 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Unseen: Visual Metaphor Captioning for Videos
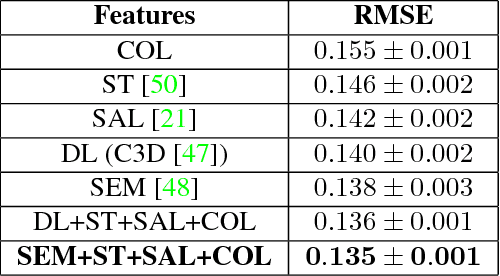
Jun 07, 2024Metaphors are a common communication tool used in our day-to-day life. The detection and generation of metaphors in textual form have been studied extensively but metaphors in other forms have been under-explored. Recent studies have shown that Vision-Language (VL) models cannot understand visual metaphors in memes and adverts. As of now, no probing studies have been done that involve complex language phenomena like metaphors with videos. Hence, we introduce a new VL task of describing the metaphors present in the videos in our work. To facilitate this novel task, we construct and release a manually created dataset with 705 videos and 2115 human-written captions, along with a new metric called Average Concept Distance (ACD), to automatically evaluate the creativity of the metaphors generated. We also propose a novel low-resource video metaphor captioning system: GIT-LLaVA, which obtains comparable performance to SoTA video language models on the proposed task. We perform a comprehensive analysis of existing video language models on this task and publish our dataset, models, and benchmark results to enable further research.
"Let's not Quote out of Context": Unified Vision-Language Pretraining for Context Assisted Image Captioning
Jun 01, 2023
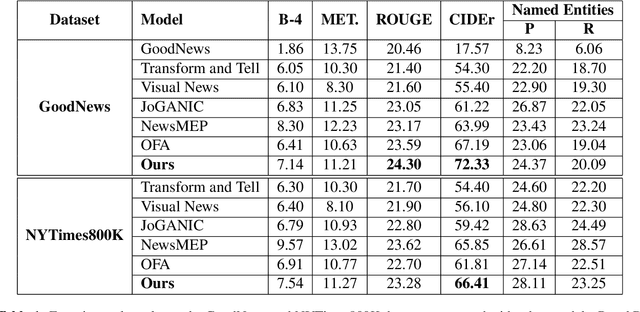
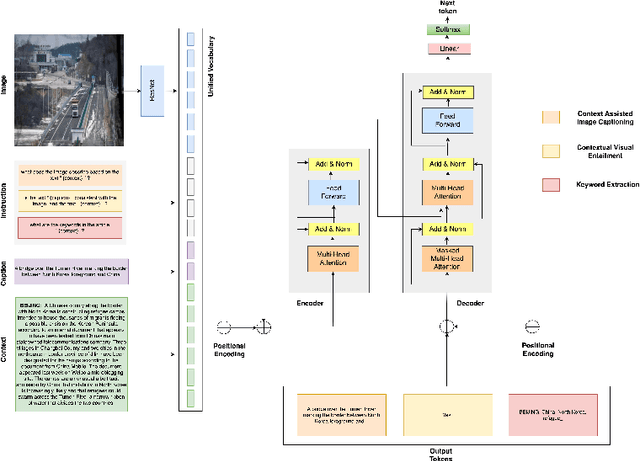
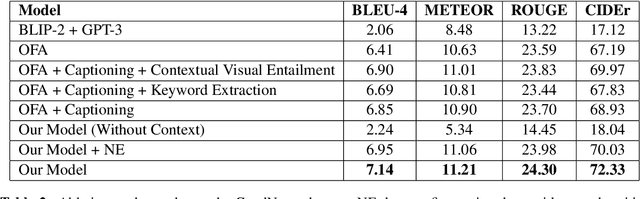
Well-formed context aware image captions and tags in enterprise content such as marketing material are critical to ensure their brand presence and content recall. Manual creation and updates to ensure the same is non trivial given the scale and the tedium towards this task. We propose a new unified Vision-Language (VL) model based on the One For All (OFA) model, with a focus on context-assisted image captioning where the caption is generated based on both the image and its context. Our approach aims to overcome the context-independent (image and text are treated independently) nature of the existing approaches. We exploit context by pretraining our model with datasets of three tasks: news image captioning where the news article is the context, contextual visual entailment, and keyword extraction from the context. The second pretraining task is a new VL task, and we construct and release two datasets for the task with 1.1M and 2.2K data instances. Our system achieves state-of-the-art results with an improvement of up to 8.34 CIDEr score on the benchmark news image captioning datasets. To the best of our knowledge, ours is the first effort at incorporating contextual information in pretraining the models for the VL tasks.
