 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Adversarial Perturbations: A Survey
May 16, 2020
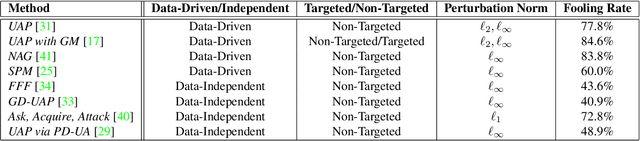


Over the past decade, Deep Learning has emerged as a useful and efficient tool to solve a wide variety of complex learning problems ranging from image classification to human pose estimation, which is challenging to solve using statistical machine learning algorithms. However, despite their superior performance, deep neural networks are susceptible to adversarial perturbations, which can cause the network's prediction to change without making perceptible changes to the input image, thus creating severe security issues at the time of deployment of such systems. Recent works have shown the existence of Universal Adversarial Perturbations, which, when added to any image in a dataset, misclassifies it when passed through a target model. Such perturbations are more practical to deploy since there is minimal computation done during the actual attack. Several techniques have also been proposed to defend the neural networks against these perturbations. In this paper, we attempt to provide a detailed discussion on the various data-driven and data-independent methods for generating universal perturbations, along with measures to defend against such perturbations. We also cover the applications of such universal perturbations in various deep learning tasks.