 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetreeX: Unsupervised Tree Instance Segmentation in Dense Forest Point Clouds
Sep 03, 2025Close-range laser scanning provides detailed 3D captures of forest stands but requires efficient software for processing 3D point cloud data and extracting individual trees. Although recent studies have introduced deep learning methods for tree instance segmentation, these approaches require large annotated datasets and substantial computational resources. As a resource-efficient alternative, we present a revised version of the treeX algorithm, an unsupervised method that combines clustering-based stem detection with region growing for crown delineation. While the original treeX algorithm was developed for personal laser scanning (PLS) data, we provide two parameter presets, one for ground-based laser scanning (stationary terrestrial - TLS and PLS), and one for UAV-borne laser scanning (ULS). We evaluated the method on six public datasets (FOR-instance, ForestSemantic, LAUTx, NIBIO MLS, TreeLearn, Wytham Woods) and compared it to six open-source methods (original treeX, treeiso, RayCloudTools, ForAINet, SegmentAnyTree, TreeLearn). Compared to the original treeX algorithm, our revision reduces runtime and improves accuracy, with instance detection F$_1$-score gains of +0.11 to +0.49 for ground-based data. For ULS data, our preset achieves an F$_1$-score of 0.58, whereas the original algorithm fails to segment any correct instances. For TLS and PLS data, our algorithm achieves accuracy similar to recent open-source methods, including deep learning. Given its algorithmic design, we see two main applications for our method: (1) as a resource-efficient alternative to deep learning approaches in scenarios where the data characteristics align with the method design (sufficient stem visibility and point density), and (2) for the semi-automatic generation of labels for deep learning models. To enable broader adoption, we provide an open-source Python implementation in the pointtree package.
Controlling Human Shape and Pose in Text-to-Image Diffusion Models via Domain Adaptation
Nov 07, 2024We present a methodology for conditional control of human shape and pose in pretrained text-to-image diffusion models using a 3D human parametric model (SMPL). Fine-tuning these diffusion models to adhere to new conditions requires large datasets and high-quality annotations, which can be more cost-effectively acquired through synthetic data generation rather than real-world data. However, the domain gap and low scene diversity of synthetic data can compromise the pretrained model's visual fidelity. We propose a domain-adaptation technique that maintains image quality by isolating synthetically trained conditional information in the classifier-free guidance vector and composing it with another control network to adapt the generated images to the input domain. To achieve SMPL control, we fine-tune a ControlNet-based architecture on the synthetic SURREAL dataset of rendered humans and apply our domain adaptation at generation time. Experiments demonstrate that our model achieves greater shape and pose diversity than the 2d pose-based ControlNet, while maintaining the visual fidelity and improving stability, proving its usefulness for downstream tasks such as human animation.
A Large-Scale Sensitivity Analysis on Latent Embeddings and Dimensionality Reductions for Text Spatializations
Jul 25, 2024
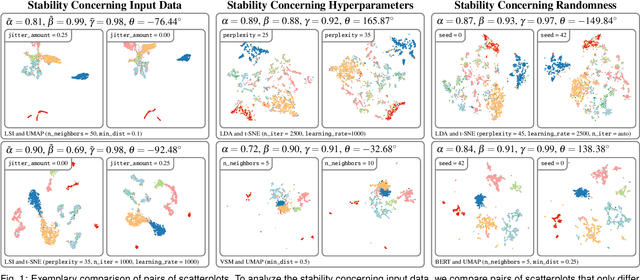

The semantic similarity between documents of a text corpus can be visualized using map-like metaphors based on two-dimensional scatterplot layouts. These layouts result from a dimensionality reduction on the document-term matrix or a representation within a latent embedding, including topic models. Thereby, the resulting layout depends on the input data and hyperparameters of the dimensionality reduction and is therefore affected by changes in them. Furthermore, the resulting layout is affected by changes in the input data and hyperparameters of the dimensionality reduction. However, such changes to the layout require additional cognitive efforts from the user. In this work, we present a sensitivity study that analyzes the stability of these layouts concerning (1) changes in the text corpora, (2) changes in the hyperparameter, and (3) randomness in the initialization. Our approach has two stages: data measurement and data analysis. First, we derived layouts for the combination of three text corpora and six text embeddings and a grid-search-inspired hyperparameter selection of the dimensionality reductions. Afterward, we quantified the similarity of the layouts through ten metrics, concerning local and global structures and class separation. Second, we analyzed the resulting 42817 tabular data points in a descriptive statistical analysis. From this, we derived guidelines for informed decisions on the layout algorithm and highlight specific hyperparameter settings. We provide our implementation as a Git repository at https://github.com/hpicgs/Topic-Models-and-Dimensionality-Reduction-Sensitivity-Study and results as Zenodo archive at https://doi.org/10.5281/zenodo.12772898.
