 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCIP: Loss-Controlled Inverse Projection of High-Dimensional Image Data
Feb 11, 2026Projections (or dimensionality reduction) methods $P$ aim to map high-dimensional data to typically 2D scatterplots for visual exploration. Inverse projection methods $P^{-1}$ aim to map this 2D space to the data space to support tasks such as data augmentation, classifier analysis, and data imputation. Current $P^{-1}$ methods suffer from a fundamental limitation -- they can only generate a fixed surface-like structure in data space, which poorly covers the richness of this space. We address this by a new method that can `sweep' the data space under user control. Our method works generically for any $P$ technique and dataset, is controlled by two intuitive user-set parameters, and is simple to implement. We demonstrate it by an extensive application involving image manipulation for style transfer.
A Large-Scale Sensitivity Analysis on Latent Embeddings and Dimensionality Reductions for Text Spatializations
Jul 25, 2024
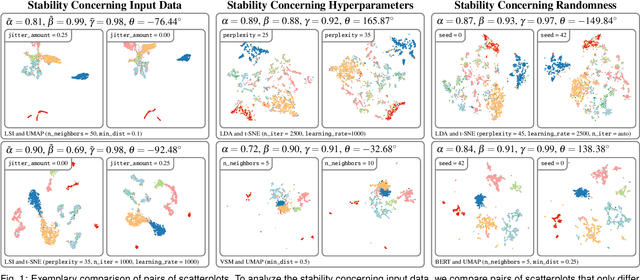

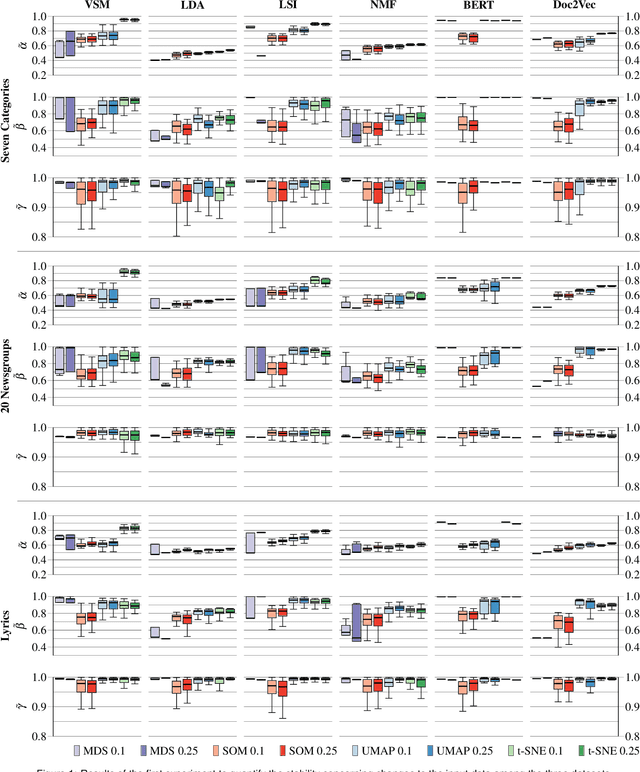
The semantic similarity between documents of a text corpus can be visualized using map-like metaphors based on two-dimensional scatterplot layouts. These layouts result from a dimensionality reduction on the document-term matrix or a representation within a latent embedding, including topic models. Thereby, the resulting layout depends on the input data and hyperparameters of the dimensionality reduction and is therefore affected by changes in them. Furthermore, the resulting layout is affected by changes in the input data and hyperparameters of the dimensionality reduction. However, such changes to the layout require additional cognitive efforts from the user. In this work, we present a sensitivity study that analyzes the stability of these layouts concerning (1) changes in the text corpora, (2) changes in the hyperparameter, and (3) randomness in the initialization. Our approach has two stages: data measurement and data analysis. First, we derived layouts for the combination of three text corpora and six text embeddings and a grid-search-inspired hyperparameter selection of the dimensionality reductions. Afterward, we quantified the similarity of the layouts through ten metrics, concerning local and global structures and class separation. Second, we analyzed the resulting 42817 tabular data points in a descriptive statistical analysis. From this, we derived guidelines for informed decisions on the layout algorithm and highlight specific hyperparameter settings. We provide our implementation as a Git repository at https://github.com/hpicgs/Topic-Models-and-Dimensionality-Reduction-Sensitivity-Study and results as Zenodo archive at https://doi.org/10.5281/zenodo.12772898.
