 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Understanding For Video Question Answering
Jul 23, 2024Video Question Answering is a challenging task, which requires the model to reason over multiple frames and understand the interaction between different objects to answer questions based on the context provided within the video, especially in datasets like NExT-QA (Xiao et al., 2021a) which emphasize on causal and temporal questions. Previous approaches leverage either sub-sampled information or causal intervention techniques along with complete video features to tackle the NExT-QA task. In this work we elicit the limitations of these approaches and propose solutions along four novel directions of improvements on theNExT-QA dataset. Our approaches attempts to compensate for the shortcomings in the previous works by systematically attacking each of these problems by smartly sampling frames, explicitly encoding actions and creating interventions that challenge the understanding of the model. Overall, for both single-frame (+6.3%) and complete-video (+1.1%) based approaches, we obtain the state-of-the-art results on NExT-QA dataset.
Diversity matters: Robustness of bias measurements in Wikidata
Feb 27, 2023With the widespread use of knowledge graphs (KG) in various automated AI systems and applications, it is very important to ensure that information retrieval algorithms leveraging them are free from societal biases. Previous works have depicted biases that persist in KGs, as well as employed several metrics for measuring the biases. However, such studies lack the systematic exploration of the sensitivity of the bias measurements, through varying sources of data, or the embedding algorithms used. To address this research gap, in this work, we present a holistic analysis of bias measurement on the knowledge graph. First, we attempt to reveal data biases that surface in Wikidata for thirteen different demographics selected from seven continents. Next, we attempt to unfold the variance in the detection of biases by two different knowledge graph embedding algorithms - TransE and ComplEx. We conduct our extensive experiments on a large number of occupations sampled from the thirteen demographics with respect to the sensitive attribute, i.e., gender. Our results show that the inherent data bias that persists in KG can be altered by specific algorithm bias as incorporated by KG embedding learning algorithms. Further, we show that the choice of the state-of-the-art KG embedding algorithm has a strong impact on the ranking of biased occupations irrespective of gender. We observe that the similarity of the biased occupations across demographics is minimal which reflects the socio-cultural differences around the globe. We believe that this full-scale audit of the bias measurement pipeline will raise awareness among the community while deriving insights related to design choices of data and algorithms both and refrain from the popular dogma of ``one-size-fits-all''.
* 11 pages
Sentiment Analysis: Predicting Yelp Scores
Jan 20, 2022In this work, we predict the sentiment of restaurant reviews based on a subset of the Yelp Open Dataset. We utilize the meta features and text available in the dataset and evaluate several machine learning and state-of-the-art deep learning approaches for the prediction task. Through several qualitative experiments, we show the success of the deep models with attention mechanism in learning a balanced model for reviews across different restaurants. Finally, we propose a novel Multi-tasked joint BERT model that improves the overall classification performance.
Quality change: norm or exception? Measurement, Analysis and Detection of Quality Change in Wikipedia
Nov 02, 2021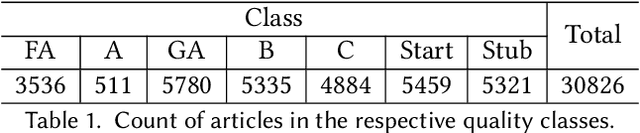
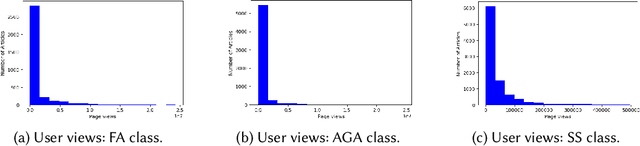

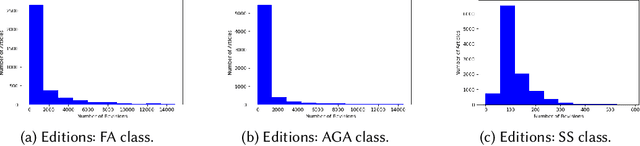
Wikipedia has been turned into an immensely popular crowd-sourced encyclopedia for information dissemination on numerous versatile topics in the form of subscription free content. It allows anyone to contribute so that the articles remain comprehensive and updated. For enrichment of content without compromising standards, the Wikipedia community enumerates a detailed set of guidelines, which should be followed. Based on these, articles are categorized into several quality classes by the Wikipedia editors with increasing adherence to guidelines. This quality assessment task by editors is laborious as well as demands platform expertise. As a first objective, in this paper, we study evolution of a Wikipedia article with respect to such quality scales. Our results show novel non-intuitive patterns emerging from this exploration. As a second objective we attempt to develop an automated data driven approach for the detection of the early signals influencing the quality change of articles. We posit this as a change point detection problem whereby we represent an article as a time series of consecutive revisions and encode every revision by a set of intuitive features. Finally, various change point detection algorithms are used to efficiently and accurately detect the future change points. We also perform various ablation studies to understand which group of features are most effective in identifying the change points. To the best of our knowledge, this is the first work that rigorously explores English Wikipedia article quality life cycle from the perspective of quality indicators and provides a novel unsupervised page level approach to detect quality switch, which can help in automatic content monitoring in Wikipedia thus contributing significantly to the CSCW community.
