 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifference Views for Visual Graph Query Building
Aug 07, 2025Knowledge Graphs (KGs) contain vast amounts of linked resources that encode knowledge in various domains, which can be queried and searched for using specialized languages like SPARQL, a query language developed to query KGs. Existing visual query builders enable non-expert users to construct SPARQL queries and utilize the knowledge contained in these graphs. Query building is, however, an iterative and, often, visual process where the question of the user can change and differ throughout the process, especially for explorative search. Our visual querying interface communicates these change between iterative steps in the query building process using graph differences to contrast the changes and the evolution in the graph query. We also enable users to formulate their evolving information needs using a natural language interface directly integrated into the difference query view. We, furthermore, communicate the change in results in the result view by contrasting the differences in both result distribution and individual instances of the prototype graph and demonstrate the system's applicability through case studies on different ontologies and usage scenarios, illustrating how our system fosters, both, data exploration and analysis of domain-specific graphs.
OnSET: Ontology and Semantic Exploration Toolkit
Apr 11, 2025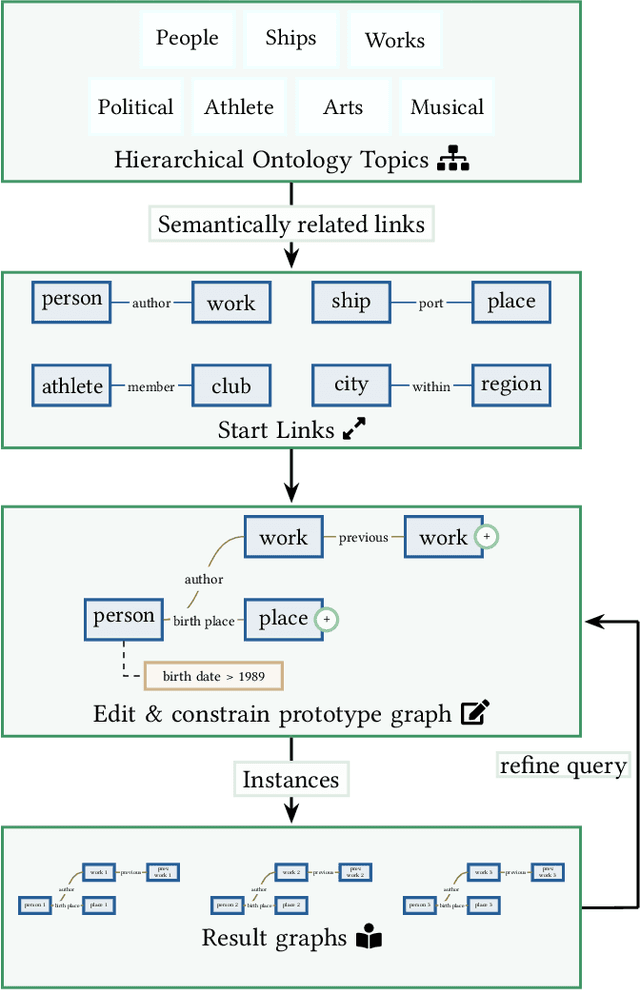
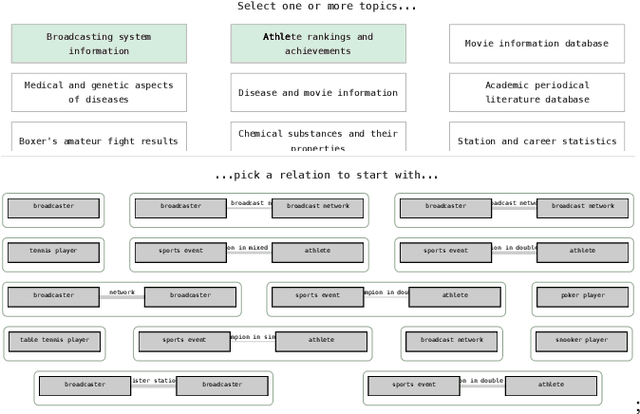
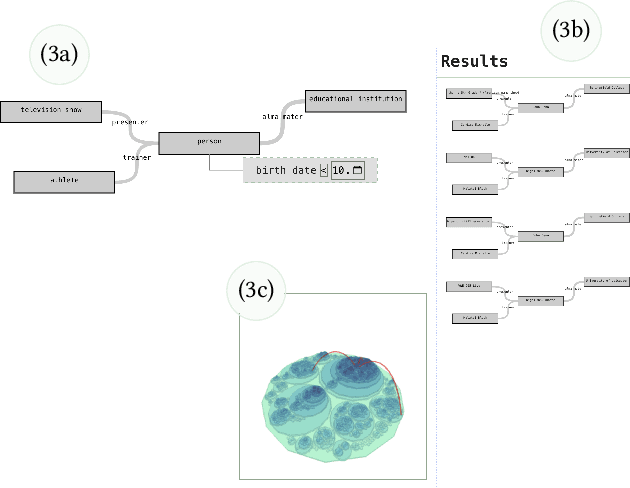
Retrieval over knowledge graphs is usually performed using dedicated, complex query languages like SPARQL. We propose a novel system, Ontology and Semantic Exploration Toolkit (OnSET) that allows non-expert users to easily build queries with visual user guidance provided by topic modelling and semantic search throughout the application. OnSET allows users without any prior information about the ontology or networked knowledge to start exploring topics of interest over knowledge graphs, including the retrieval and detailed exploration of prototypical sub-graphs and their instances. Existing systems either focus on direct graph explorations or do not foster further exploration of the result set. We, however, provide a node-based editor that can extend on these missing properties of existing systems to support the search over big ontologies with sub-graph instances. Furthermore, OnSET combines efficient and open platforms to deploy the system on commodity hardware.