ShaRP: Shape-Regularized Multidimensional Projections
Jun 01, 2023



Projections, or dimensionality reduction methods, are techniques of choice for the visual exploration of high-dimensional data. Many such techniques exist, each one of them having a distinct visual signature - i.e., a recognizable way to arrange points in the resulting scatterplot. Such signatures are implicit consequences of algorithm design, such as whether the method focuses on local vs global data pattern preservation; optimization techniques; and hyperparameter settings. We present a novel projection technique - ShaRP - that provides users explicit control over the visual signature of the created scatterplot, which can cater better to interactive visualization scenarios. ShaRP scales well with dimensionality and dataset size, generically handles any quantitative dataset, and provides this extended functionality of controlling projection shapes at a small, user-controllable cost in terms of quality metrics.
PSEUDo: Interactive Pattern Search in Multivariate Time Series with Locality-Sensitive Hashing and Relevance Feedback
May 10, 2021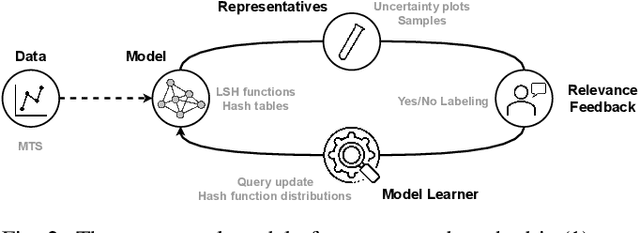
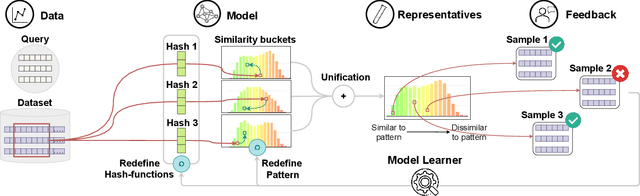
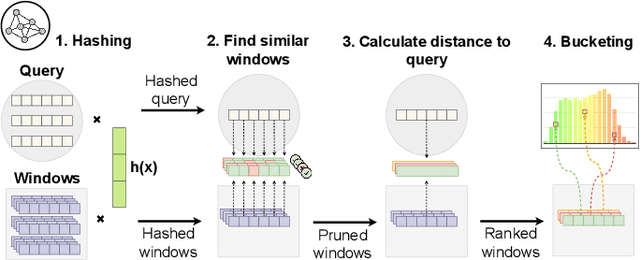
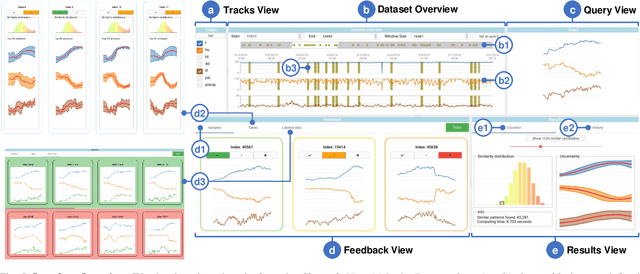
We present PSEUDo, an adaptive feature learning technique for exploring visual patterns in multi-track sequential data. Our approach is designed with the primary focus to overcome the uneconomic retraining requirements and inflexible representation learning in current deep learning-based systems. Multi-track time series data are generated on an unprecedented scale due to increased sensors and data storage. These datasets hold valuable patterns, like in neuromarketing, where researchers try to link patterns in multivariate sequential data from physiological sensors to the purchase behavior of products and services. But a lack of ground truth and high variance make automatic pattern detection unreliable. Our advancements are based on a novel query-aware locality-sensitive hashing technique to create a feature-based representation of multivariate time series windows. Most importantly, our algorithm features sub-linear training and inference time. We can even accomplish both the modeling and comparison of 10,000 different 64-track time series, each with 100 time steps (a typical EEG dataset) under 0.8 seconds. This performance gain allows for a rapid relevance feedback-driven adaption of the underlying pattern similarity model and enables the user to modify the speed-vs-accuracy trade-off gradually. We demonstrate superiority of PSEUDo in terms of efficiency, accuracy, and steerability through a quantitative performance comparison and a qualitative visual quality comparison to the state-of-the-art algorithms in the field. Moreover, we showcase the usability of PSEUDo through a case study demonstrating our visual pattern retrieval concepts in a large meteorological dataset. We find that our adaptive models can accurately capture the user's notion of similarity and allow for an understandable exploratory visual pattern retrieval in large multivariate time series datasets.