Standardness Fogs Meaning: A Position Regarding the Informed Usage of Standard Datasets
Jun 19, 2024



Standard datasets are frequently used to train and evaluate Machine Learning models. However, the assumed standardness of these datasets leads to a lack of in-depth discussion on how their labels match the derived categories for the respective use case. In other words, the standardness of the datasets seems to fog coherency and applicability, thus impeding the trust in Machine Learning models. We propose to adopt Grounded Theory and Hypotheses Testing through Visualization as methods to evaluate the match between use case, derived categories, and labels of standard datasets. To showcase the approach, we apply it to the 20 Newsgroups dataset and the MNIST dataset. For the 20 Newsgroups dataset, we demonstrate that the labels are imprecise. Therefore, we argue that neither a Machine Learning model can learn a meaningful abstraction of derived categories nor one can draw conclusions from achieving high accuracy. For the MNIST dataset, we demonstrate how the labels can be confirmed to be defined well. We conclude that a concept of standardness of a dataset implies that there is a match between use case, derived categories, and class labels, as in the case of the MNIST dataset. We argue that this is necessary to learn a meaningful abstraction and, thus, improve trust in the Machine Learning model.
Controlling Geometric Abstraction and Texture for Artistic Images
Jul 31, 2023



We present a novel method for the interactive control of geometric abstraction and texture in artistic images. Previous example-based stylization methods often entangle shape, texture, and color, while generative methods for image synthesis generally either make assumptions about the input image, such as only allowing faces or do not offer precise editing controls. By contrast, our holistic approach spatially decomposes the input into shapes and a parametric representation of high-frequency details comprising the image's texture, thus enabling independent control of color and texture. Each parameter in this representation controls painterly attributes of a pipeline of differentiable stylization filters. The proposed decoupling of shape and texture enables various options for stylistic editing, including interactive global and local adjustments of shape, stroke, and painterly attributes such as surface relief and contours. Additionally, we demonstrate optimization-based texture style-transfer in the parametric space using reference images and text prompts, as well as the training of single- and arbitrary style parameter prediction networks for real-time texture decomposition.
Large-Scale Evaluation of Topic Models and Dimensionality Reduction Methods for 2D Text Spatialization
Jul 17, 2023



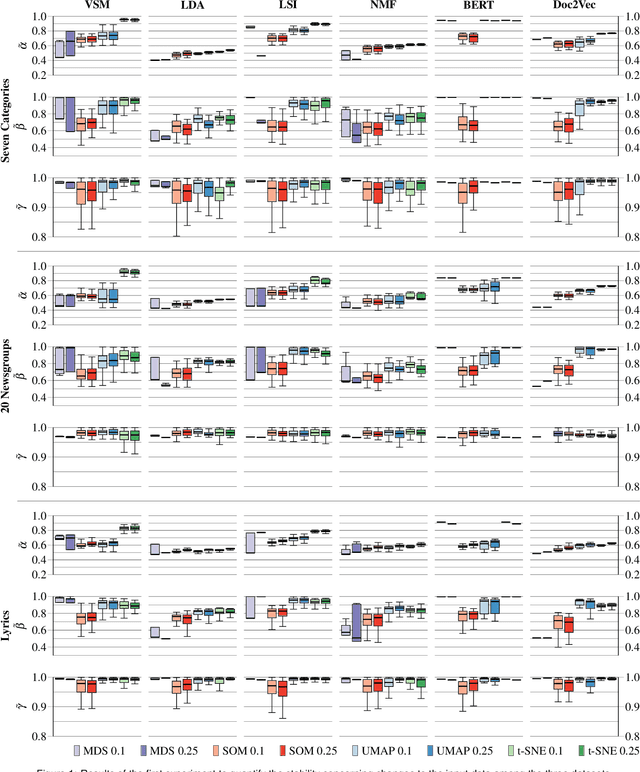
Topic models are a class of unsupervised learning algorithms for detecting the semantic structure within a text corpus. Together with a subsequent dimensionality reduction algorithm, topic models can be used for deriving spatializations for text corpora as two-dimensional scatter plots, reflecting semantic similarity between the documents and supporting corpus analysis. Although the choice of the topic model, the dimensionality reduction, and their underlying hyperparameters significantly impact the resulting