 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPO-Listener: Expressive Interactive Head Generation via Auto-Regressive Flow Matching and Group reward-Decoupled Policy Optimization
Mar 26, 2026Generating realistic 3D head motion for dyadic interactions is a significant challenge in virtual human synthesis. While recent methods achieve impressive results with speaking heads, they frequently suffer from the `Regression-to-the-Mean' problem in listener motions, collapsing into static faces, and lack the parameter space for complex nonverbal motions. In this paper, we propose GDPO-Listener, a novel framework that achieves highly expressive speaking and listening motion generation. First, we introduce an Auto-Regressive Flow Matching architecture enabling stable supervised learning. Second, to overcome kinematic stillness, we apply the Group reward-Decoupled Policy Optimization (GDPO). By isolating reward normalization across distinct FLAME parameter groups, GDPO explicitly incentivizes high variance expressive generations. Finally, we enable explicit semantic text control for customizable responses. Extensive evaluations across the Seamless Interaction and DualTalk datasets demonstrate superior performance compared to existing baselines on long-term kinematic variance, visual expressivity and semantic controllability.
MoD-DPO: Towards Mitigating Cross-modal Hallucinations in Omni LLMs using Modality Decoupled Preference Optimization
Mar 03, 2026Omni-modal large language models (omni LLMs) have recently achieved strong performance across audiovisual understanding tasks, yet they remain highly susceptible to cross-modal hallucinations arising from spurious correlations and dominant language priors. In this work, we propose Modality-Decoupled Direct Preference Optimization (MoD-DPO), a simple and effective framework for improving modality grounding in omni LLMs. MoD-DPO introduces modality-aware regularization terms that explicitly enforce invariance to corruptions in irrelevant modalities and sensitivity to perturbations in relevant modalities, thereby reducing unintended cross-modal interactions. To further mitigate over-reliance on textual priors, we incorporate a language-prior debiasing penalty that discourages hallucination-prone text-only responses. Extensive experiments across multiple audiovisual hallucination benchmarks demonstrate that MoD-DPO consistently improves perception accuracy and hallucination resistance, outperforming previous preference optimization baselines under similar training budgets. Our findings underscore the importance of modality-faithful alignment and demonstrate a scalable path toward more reliable and resilient multimodal foundation models.
AVERE: Improving Audiovisual Emotion Reasoning with Preference Optimization
Feb 04, 2026Emotion understanding is essential for building socially intelligent agents. Although recent multimodal large language models have shown strong performance on this task, two key challenges remain - spurious associations between emotions and irrelevant audiovisual cues, and hallucinations of audiovisual cues driven by text priors in the language model backbone. To quantify and understand these issues, we introduce EmoReAlM, a benchmark designed to evaluate MLLMs for cue-emotion associations, hallucinations and modality agreement. We then propose AVEm-DPO, a preference optimization technique that aligns model responses with both audiovisual inputs and emotion-centric queries. Specifically, we construct preferences over responses exhibiting spurious associations or hallucinations, and audiovisual input pairs guided by textual prompts. We also include a regularization term that penalizes reliance on text priors, thereby mitigating modality-specific cue hallucinations. Experimental results on DFEW, RAVDESS and EMER demonstrate that our method significantly improves the performance of the reference baseline models with 6-19% of relative performance gains in zero-shot settings. By providing both a rigorous benchmark and a robust optimization framework, this work enables principled evaluation and improvement of MLLMs for emotion understanding and social AI. Code, models and benchmark will be released at https://avere-iclr.github.io.
Sparks of Rationality: Do Reasoning LLMs Align with Human Judgment and Choice?
Jan 29, 2026Large Language Models (LLMs) are increasingly positioned as decision engines for hiring, healthcare, and economic judgment, yet real-world human judgment reflects a balance between rational deliberation and emotion-driven bias. If LLMs are to participate in high-stakes decisions or serve as models of human behavior, it is critical to assess whether they exhibit analogous patterns of (ir)rationalities and biases. To this end, we evaluate multiple LLM families on (i) benchmarks testing core axioms of rational choice and (ii) classic decision domains from behavioral economics and social norms where emotions are known to shape judgment and choice. Across settings, we show that deliberate "thinking" reliably improves rationality and pushes models toward expected-value maximization. To probe human-like affective distortions and their interaction with reasoning, we use two emotion-steering methods: in-context priming (ICP) and representation-level steering (RLS). ICP induces strong directional shifts that are often extreme and difficult to calibrate, whereas RLS produces more psychologically plausible patterns but with lower reliability. Our results suggest that the same mechanisms that improve rationality also amplify sensitivity to affective interventions, and that different steering methods trade off controllability against human-aligned behavior. Overall, this points to a tension between reasoning and affective steering, with implications for both human simulation and the safe deployment of LLM-based decision systems.
