 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Understanding For Video Question Answering
Jul 23, 2024Video Question Answering is a challenging task, which requires the model to reason over multiple frames and understand the interaction between different objects to answer questions based on the context provided within the video, especially in datasets like NExT-QA (Xiao et al., 2021a) which emphasize on causal and temporal questions. Previous approaches leverage either sub-sampled information or causal intervention techniques along with complete video features to tackle the NExT-QA task. In this work we elicit the limitations of these approaches and propose solutions along four novel directions of improvements on theNExT-QA dataset. Our approaches attempts to compensate for the shortcomings in the previous works by systematically attacking each of these problems by smartly sampling frames, explicitly encoding actions and creating interventions that challenge the understanding of the model. Overall, for both single-frame (+6.3%) and complete-video (+1.1%) based approaches, we obtain the state-of-the-art results on NExT-QA dataset.
Multi-Dimensional Evaluation of Text Summarization with In-Context Learning
Jun 01, 2023

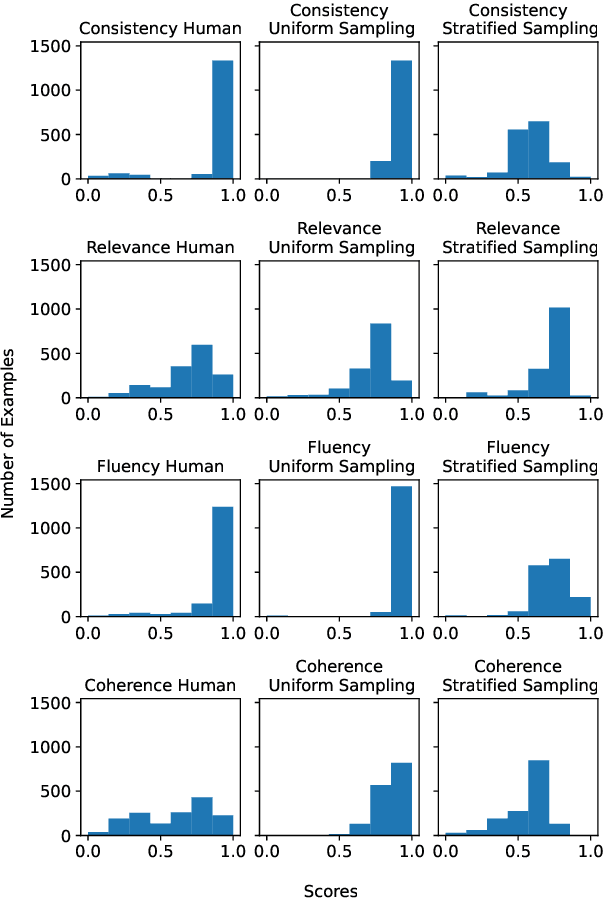

Evaluation of natural language generation (NLG) is complex and multi-dimensional. Generated text can be evaluated for fluency, coherence, factuality, or any other dimensions of interest. Most frameworks that perform such multi-dimensional evaluation require training on large manually or synthetically generated datasets. In this paper, we study the efficacy of large language models as multi-dimensional evaluators using in-context learning, obviating the need for large training datasets. Our experiments show that in-context learning-based evaluators are competitive with learned evaluation frameworks for the task of text summarization, establishing state-of-the-art on dimensions such as relevance and factual consistency. We then analyze the effects of factors such as the selection and number of in-context examples on performance. Finally, we study the efficacy of in-context learning based evaluators in evaluating zero-shot summaries written by large language models such as GPT-3.