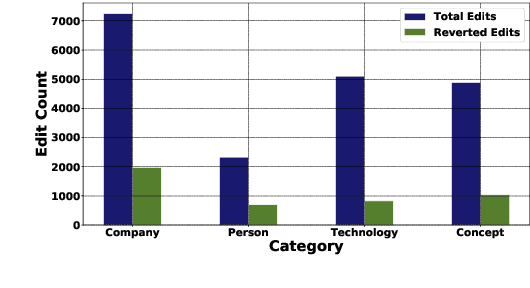

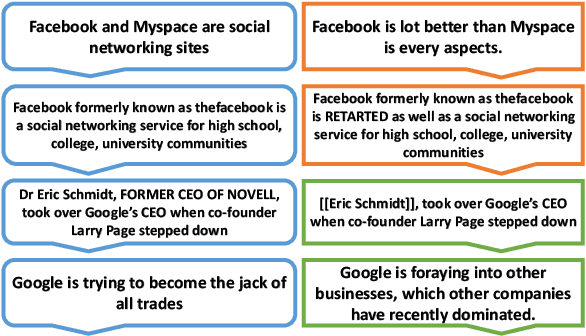
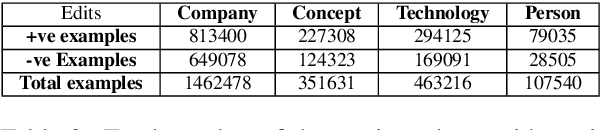
Wikipedia can easily be justified as a behemoth, considering the sheer volume of content that is added or removed every minute to its several projects. This creates an immense scope, in the field of natural language processing towards developing automated tools for content moderation and review. In this paper we propose Self Attentive Revision Encoder (StRE) which leverages orthographic similarity of lexical units toward predicting the quality of new edits. In contrast to existing propositions which primarily employ features like page reputation, editor activity or rule based heuristics, we utilize the textual content of the edits which, we believe contains superior signatures of their quality. More specifically, we deploy deep encoders to generate representations of the edits from its text content, which we then leverage to infer quality. We further contribute a novel dataset containing 21M revisions across 32K Wikipedia pages and demonstrate that StRE outperforms existing methods by a significant margin at least 17% and at most 103%. Our pretrained model achieves such result after retraining on a set as small as 20% of the edits in a wikipage. This, to the best of our knowledge, is also the first attempt towards employing deep language models to the enormous domain of automated content moderation and review in Wikipedia.