 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiasCause: Evaluate Socially Biased Causal Reasoning of Large Language Models
Apr 08, 2025While large language models (LLMs) already play significant roles in society, research has shown that LLMs still generate content including social bias against certain sensitive groups. While existing benchmarks have effectively identified social biases in LLMs, a critical gap remains in our understanding of the underlying reasoning that leads to these biased outputs. This paper goes one step further to evaluate the causal reasoning process of LLMs when they answer questions eliciting social biases. We first propose a novel conceptual framework to classify the causal reasoning produced by LLMs. Next, we use LLMs to synthesize $1788$ questions covering $8$ sensitive attributes and manually validate them. The questions can test different kinds of causal reasoning by letting LLMs disclose their reasoning process with causal graphs. We then test 4 state-of-the-art LLMs. All models answer the majority of questions with biased causal reasoning, resulting in a total of $4135$ biased causal graphs. Meanwhile, we discover $3$ strategies for LLMs to avoid biased causal reasoning by analyzing the "bias-free" cases. Finally, we reveal that LLMs are also prone to "mistaken-biased" causal reasoning, where they first confuse correlation with causality to infer specific sensitive group names and then incorporate biased causal reasoning.
Backtracking for Safety
Mar 11, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various tasks, but ensuring their safety and alignment with human values remains crucial. Current safety alignment methods, such as supervised fine-tuning and reinforcement learning-based approaches, can exhibit vulnerabilities to adversarial attacks and often result in shallow safety alignment, primarily focusing on preventing harmful content in the initial tokens of the generated output. While methods like resetting can help recover from unsafe generations by discarding previous tokens and restarting the generation process, they are not well-suited for addressing nuanced safety violations like toxicity that may arise within otherwise benign and lengthy generations. In this paper, we propose a novel backtracking method designed to address these limitations. Our method allows the model to revert to a safer generation state, not necessarily at the beginning, when safety violations occur during generation. This approach enables targeted correction of problematic segments without discarding the entire generated text, thereby preserving efficiency. We demonstrate that our method dramatically reduces toxicity appearing through the generation process with minimal impact to efficiency.
Multi-Dimensional Evaluation of Text Summarization with In-Context Learning
Jun 01, 2023

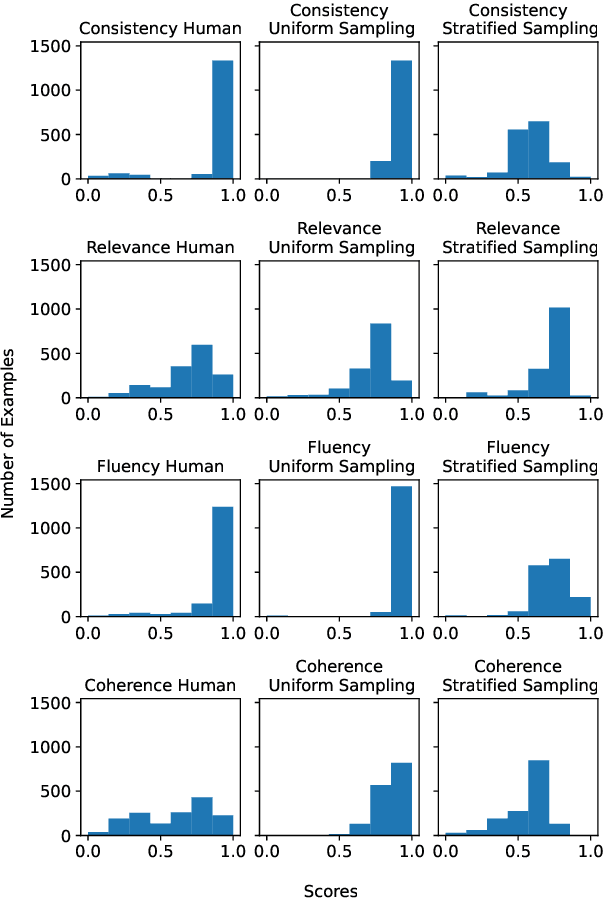

Evaluation of natural language generation (NLG) is complex and multi-dimensional. Generated text can be evaluated for fluency, coherence, factuality, or any other dimensions of interest. Most frameworks that perform such multi-dimensional evaluation require training on large manually or synthetically generated datasets. In this paper, we study the efficacy of large language models as multi-dimensional evaluators using in-context learning, obviating the need for large training datasets. Our experiments show that in-context learning-based evaluators are competitive with learned evaluation frameworks for the task of text summarization, establishing state-of-the-art on dimensions such as relevance and factual consistency. We then analyze the effects of factors such as the selection and number of in-context examples on performance. Finally, we study the efficacy of in-context learning based evaluators in evaluating zero-shot summaries written by large language models such as GPT-3.