Face-LLaVA: Facial Expression and Attribute Understanding through Instruction Tuning
Apr 09, 2025
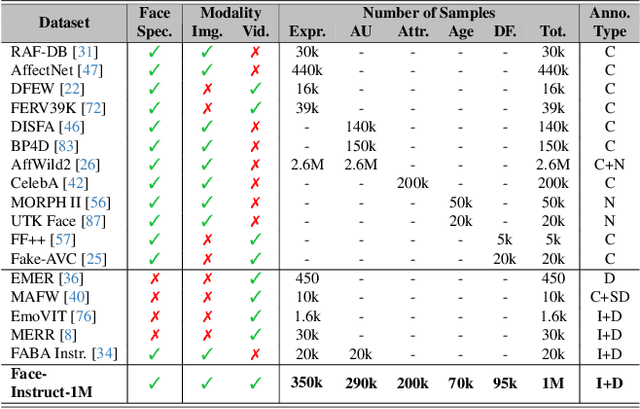

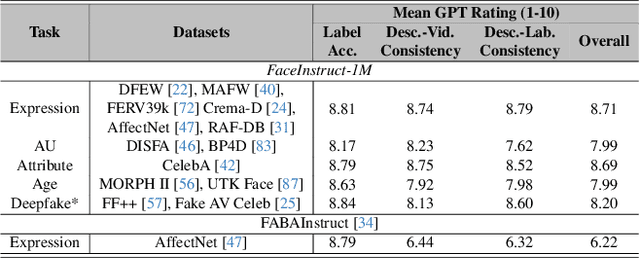
The human face plays a central role in social communication, necessitating the use of performant computer vision tools for human-centered applications. We propose Face-LLaVA, a multimodal large language model for face-centered, in-context learning, including facial expression and attribute recognition. Additionally, Face-LLaVA is able to generate natural language descriptions that can be used for reasoning. Leveraging existing visual databases, we first developed FaceInstruct-1M, a face-centered database for instruction tuning MLLMs for face processing. We then developed a novel face-specific visual encoder powered by Face-Region Guided Cross-Attention that integrates face geometry with local visual features. We evaluated the proposed method across nine different datasets and five different face processing tasks, including facial expression recognition, action unit detection, facial attribute detection, age estimation and deepfake detection. Face-LLaVA achieves superior results compared to existing open-source MLLMs and competitive performance compared to commercial solutions. Our model output also receives a higher reasoning rating by GPT under a zero-shot setting across all the tasks. Both our dataset and model wil be released at https://face-llava.github.io to support future advancements in social AI and foundational vision-language research.
DiTaiListener: Controllable High Fidelity Listener Video Generation with Diffusion
Apr 05, 2025



Generating naturalistic and nuanced listener motions for extended interactions remains an open problem. Existing methods often rely on low-dimensional motion codes for facial behavior generation followed by photorealistic rendering, limiting both visual fidelity and expressive richness. To address these challenges, we introduce DiTaiListener, powered by a video diffusion model with multimodal conditions. Our approach first generates short segments of listener responses conditioned on the speaker's speech and facial motions with DiTaiListener-Gen. It then refines the transitional frames via DiTaiListener-Edit for a seamless transition. Specifically, DiTaiListener-Gen adapts a Diffusion Transformer (DiT) for the task of listener head portrait generation by introducing a Causal Temporal Multimodal Adapter (CTM-Adapter) to process speakers' auditory and visual cues. CTM-Adapter integrates speakers' input in a causal manner into the video generation process to ensure temporally coherent listener responses. For long-form video generation, we introduce DiTaiListener-Edit, a transition refinement video-to-video diffusion model. The model fuses video segments into smooth and continuous videos, ensuring temporal consistency in facial expressions and image quality when merging short video segments produced by DiTaiListener-Gen. Quantitatively, DiTaiListener achieves the state-of-the-art performance on benchmark datasets in both photorealism (+73.8% in FID on RealTalk) and motion representation (+6.1% in FD metric on VICO) spaces. User studies confirm the superior performance of DiTaiListener, with the model being the clear preference in terms of feedback, diversity, and smoothness, outperforming competitors by a significant margin.