layout, it is unknown which particular combinations result in high-quality layouts with respect to accuracy and perception metrics. To investigate the effectiveness of topic models and dimensionality reduction methods for the spatialization of corpora as two-dimensional scatter plots (or basis for landscape-type visualizations), we present a large-scale, benchmark-based computational evaluation. Our evaluation consists of (1) a set of corpora, (2) a set of layout algorithms that are combinations of topic models and dimensionality reductions, and (3) quality metrics for quantifying the resulting layout. The corpora are given as document-term matrices, and each document is assigned to a thematic class. The chosen metrics quantify the preservation of local and global properties and the perceptual effectiveness of the two-dimensional scatter plots. By evaluating the benchmark on a computing cluster, we derived a multivariate dataset with over 45 000 individual layouts and corresponding quality metrics. Based on the results, we propose guidelines for the effective design of text spatializations that are based on topic models and dimensionality reductions. As a main result, we show that interpretable topic models are beneficial for capturing the structure of text corpora. We furthermore recommend the use of t-SNE as a subsequent dimensionality reduction.
Interactive Control over Temporal-consistency while Stylizing Video Streams
Jan 02, 2023With the advent of Neural Style Transfer (NST), stylizing an image has become quite popular. A convenient way for extending stylization techniques to videos is by applying them on a per-frame basis. However, such per-frame application usually lacks temporal-consistency expressed by undesirable flickering artifacts. Most of the existing approaches for enforcing temporal-consistency suffers from one or more of the following drawbacks. They (1) are only suitable for a limited range of stylization techniques, (2) can only be applied in an offline fashion requiring the complete video as input, (3) cannot provide consistency for the task of stylization, or (4) do not provide interactive consistency-control. Note that existing consistent video-filtering approaches aim to completely remove flickering artifacts and thus do not respect any specific consistency-control aspect. For stylization tasks, however, consistency-control is an essential requirement where a certain amount of flickering can add to the artistic look and feel. Moreover, making this control interactive is paramount from a usability perspective. To achieve the above requirements, we propose an approach that can stylize video streams while providing interactive consistency-control. Apart from stylization, our approach also supports various other image processing filters. For achieving interactive performance, we develop a lite optical-flow network that operates at 80 Frames per second (FPS) on desktop systems with sufficient accuracy. We show that the final consistent video-output using our flow network is comparable to that being obtained using state-of-the-art optical-flow network. Further, we employ an adaptive combination of local and global consistent features and enable interactive selection between the two. By objective and subjective evaluation, we show that our method is superior to state-of-the-art approaches.