FDive: Learning Relevance Models using Pattern-based Similarity Measures
Jul 30, 2019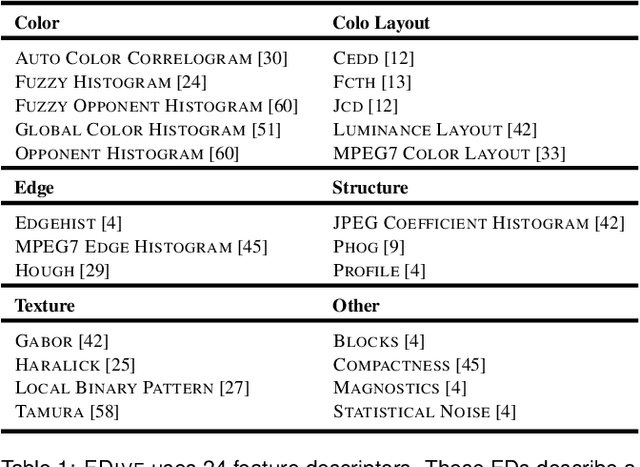
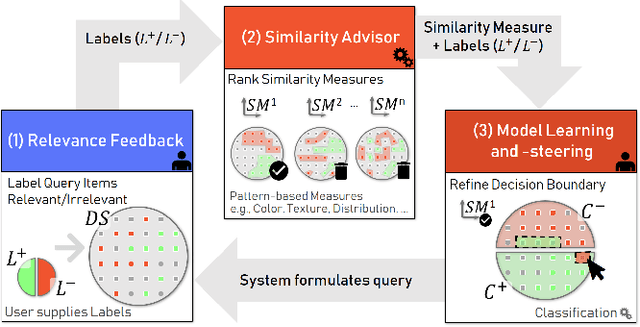
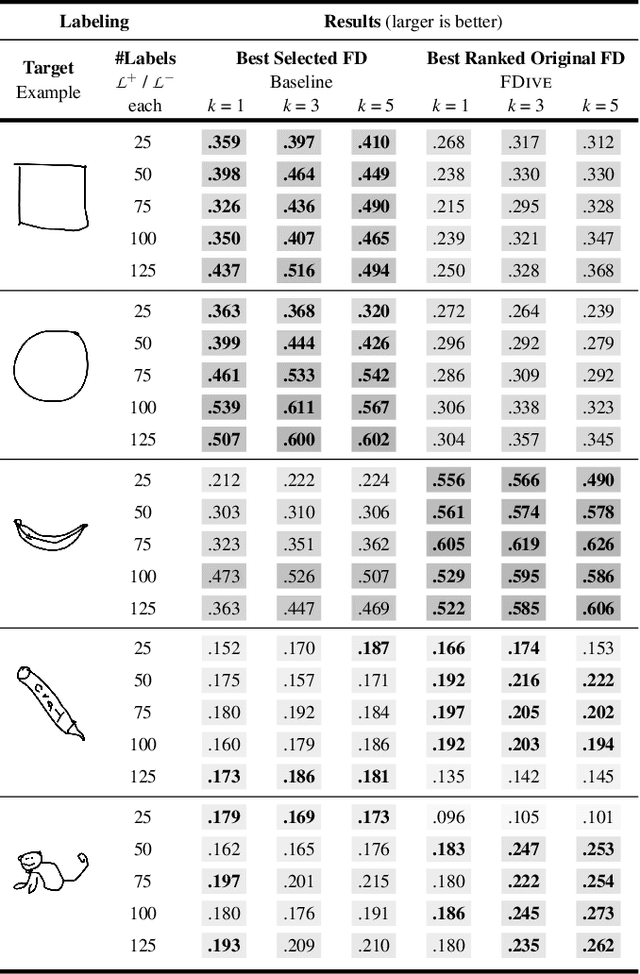
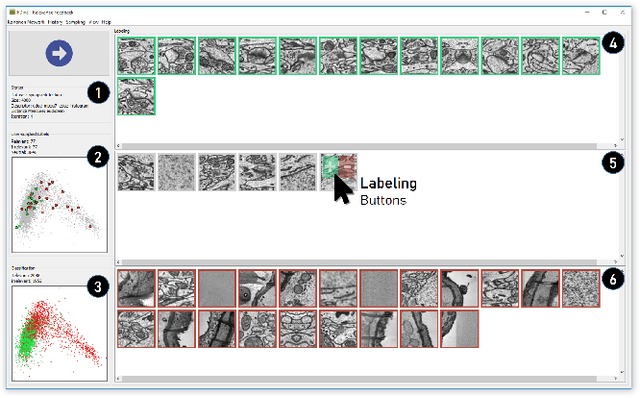
The detection of interesting patterns in large high-dimensional datasets is difficult because of their dimensionality and pattern complexity. Therefore, analysts require automated support for the extraction of relevant patterns. In this paper, we present FDive, a visual active learning system that helps to create visually explorable relevance models, assisted by learning a pattern-based similarity. We use a small set of user-provided labels to rank similarity measures, consisting of feature descriptor and distance function combinations, by their ability to distinguish relevant from irrelevant data. Based on the best-ranked