OPAD: An Optimized Policy-based Active Learning Framework for Document Content Analysis
Oct 07, 2021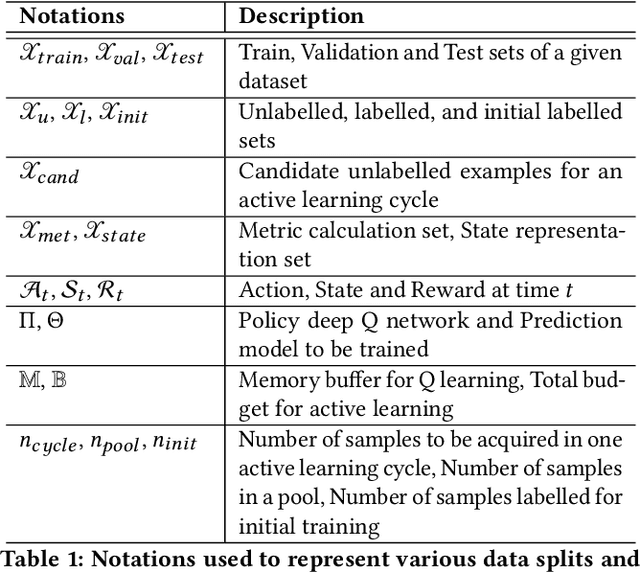
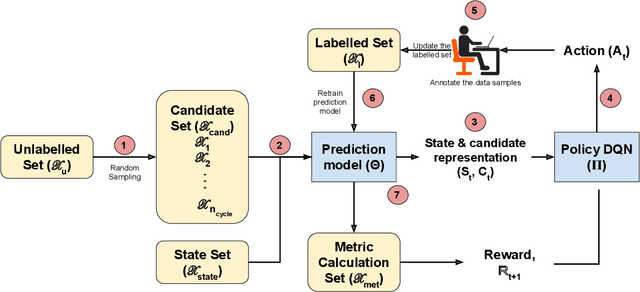
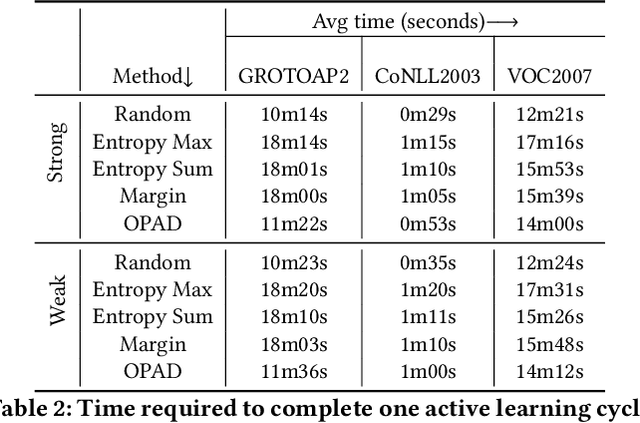
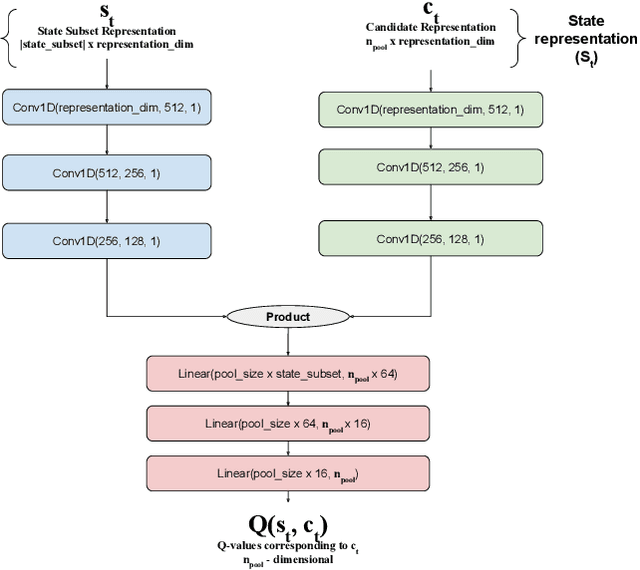
Documents are central to many business systems, and include forms, reports, contracts, invoices or purchase orders. The information in documents is typically in natural language, but can be organized in various layouts and formats. There have been recent spurt of interest in understanding document content with novel deep learning architectures. However, document understanding tasks need dense information annotations, which are costly to scale and generalize. Several active learning techniques have been proposed to reduce the overall budget of annotation while maintaining the performance of the underlying deep learning model. However, most of these techniques work only for classification problems. But content detection is a more complex task, and has been scarcely explored in active learning literature. In this paper, we propose \textit{OPAD}, a novel framework using reinforcement policy for active learning in content detection tasks for documents. The proposed framework learns the acquisition function to decide the samples to be selected while optimizing performance metrics that the tasks typically have. Furthermore, we extend to weak labelling scenarios to further reduce the cost of annotation significantly. We propose novel rewards to account for class imbalance and user feedback in the annotation interface, to improve the active learning method. We show superior performance of the proposed \textit{OPAD} framework for active learning for various tasks related to document understanding like layout parsing, object detection and named entity recognition. Ablation studies for human feedback and class imbalance rewards are presented, along with a comparison of annotation times for different approaches.
When expertise gone missing: Uncovering the loss of prolific contributors in Wikipedia
Sep 21, 2021

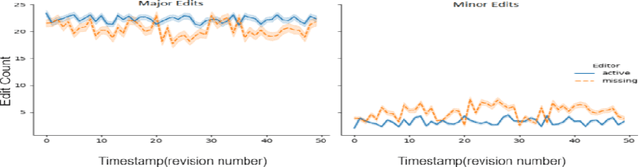