WISE: Whitebox Image Stylization by Example-based Learning
Jul 29, 2022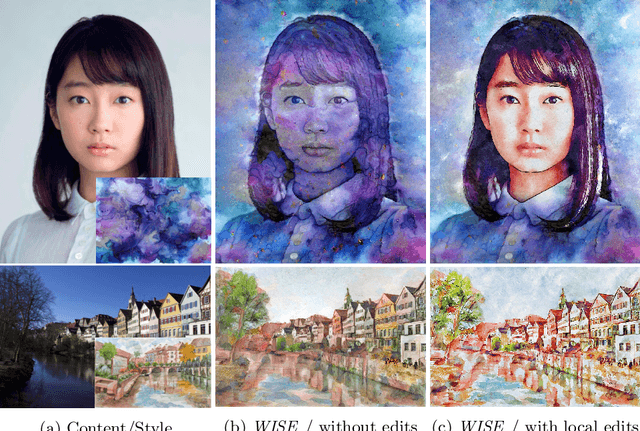
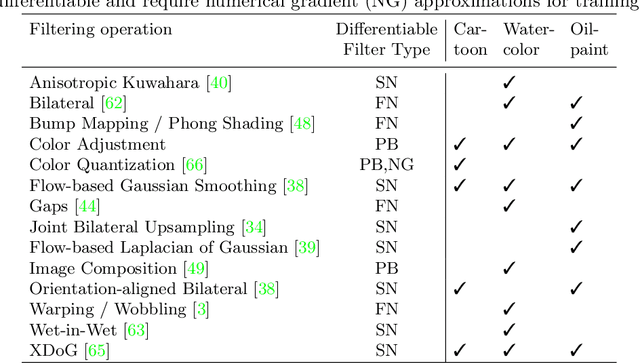
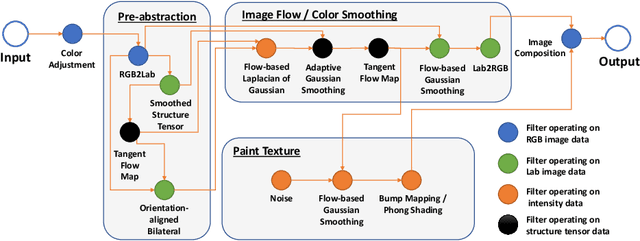
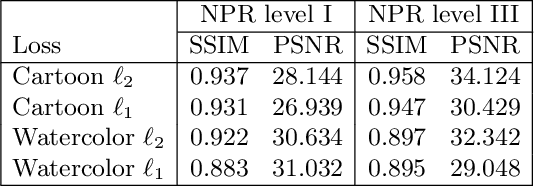
Image-based artistic rendering can synthesize a variety of expressive styles using algorithmic image filtering. In contrast to deep learning-based methods, these heuristics-based filtering techniques can operate on high-resolution images, are interpretable, and can be parameterized according to various design aspects. However, adapting or extending these techniques to produce new styles is often a tedious and error-prone task that requires expert knowledge. We propose a new paradigm to alleviate this problem: implementing algorithmic image filtering techniques as differentiable operations that can learn parametrizations aligned to certain reference styles. To this end, we present WISE, an example-based image-processing system that can handle a multitude of stylization techniques, such as watercolor, oil or cartoon stylization, within a common framework. By training parameter prediction networks for global and local filter parameterizations, we can simultaneously adapt effects to reference styles and image content, e.g., to enhance facial features. Our method can be optimized in a style-transfer framework or learned in a generative-adversarial setting for image-to-image translation. We demonstrate that jointly training an XDoG filter and a CNN for postprocessing can achieve comparable results to a state-of-the-art GAN-based method.
Low-light Image and Video Enhancement via Selective Manipulation of Chromaticity
Mar 09, 2022
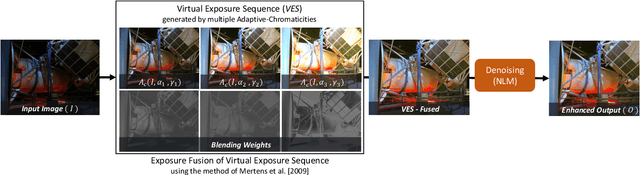
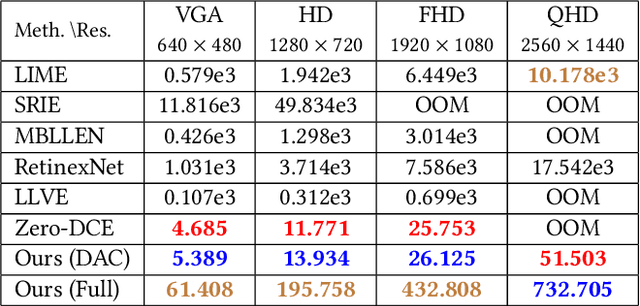

Image acquisition in low-light conditions suffers from poor quality and significant degradation in visual aesthetics. This affects the visual perception of the acquired image and the performance of various computer vision and image processing algorithms applied after acquisition. Especially for videos, the additional temporal domain makes it more challenging, wherein we need to preserve quality in a temporally coherent manner. We present a simple yet effective approach for low-light image and video enhancement. To this end, we introduce "Adaptive Chromaticity", which refers to an adaptive computation of image chromaticity. The above adaptivity allows us to avoid the costly step of low-light image decomposition into illumination and reflectance, employed by many existing techniques. All stages in our method consist of only point-based operations and high-pass or low-pass filtering, thereby ensuring that the amount of temporal incoherence is negligible when applied on a per-frame basis for videos. Our results on standard lowlight image datasets show the efficacy of our algorithm and its qualitative and quantitative superiority over several state-of-the-art techniques. For videos captured in the wild, we perform a user study to demonstrate the preference for our method in comparison to state-of-the-art approaches.