ContextIQ: A Multimodal Expert-Based Video Retrieval System for Contextual Advertising
Oct 29, 2024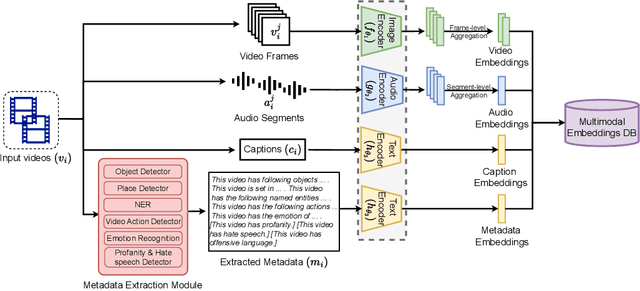
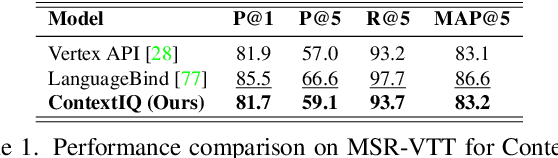
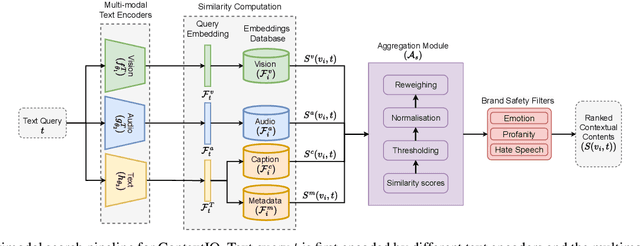
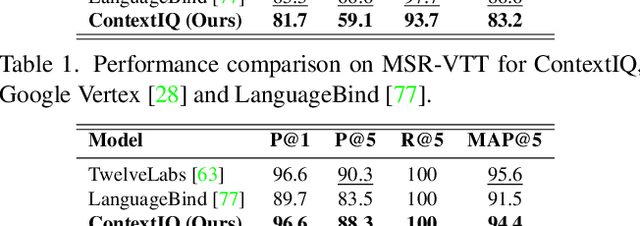
Contextual advertising serves ads that are aligned to the content that the user is viewing. The rapid growth of video content on social platforms and streaming services, along with privacy concerns, has increased the need for contextual advertising. Placing the right ad in the right context creates a seamless and pleasant ad viewing experience, resulting in higher audience engagement and, ultimately, better ad monetization. From a technology standpoint, effective contextual advertising requires a video retrieval system capable of understanding complex video content at a very granular level. Current text-to-video retrieval models based on joint multimodal training demand large datasets and computational resources, limiting their practicality and lacking the key functionalities required for ad ecosystem integration. We introduce ContextIQ, a multimodal expert-based video retrieval system designed specifically for contextual advertising. ContextIQ utilizes modality-specific experts-video, audio, transcript (captions), and metadata such as objects, actions, emotion, etc.-to create semantically rich video representations. We show that our system, without joint training, achieves better or comparable results to state-of-the-art models and commercial solutions on multiple text-to-video retrieval benchmarks. Our ablation studies highlight the benefits of leveraging multiple modalities for enhanced video retrieval accuracy instead of using a vision-language model alone. Furthermore, we show how video retrieval systems such as ContextIQ can be used for contextual advertising in an ad ecosystem while also addressing concerns related to brand safety and filtering inappropriate content.
