 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Sensitivity Analysis on Latent Embeddings and Dimensionality Reductions for Text Spatializations
Jul 25, 2024
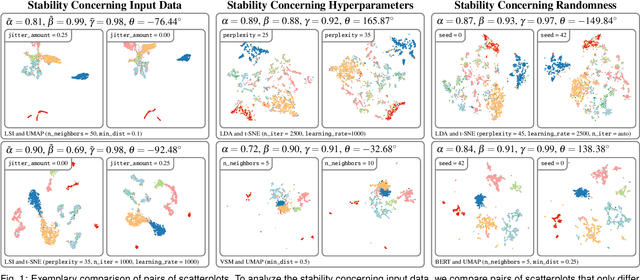

The semantic similarity between documents of a text corpus can be visualized using map-like metaphors based on two-dimensional scatterplot layouts. These layouts result from a dimensionality reduction on the document-term matrix or a representation within a latent embedding, including topic models. Thereby, the resulting layout depends on the input data and hyperparameters of the dimensionality reduction and is therefore affected by changes in them. Furthermore, the resulting layout is affected by changes in the input data and hyperparameters of the dimensionality reduction. However, such changes to the layout require additional cognitive efforts from the user. In this work, we present a sensitivity study that analyzes the stability of these layouts concerning (1) changes in the text corpora, (2) changes in the hyperparameter, and (3) randomness in the initialization. Our approach has two stages: data measurement and data analysis. First, we derived layouts for the combination of three text corpora and six text embeddings and a grid-search-inspired hyperparameter selection of the dimensionality reductions. Afterward, we quantified the similarity of the layouts through ten metrics, concerning local and global structures and class separation. Second, we analyzed the resulting 42817 tabular data points in a descriptive statistical analysis. From this, we derived guidelines for informed decisions on the layout algorithm and highlight specific hyperparameter settings. We provide our implementation as a Git repository at https://github.com/hpicgs/Topic-Models-and-Dimensionality-Reduction-Sensitivity-Study and results as Zenodo archive at https://doi.org/10.5281/zenodo.12772898.
Standardness Fogs Meaning: A Position Regarding the Informed Usage of Standard Datasets
Jun 19, 2024



Standard datasets are frequently used to train and evaluate Machine Learning models. However, the assumed standardness of these datasets leads to a lack of in-depth discussion on how their labels match the derived categories for the respective use case. In other words, the standardness of the datasets seems to fog coherency and applicability, thus impeding the trust in Machine Learning models. We propose to adopt Grounded Theory and Hypotheses Testing through Visualization as methods to evaluate the match between use case, derived categories, and labels of standard datasets. To showcase the approach, we apply it to the 20 Newsgroups dataset and the MNIST dataset. For the 20 Newsgroups dataset, we demonstrate that the labels are imprecise. Therefore, we argue that neither a Machine Learning model can learn a meaningful abstraction of derived categories nor one can draw conclusions from achieving high accuracy. For the MNIST dataset, we demonstrate how the labels can be confirmed to be defined well. We conclude that a concept of standardness of a dataset implies that there is a match between use case, derived categories, and class labels, as in the case of the MNIST dataset. We argue that this is necessary to learn a meaningful abstraction and, thus, improve trust in the Machine Learning model.
Large-Scale Evaluation of Topic Models and Dimensionality Reduction Methods for 2D Text Spatialization
Jul 17, 2023



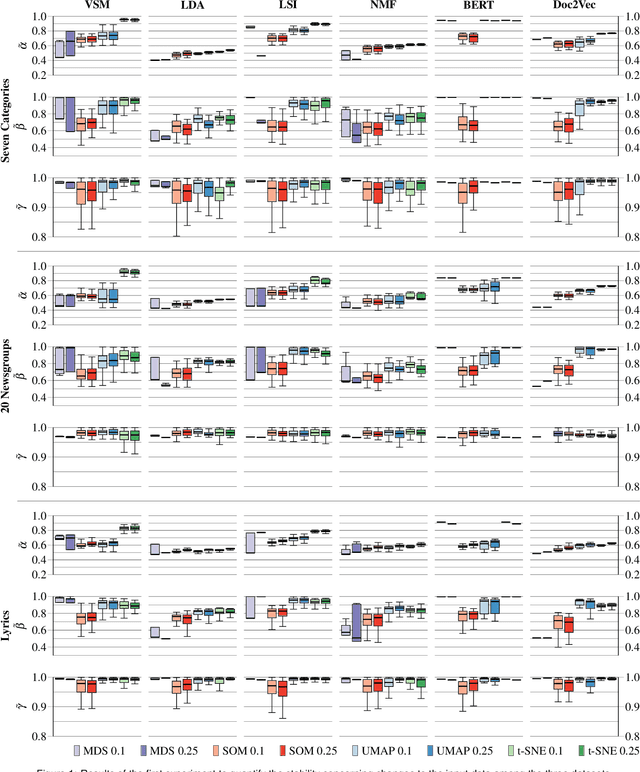
Topic models are a class of unsupervised learning algorithms for detecting the semantic structure within a text corpus. Together with a subsequent dimensionality reduction algorithm, topic models can be used for deriving spatializations for text corpora as two-dimensional scatter plots, reflecting semantic similarity between the documents and supporting corpus analysis. Although the choice of the topic model, the dimensionality reduction, and their underlying hyperparameters significantly impact the resulting layout, it is unknown which particular combinations result in high-quality layouts with respect to accuracy and perception metrics. To investigate the effectiveness of topic models and dimensionality reduction methods for the spatialization of corpora as two-dimensional scatter plots (or basis for landscape-type visualizations), we present a large-scale, benchmark-based computational evaluation. Our evaluation consists of (1) a set of corpora, (2) a set of layout algorithms that are combinations of topic models and dimensionality reductions, and (3) quality metrics for quantifying the resulting layout. The corpora are given as document-term matrices, and each document is assigned to a thematic class. The chosen metrics quantify the preservation of local and global properties and the perceptual effectiveness of the two-dimensional scatter plots. By evaluating the benchmark on a computing cluster, we derived a multivariate dataset with over 45 000 individual layouts and corresponding quality metrics. Based on the results, we propose guidelines for the effective design of text spatializations that are based on topic models and dimensionality reductions. As a main result, we show that interpretable topic models are beneficial for capturing the structure of text corpora. We furthermore recommend the use of t-SNE as a subsequent dimensionality reduction.