Audio Retrieval for Multimodal Design Documents: A New Dataset and Algorithms
Feb 28, 2023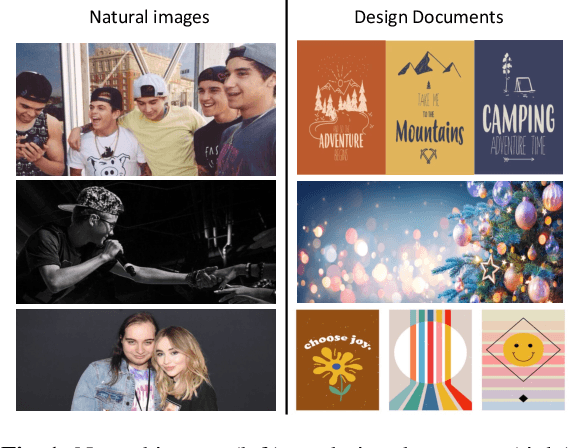
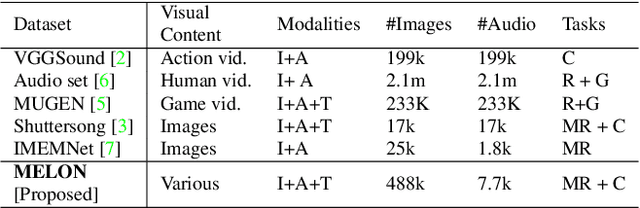
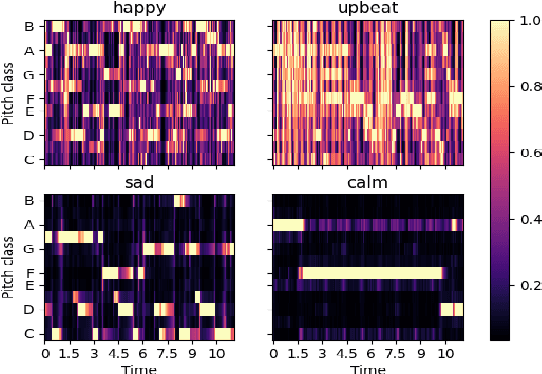

We consider and propose a new problem of retrieving audio files relevant to multimodal design document inputs comprising both textual elements and visual imagery, e.g., birthday/greeting cards. In addition to enhancing user experience, integrating audio that matches the theme/style of these inputs also helps improve the accessibility of these documents (e.g., visually impaired people can listen to the audio instead). While recent work in audio retrieval exists, these methods and datasets are targeted explicitly towards natural images. However, our problem considers multimodal design documents (created by users using creative software) substantially different from a naturally clicked photograph. To this end, our first contribution is collecting and curating a new large-scale dataset called Melodic-Design (or MELON), comprising design documents representing various styles, themes, templates, illustrations, etc., paired with music audio. Given our paired image-text-audio dataset, our next contribution is a novel multimodal cross-attention audio retrieval (MMCAR) algorithm that enables training neural networks to learn a common shared feature space across image, text, and audio dimensions. We use these learned features to demonstrate that our method outperforms existing state-of-the-art methods and produce a new reference benchmark for the research community on our new dataset.
Interactive Control over Temporal-consistency while Stylizing Video Streams
Jan 02, 2023With the advent of Neural Style Transfer (NST), stylizing an image has become quite popular. A convenient way for extending stylization techniques to videos is by applying them on a per-frame basis. However, such per-frame application usually lacks temporal-consistency expressed by undesirable flickering artifacts. Most of the existing approaches for enforcing temporal-consistency suffers from one or more of the following drawbacks. They (1) are only suitable for a limited range of stylization techniques, (2) can only be applied in an offline fashion requiring the complete video as input, (3) cannot provide consistency for the task of stylization, or (4) do not provide interactive consistency-control. Note that existing consistent video-filtering approaches aim to completely remove flickering artifacts and thus do not respect any specific consistency-control aspect. For stylization tasks, however, consistency-control is an essential requirement where a certain amount of flickering can add to the artistic look and feel. Moreover, making this control interactive is paramount from a usability perspective. To achieve the above requirements, we propose an approach that can stylize video streams while providing interactive consistency-control. Apart from stylization, our approach also supports various other image processing filters. For achieving interactive performance, we develop a lite optical-flow network that operates at 80 Frames per second (FPS) on desktop systems with sufficient accuracy. We show that the final consistent video-output using our flow network is comparable to that being obtained using state-of-the-art optical-flow network. Further, we employ an adaptive combination of local and global consistent features and enable interactive selection between the two. By objective and subjective evaluation, we show that our method is superior to state-of-the-art approaches.
DistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022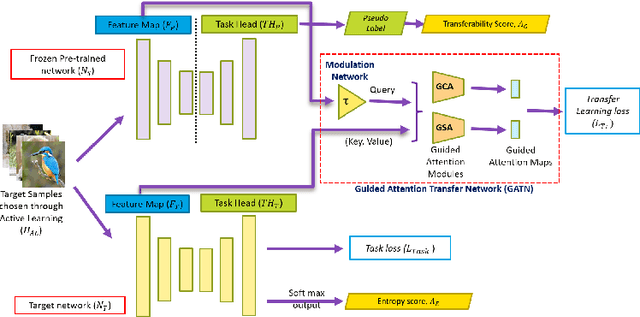

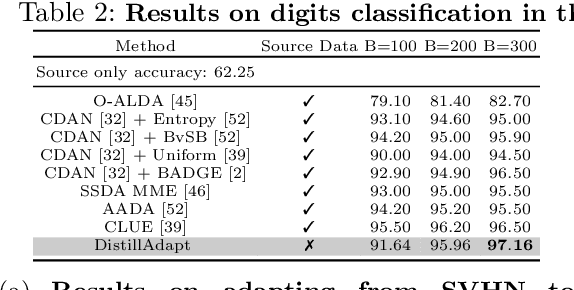
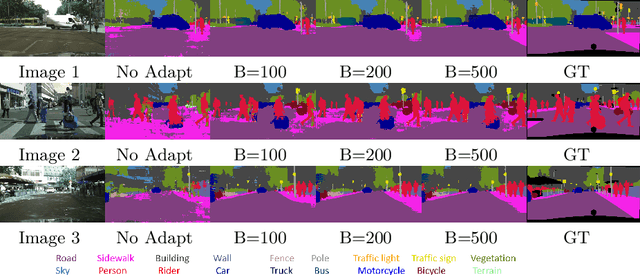
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.
Low-light Image and Video Enhancement via Selective Manipulation of Chromaticity
Mar 09, 2022
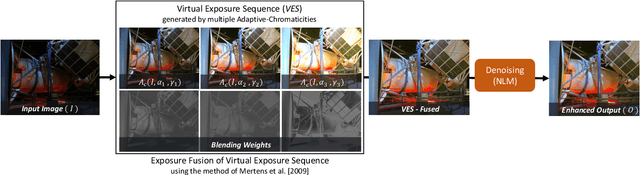
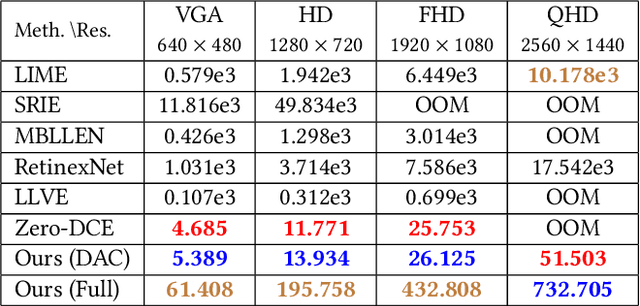

Image acquisition in low-light conditions suffers from poor quality and significant degradation in visual aesthetics. This affects the visual perception of the acquired image and the performance of various computer vision and image processing algorithms applied after acquisition. Especially for videos, the additional temporal domain makes it more challenging, wherein we need to preserve quality in a temporally coherent manner. We present a simple yet effective approach for low-light image and video enhancement. To this end, we introduce "Adaptive Chromaticity", which refers to an adaptive computation of image chromaticity. The above adaptivity allows us to avoid the costly step of low-light image decomposition into illumination and reflectance, employed by many existing techniques. All stages in our method consist of only point-based operations and high-pass or low-pass filtering, thereby ensuring that the amount of temporal incoherence is negligible when applied on a per-frame basis for videos. Our results on standard lowlight image datasets show the efficacy of our algorithm and its qualitative and quantitative superiority over several state-of-the-art techniques. For videos captured in the wild, we perform a user study to demonstrate the preference for our method in comparison to state-of-the-art approaches.