Speaker-specific Thresholding for Robust Imposter Identification in Unseen Speaker Recognition
Jun 01, 2023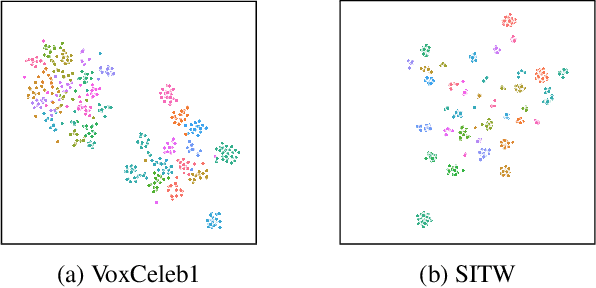
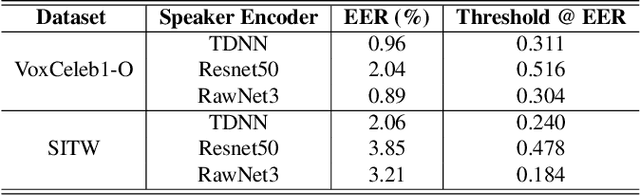
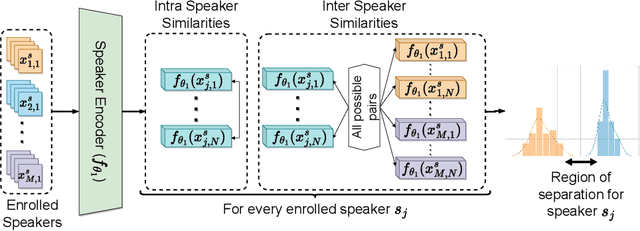

Speaker identification systems are deployed in diverse environments, often different from the lab conditions on which they are trained and tested. In this paper, first, we show the problem of generalization using fixed thresholds computed using the equal error rate metric. Secondly, we introduce a novel and generalizable speaker-specific thresholding technique for robust imposter identification in unseen speaker identification. We propose a speaker-specific adaptive threshold, which can be computed using the enrollment audio samples, for identifying imposters in unseen speaker identification. Furthermore, we show the efficacy of the proposed technique on VoxCeleb1, VCTK and the FFSVC 2022 datasets, beating the baseline fixed thresholding by up to 25%. Finally, we exhibit that the proposed algorithm is also generalizable, demonstrating its performance on ResNet50, ECAPA-TDNN and RawNet3 speaker encoders.
Improved Relation Networks for End-to-End Speaker Verification and Identification
Mar 31, 2022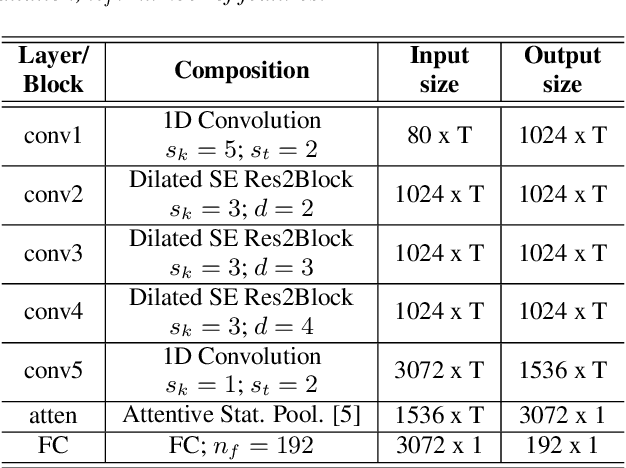
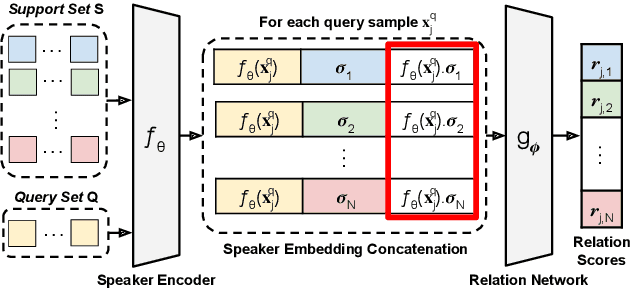

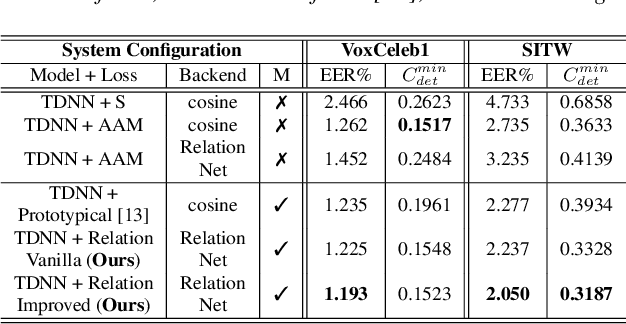
Speaker identification systems in a real-world scenario are tasked to identify a speaker amongst a set of enrolled speakers given just a few samples for each enrolled speaker. This paper demonstrates the effectiveness of meta-learning and relation networks for this use case. We propose improved relation networks for speaker verification and few-shot (unseen) speaker identification. The use of relation networks facilitates joint training of the frontend speaker encoder and the backend model. Inspired by the use of prototypical networks in speaker verification and to increase the discriminability of the speaker embeddings, we train the model to classify samples in the current episode amongst all speakers present in the training set. Furthermore, we propose a new training regime for faster model convergence by extracting more information from a given meta-learning episode with negligible extra computation. We evaluate the proposed techniques on VoxCeleb, SITW and VCTK datasets on the tasks of speaker verification and unseen speaker identification. The proposed approach outperforms the existing approaches consistently on both tasks.