similarity measure, the system calculates an interactive Self-Organizing Map-based relevance model, which classifies data according to the cluster affiliation. It also automatically prompts further relevance feedback to improve its accuracy. Uncertain areas, especially near the decision boundaries, are highlighted and can be refined by the user. We evaluate our approach by comparison to state-of-the-art feature selection techniques and demonstrate the usefulness of our approach by a case study classifying electron microscopy images of brain cells. The results show that FDive enhances both the quality and understanding of relevance models and can thus lead to new insights for brain research.
Seq2Seq-Vis: A Visual Debugging Tool for Sequence-to-Sequence Models
Oct 16, 2018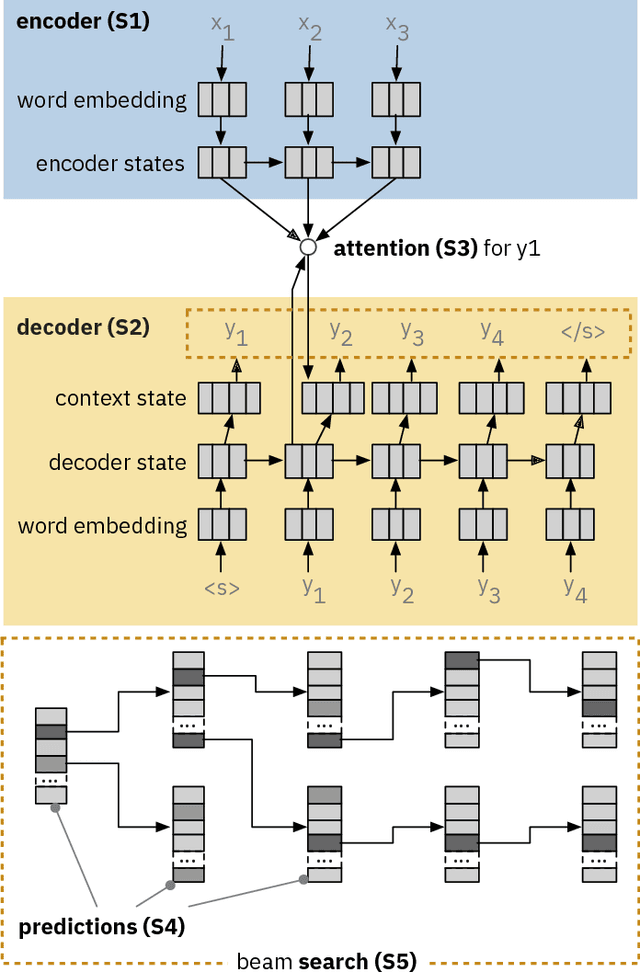
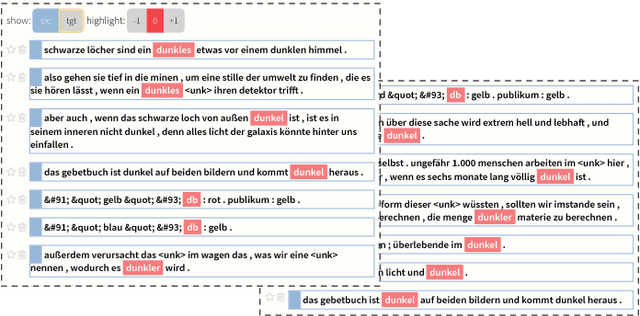