TALISMAN: Targeted Active Learning for Object Detection with Rare Classes and Slices using Submodular Mutual Information
Nov 30, 2021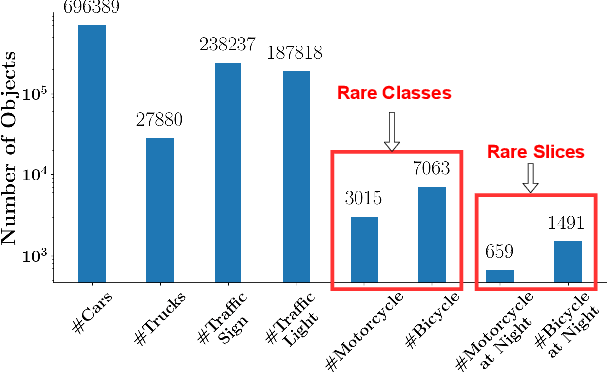
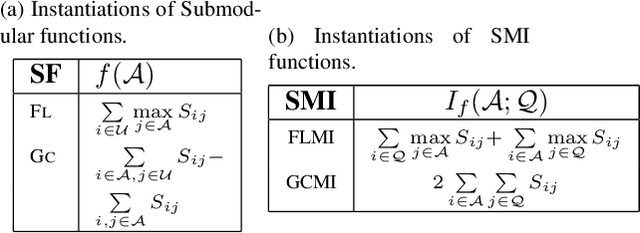
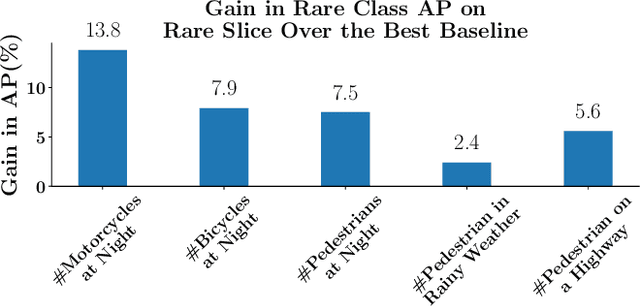
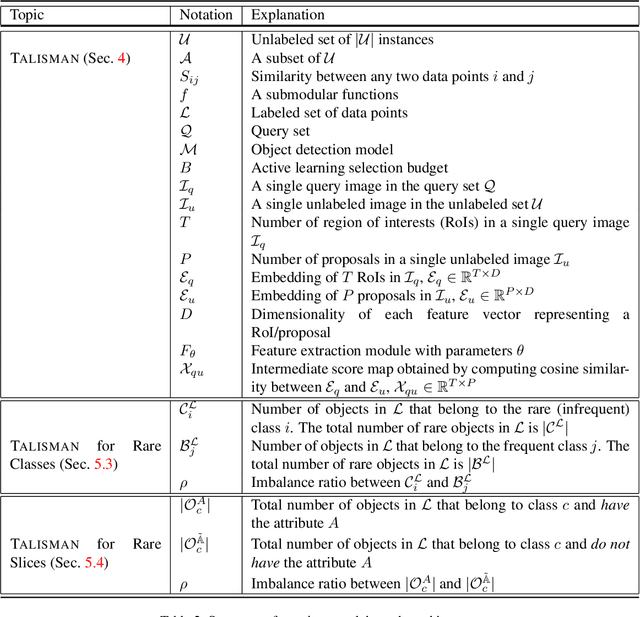
Deep neural networks based object detectors have shown great success in a variety of domains like autonomous vehicles, biomedical imaging, etc. It is known that their success depends on a large amount of data from the domain of interest. While deep models often perform well in terms of overall accuracy, they often struggle in performance on rare yet critical data slices. For example, data slices like "motorcycle at night" or "bicycle at night" are often rare but very critical slices for self-driving applications and false negatives on such rare slices could result in ill-fated failures and accidents. Active learning (AL) is a well-known paradigm to incrementally and adaptively build training datasets with a human in the loop. However, current AL based acquisition functions are not well-equipped to tackle real-world datasets with rare slices, since they are based on uncertainty scores or global descriptors of the image. We propose TALISMAN, a novel framework for Targeted Active Learning or object detectIon with rare slices using Submodular MutuAl iNformation. Our method uses the submodular mutual information functions instantiated using features of the region of interest (RoI) to efficiently target and acquire data points with rare slices. We evaluate our framework on the standard PASCAL VOC07+12 and BDD100K, a real-world self-driving dataset. We observe that TALISMAN outperforms other methods by in terms of average precision on rare slices, and in terms of mAP.