Success of planetary-scale online collaborative platforms such as Wikipedia is hinged on active and continued participation of its voluntary contributors. The phenomenal success of Wikipedia as a valued multilingual source of information is a testament to the possibilities of collective intelligence. Specifically, the sustained and prudent contributions by the experienced prolific editors play a crucial role to operate the platform smoothly for decades. However, it has been brought to light that growth of Wikipedia is stagnating in terms of the number of editors that faces steady decline over time. This decreasing productivity and ever increasing attrition rate in both newcomer and experienced editors is a major concern for not only the future of this platform but also for several industry-scale information retrieval systems such as Siri, Alexa which depend on Wikipedia as knowledge store. In this paper, we have studied the ongoing crisis in which experienced and prolific editors withdraw. We performed extensive analysis of the editor activities and their language usage to identify features that can forecast prolific Wikipedians, who are at risk of ceasing voluntary services. To the best of our knowledge, this is the first work which proposes a scalable prediction pipeline, towards detecting the prolific Wikipedians, who might be at a risk of retiring from the platform and, thereby, can potentially enable moderators to launch appropriate incentive mechanisms to retain such `would-be missing' valued Wikipedians.
EmpathBERT: A BERT-based Framework for Demographic-aware Empathy Prediction
Jan 30, 2021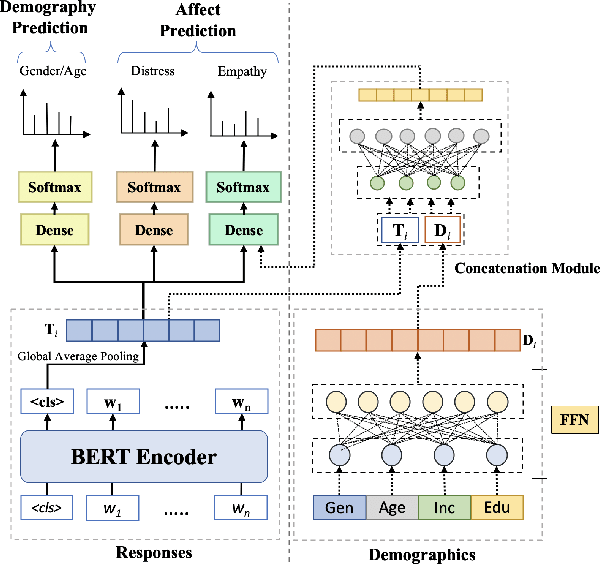

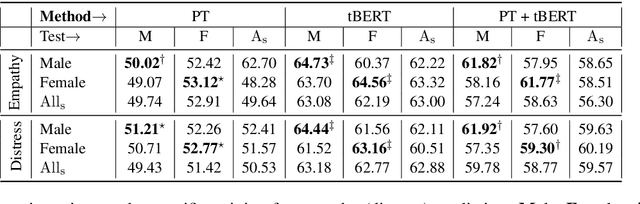
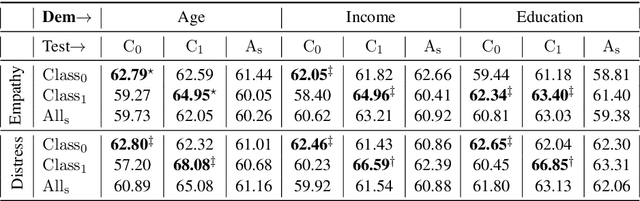
Affect preferences vary with user demographics, and tapping into demographic information provides important cues about the users' language preferences. In this paper, we utilize the user demographics, and propose EmpathBERT, a demographic-aware framework for empathy prediction based on BERT. Through several comparative experiments, we show that EmpathBERT surpasses traditional machine learning and deep learning models, and illustrate the importance of user demographics to predict empathy and distress in user responses to stimulative news articles. We also highlight the importance of affect information in the responses by developing affect-aware models to predict user demographic attributes.