Interactive Multi-level Stroke Control for Neural Style Transfer
Jun 25, 2021
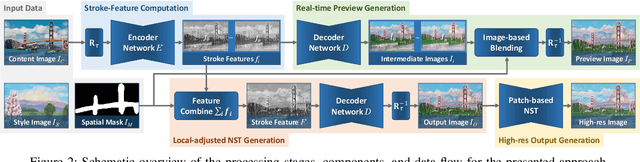

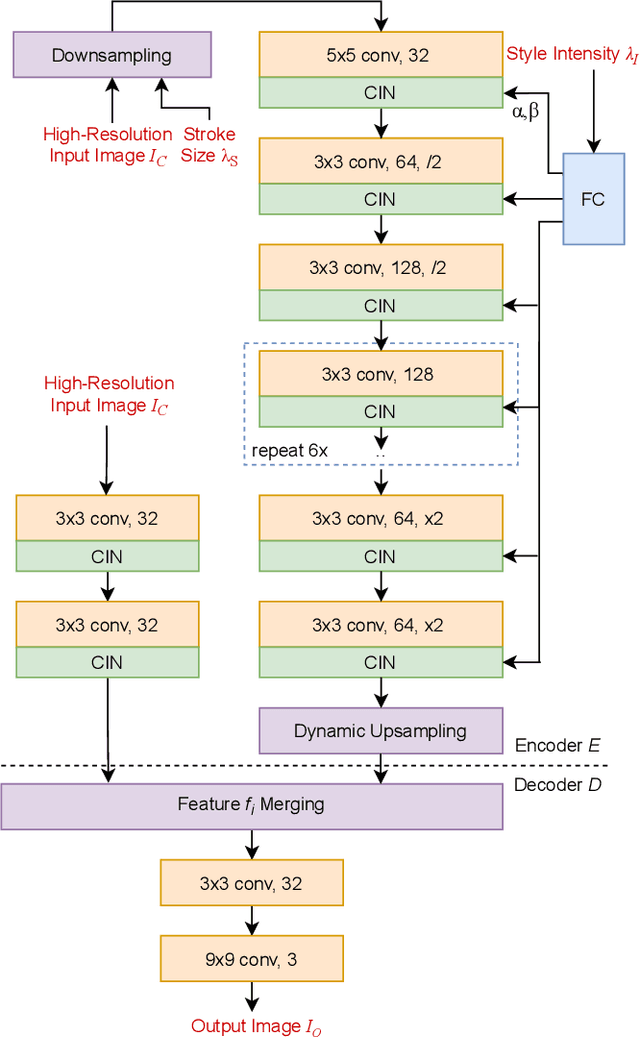
We present StyleTune, a mobile app for interactive multi-level control of neural style transfers that facilitates creative adjustments of style elements and enables high output fidelity. In contrast to current mobile neural style transfer apps, StyleTune supports users to adjust both the size and orientation of style elements, such as brushstrokes and texture patches, on a global as well as local level. To this end, we propose a novel stroke-adaptive feed-forward style transfer network, that enables control over stroke size and intensity and allows a larger range of edits than current approaches. For additional level-of-control, we propose a network agnostic method for stroke-orientation adjustment by utilizing the rotation-variance of CNNs. To achieve high output fidelity, we further add a patch-based style transfer method that enables users to obtain output resolutions of more than 20 Megapixel. Our approach empowers users to create many novel results that are not possible with current mobile neural style transfer apps.