OPAD: An Optimized Policy-based Active Learning Framework for Document Content Analysis
Oct 07, 2021
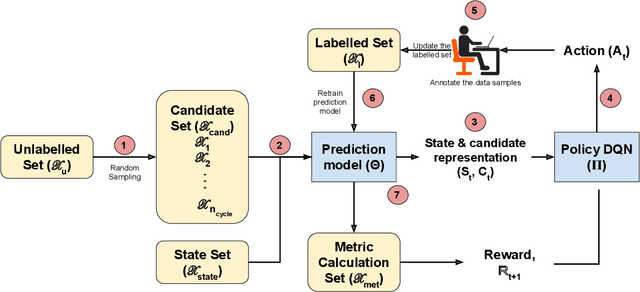
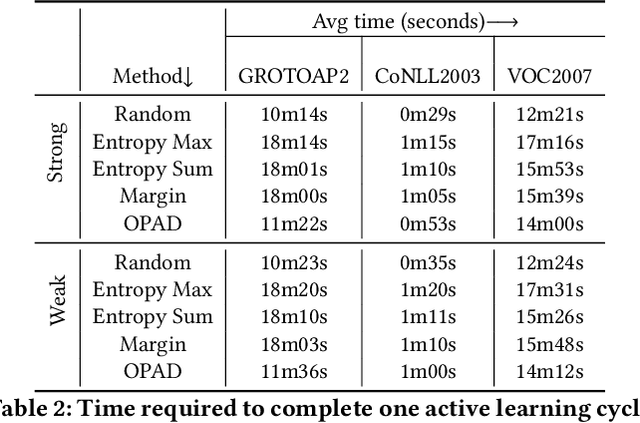
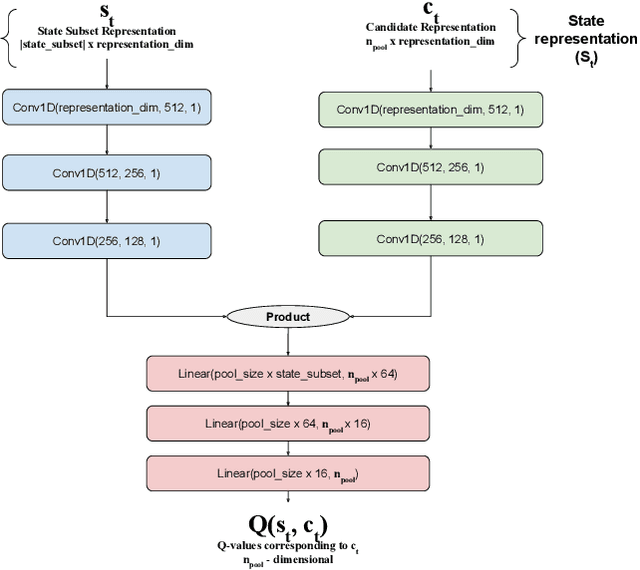
Documents are central to many business systems, and include forms, reports, contracts, invoices or purchase orders. The information in documents is typically in natural language, but can be organized in various layouts and formats. There have been recent spurt of interest in understanding document content with novel deep learning architectures. However, document understanding tasks need dense information annotations, which are costly to scale and generalize. Several active learning techniques have been proposed to reduce the overall budget of annotation while maintaining the performance of the underlying deep learning model. However, most of these techniques work only for classification problems. But content detection is a more complex task, and has been scarcely explored in active learning literature. In this paper, we propose \textit{OPAD}, a novel framework using reinforcement policy for active learning in content detection tasks for documents. The proposed framework learns the acquisition function to decide the samples to be selected while optimizing performance metrics that the tasks typically have. Furthermore, we extend to weak labelling scenarios to further reduce the cost of annotation significantly. We propose novel rewards to account for class imbalance and user feedback in the annotation interface, to improve the active learning method. We show superior performance of the proposed \textit{OPAD} framework for active learning for various tasks related to document understanding like layout parsing, object detection and named entity recognition. Ablation studies for human feedback and class imbalance rewards are presented, along with a comparison of annotation times for different approaches.
