Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFNet: A Convolutional Architecture for Accent Classification
Paper and Code
Oct 15, 2019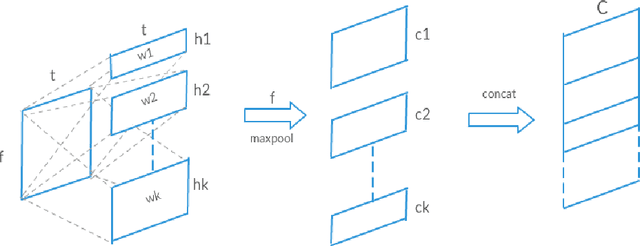
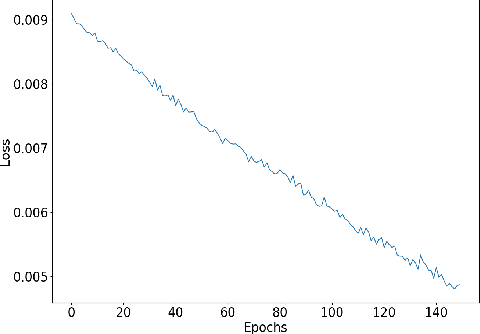
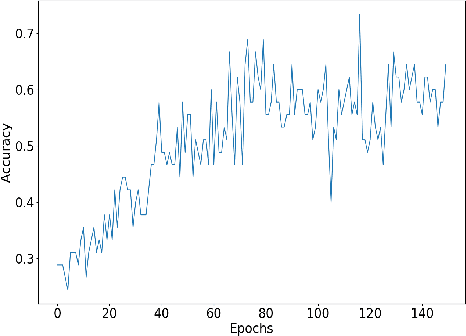
Understanding accent is an issue which can derail any human-machine interaction. Accent classification makes this task easier by identifying the accent being spoken by a person so that the correct words being spoken can be identified by further processing, since same noises can mean entirely different words in different accents of the same language. In this paper, we present VFNet (Variable Filter Net), a convolutional neural network (CNN) based architecture which captures a hierarchy of features to beat the previous benchmarks of accent classification, through a novel and elegant technique of applying variable filter sizes along the frequency band of the audio utterances.
* Accepted at IEEE INDICON 2019
View paper on