 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity matters: Robustness of bias measurements in Wikidata
Feb 27, 2023With the widespread use of knowledge graphs (KG) in various automated AI systems and applications, it is very important to ensure that information retrieval algorithms leveraging them are free from societal biases. Previous works have depicted biases that persist in KGs, as well as employed several metrics for measuring the biases. However, such studies lack the systematic exploration of the sensitivity of the bias measurements, through varying sources of data, or the embedding algorithms used. To address this research gap, in this work, we present a holistic analysis of bias measurement on the knowledge graph. First, we attempt to reveal data biases that surface in Wikidata for thirteen different demographics selected from seven continents. Next, we attempt to unfold the variance in the detection of biases by two different knowledge graph embedding algorithms - TransE and ComplEx. We conduct our extensive experiments on a large number of occupations sampled from the thirteen demographics with respect to the sensitive attribute, i.e., gender. Our results show that the inherent data bias that persists in KG can be altered by specific algorithm bias as incorporated by KG embedding learning algorithms. Further, we show that the choice of the state-of-the-art KG embedding algorithm has a strong impact on the ranking of biased occupations irrespective of gender. We observe that the similarity of the biased occupations across demographics is minimal which reflects the socio-cultural differences around the globe. We believe that this full-scale audit of the bias measurement pipeline will raise awareness among the community while deriving insights related to design choices of data and algorithms both and refrain from the popular dogma of ``one-size-fits-all''.
* 11 pages
VFNet: A Convolutional Architecture for Accent Classification
Oct 15, 2019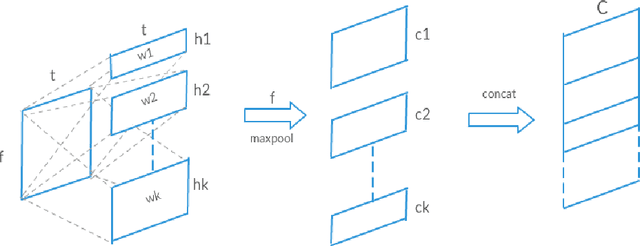
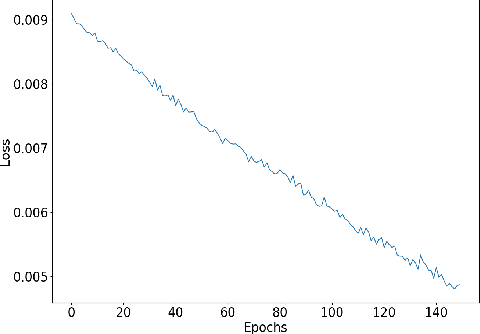
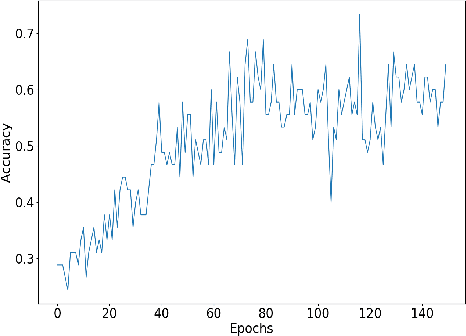
Understanding accent is an issue which can derail any human-machine interaction. Accent classification makes this task easier by identifying the accent being spoken by a person so that the correct words being spoken can be identified by further processing, since same noises can mean entirely different words in different accents of the same language. In this paper, we present VFNet (Variable Filter Net), a convolutional neural network (CNN) based architecture which captures a hierarchy of features to beat the previous benchmarks of accent classification, through a novel and elegant technique of applying variable filter sizes along the frequency band of the audio utterances.
Autoencoder Based Architecture For Fast & Real Time Audio Style Transfer
Dec 26, 2018
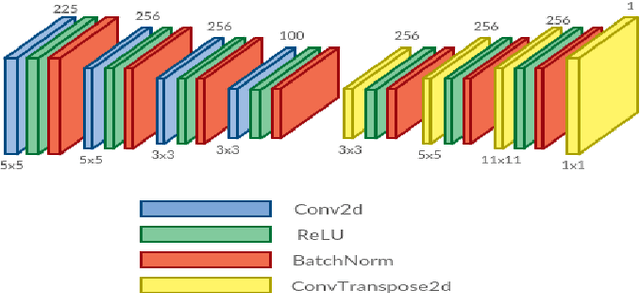
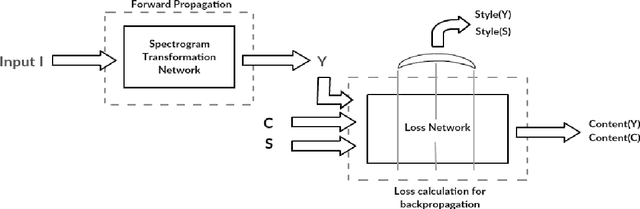

Recently, there has been great interest in the field of audio style transfer, where a stylized audio is generated by imposing the style of a reference audio on the content of a target audio. We improve on the current approaches which use neural networks to extract the content and the style of the audio signal and propose a new autoencoder based architecture for the task. This network generates a stylized audio for a content audio in a single forward pass. The proposed network architecture proves to be advantageous over the quality of audio produced and the time taken to train the network. The network is experimented on speech signals to confirm the validity of our proposal.