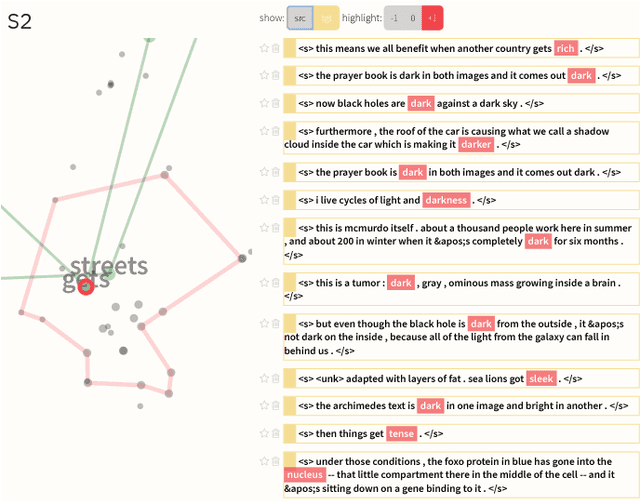
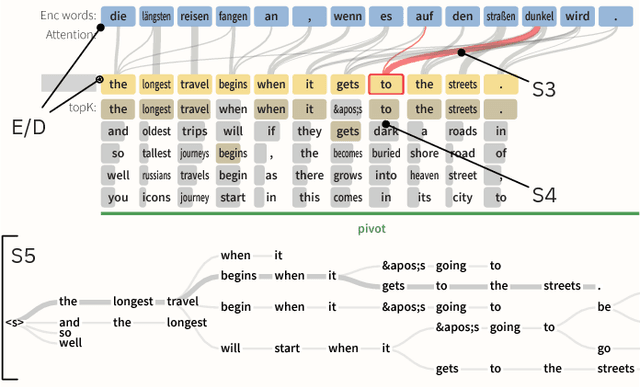
Neural Sequence-to-Sequence models have proven to be accurate and robust for many sequence prediction tasks, and have become the standard approach for automatic translation of text. The models work in a five stage blackbox process that involves encoding a source sequence to a vector space and then decoding out to a new target sequence. This process is now standard, but like many deep learning methods remains quite difficult to understand or debug. In this work, we present a visual analysis tool that allows interaction with a trained sequence-to-sequence model through each stage of the translation process. The aim is to identify which patterns have been learned and to detect model errors. We demonstrate the utility of our tool through several real-world large-scale sequence-to-sequence use cases.