OPAD: An Optimized Policy-based Active Learning Framework for Document Content Analysis
Oct 07, 2021
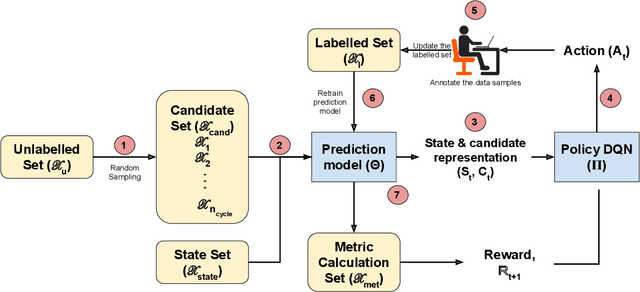
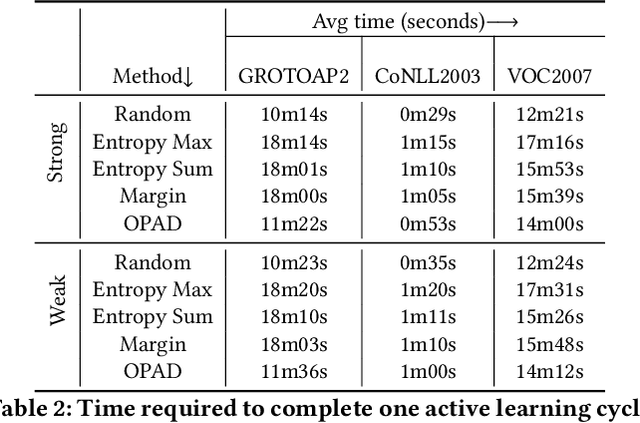
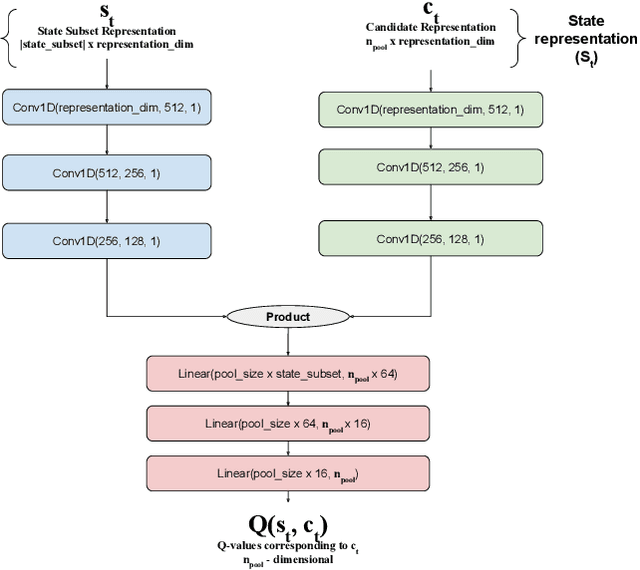
Documents are central to many business systems, and include forms, reports, contracts, invoices or purchase orders. The information in documents is typically in natural language, but can be organized in various layouts and formats. There have been recent spurt of interest in understanding document content with novel deep learning architectures. However, document understanding tasks need dense information annotations, which are costly to scale and generalize. Several active learning techniques have been proposed to reduce the overall budget of annotation while maintaining the performance of the underlying deep learning model. However, most of these techniques work only for classification problems. But content detection is a more complex task, and has been scarcely explored in active learning literature. In this paper, we propose \textit{OPAD}, a novel framework using reinforcement policy for active learning in content detection tasks for documents. The proposed framework learns the acquisition function to decide the samples to be selected while optimizing performance metrics that the tasks typically have. Furthermore, we extend to weak labelling scenarios to further reduce the cost of annotation significantly. We propose novel rewards to account for class imbalance and user feedback in the annotation interface, to improve the active learning method. We show superior performance of the proposed \textit{OPAD} framework for active learning for various tasks related to document understanding like layout parsing, object detection and named entity recognition. Ablation studies for human feedback and class imbalance rewards are presented, along with a comparison of annotation times for different approaches.