LEAF-QA: Locate, Encode & Attend for Figure Question Answering
Jul 30, 2019
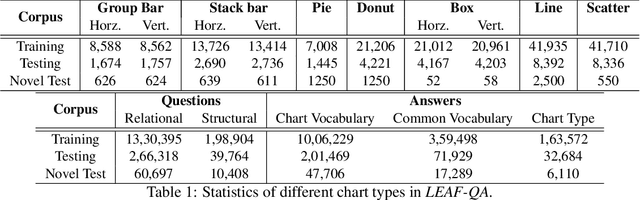
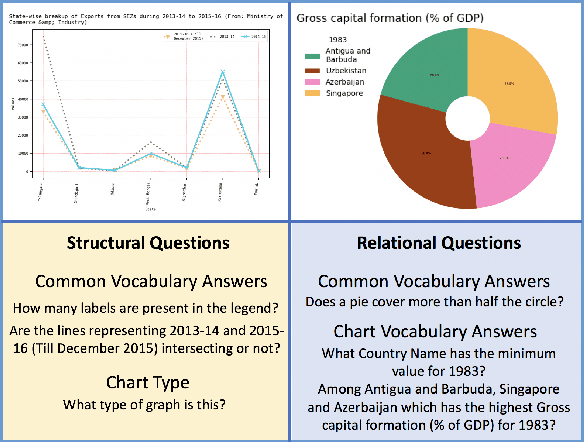
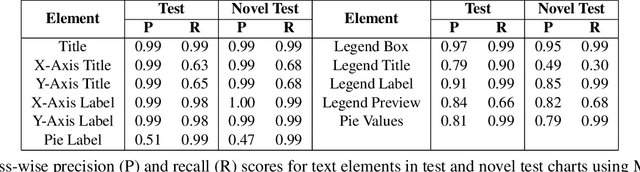
We introduce LEAF-QA, a comprehensive dataset of $250,000$ densely annotated figures/charts, constructed from real-world open data sources, along with ~2 million question-answer (QA) pairs querying the structure and semantics of these charts. LEAF-QA highlights the problem of multimodal QA, which is notably different from conventional visual QA (VQA), and has recently gained interest in the community. Furthermore, LEAF-QA is significantly more complex than previous attempts at chart QA, viz. FigureQA and DVQA, which present only limited variations in chart data. LEAF-QA being constructed from real-world sources, requires a novel architecture to enable question answering. To this end, LEAF-Net, a deep architecture involving chart element localization, question and answer encoding in terms of chart elements, and an attention network is proposed. Different experiments are conducted to demonstrate the challenges of QA on LEAF-QA. The proposed architecture, LEAF-Net also considerably advances the current state-of-the-art on FigureQA and DVQA.
Show and Recall: Learning What Makes Videos Memorable
Aug 28, 2017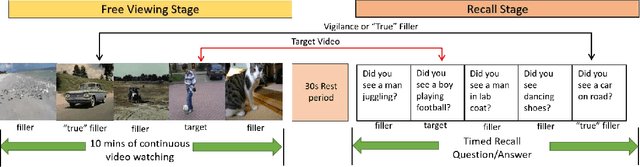
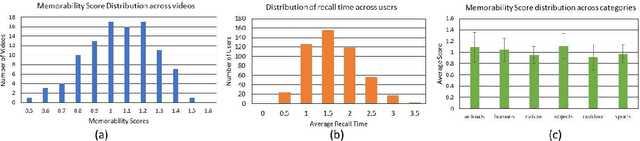

With the explosion of video content on the Internet, there is a need for research on methods for video analysis which take human cognition into account. One such cognitive measure is memorability, or the ability to recall visual content after watching it. Prior research has looked into image memorability and shown that it is intrinsic to visual content, but the problem of modeling video memorability has not been addressed sufficiently. In this work, we develop a prediction model for video memorability, including complexities of video content in it. Detailed feature analysis reveals that the proposed method correlates well with existing findings on memorability. We also describe a novel experiment of predicting video sub-shot memorability and show that our approach improves over current memorability methods in this task. Experiments on standard datasets demonstrate that the proposed metric can achieve results on par or better than the state-of-the art methods for video summarization.