 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFNet: A Convolutional Architecture for Accent Classification
Oct 15, 2019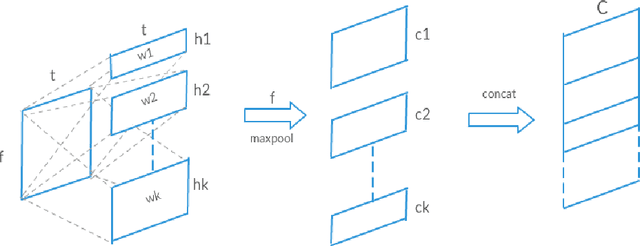
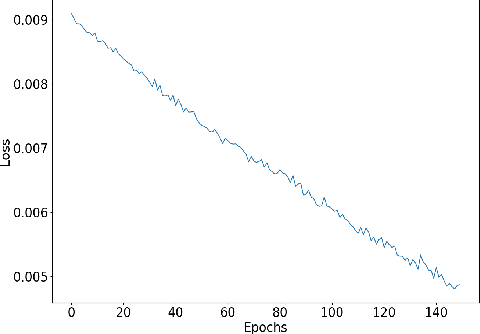
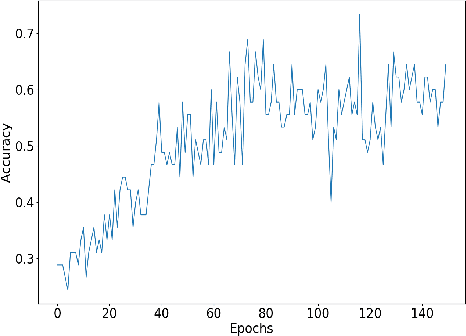
Understanding accent is an issue which can derail any human-machine interaction. Accent classification makes this task easier by identifying the accent being spoken by a person so that the correct words being spoken can be identified by further processing, since same noises can mean entirely different words in different accents of the same language. In this paper, we present VFNet (Variable Filter Net), a convolutional neural network (CNN) based architecture which captures a hierarchy of features to beat the previous benchmarks of accent classification, through a novel and elegant technique of applying variable filter sizes along the frequency band of the audio utterances.
A Short Survey On Memory Based Reinforcement Learning
Apr 14, 2019
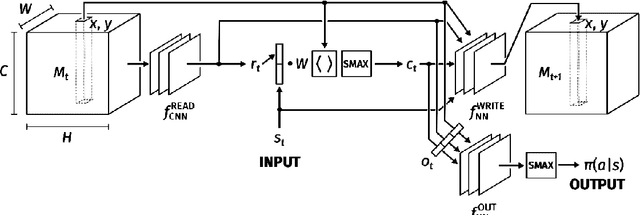
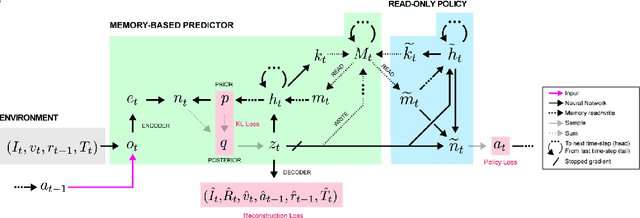
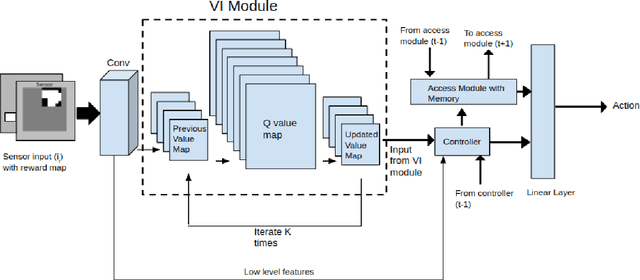
Reinforcement learning (RL) is a branch of machine learning which is employed to solve various sequential decision making problems without proper supervision. Due to the recent advancement of deep learning, the newly proposed Deep-RL algorithms have been able to perform extremely well in sophisticated high-dimensional environments. However, even after successes in many domains, one of the major challenge in these approaches is the high magnitude of interactions with the environment required for efficient decision making. Seeking inspiration from the brain, this problem can be solved by incorporating instance based learning by biasing the decision making on the memories of high rewarding experiences. This paper reviews various recent reinforcement learning methods which incorporate external memory to solve decision making and a survey of them is presented. We provide an overview of the different methods - along with their advantages and disadvantages, applications and the standard experimentation settings used for memory based models. This review hopes to be a helpful resource to provide key insight of the recent advances in the field and provide help in further future development of it.
Autoencoder Based Architecture For Fast & Real Time Audio Style Transfer
Dec 26, 2018
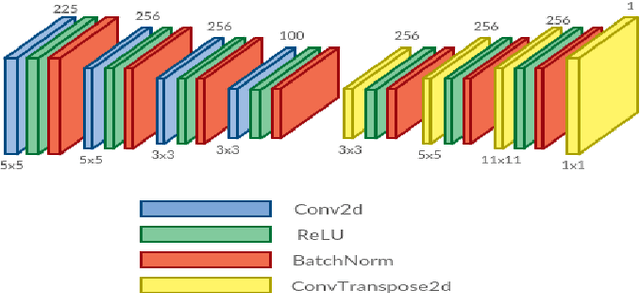
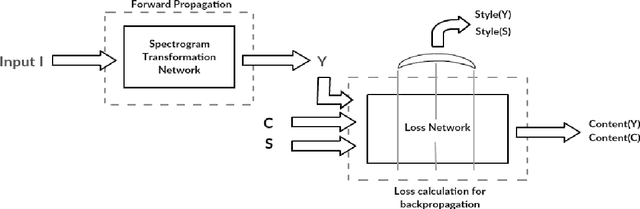

Recently, there has been great interest in the field of audio style transfer, where a stylized audio is generated by imposing the style of a reference audio on the content of a target audio. We improve on the current approaches which use neural networks to extract the content and the style of the audio signal and propose a new autoencoder based architecture for the task. This network generates a stylized audio for a content audio in a single forward pass. The proposed network architecture proves to be advantageous over the quality of audio produced and the time taken to train the network. The network is experimented on speech signals to confirm the validity of our proposal.