Goal-driven Command Recommendations for Analysts
Nov 12, 2020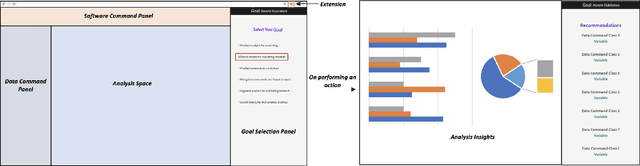
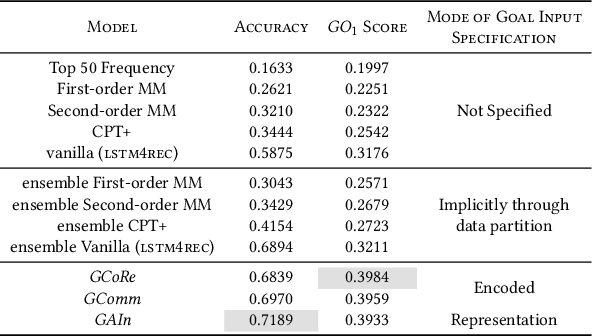
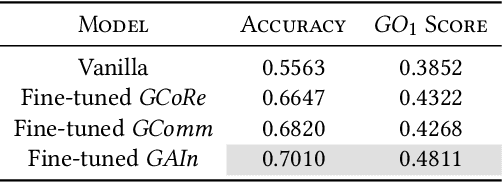
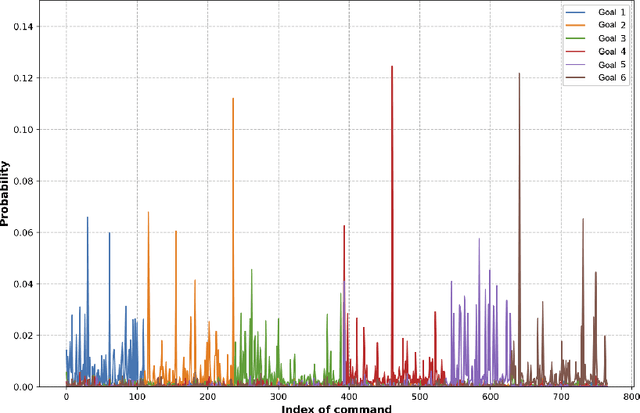
Recent times have seen data analytics software applications become an integral part of the decision-making process of analysts. The users of these software applications generate a vast amount of unstructured log data. These logs contain clues to the user's goals, which traditional recommender systems may find difficult to model implicitly from the log data. With this assumption, we would like to assist the analytics process of a user through command recommendations. We categorize the commands into software and data categories based on their purpose to fulfill the task at hand. On the premise that the sequence of commands leading up to a data command is a good predictor of the latter, we design, develop, and validate various sequence modeling techniques. In this paper, we propose a framework to provide goal-driven data command recommendations to the user by leveraging unstructured logs. We use the log data of a web-based analytics software to train our neural network models and quantify their performance, in comparison to relevant and competitive baselines. We propose a custom loss function to tailor the recommended data commands according to the goal information provided exogenously. We also propose an evaluation metric that captures the degree of goal orientation of the recommendations. We demonstrate the promise of our approach by evaluating the models with the proposed metric and showcasing the robustness of our models in the case of adversarial examples, where the user activity is misaligned with selected goal, through offline evaluation.