A Large-Scale Sensitivity Analysis on Latent Embeddings and Dimensionality Reductions for Text Spatializations
Jul 25, 2024
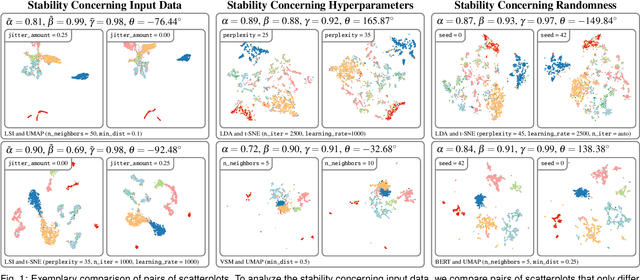

The semantic similarity between documents of a text corpus can be visualized using map-like metaphors based on two-dimensional scatterplot layouts. These layouts result from a dimensionality reduction on the document-term matrix or a representation within a latent embedding, including topic models. Thereby, the resulting layout depends on the input data and hyperparameters of the dimensionality reduction and is therefore affected by changes in them. Furthermore, the resulting layout is affected by changes in the input data and hyperparameters of the dimensionality reduction. However, such changes to the layout require additional cognitive efforts from the user. In this work, we present a sensitivity study that analyzes the stability of these layouts concerning (1) changes in the text corpora, (2) changes in the hyperparameter, and (3) randomness in the initialization. Our approach has two stages: data measurement and data analysis. First, we derived layouts for the combination of three text corpora and six text embeddings and a grid-search-inspired hyperparameter selection of the dimensionality reductions. Afterward, we quantified the similarity of the layouts through ten metrics, concerning local and global structures and class separation. Second, we analyzed the resulting 42817 tabular data points in a descriptive statistical analysis. From this, we derived guidelines for informed decisions on the layout algorithm and highlight specific hyperparameter settings. We provide our implementation as a Git repository at https://github.com/hpicgs/Topic-Models-and-Dimensionality-Reduction-Sensitivity-Study and results as Zenodo archive at https://doi.org/10.5281/zenodo.12772898.
Cross-Modal Search and Exploration of Greek Painted Pottery
Nov 17, 2023This paper focuses on digitally-supported research methods for an important group of cultural heritage objects, the Greek pottery, especially with figured decoration. The design, development and application of new digital methods for searching, comparing, and visually exploring these vases needs an interdisciplinary approach to effectively analyse the various features of the vases, like shape, decoration, and manufacturing techniques, and relationships between the vases. We motivate the need and opportunities by a multimodal representation of the objects, including 3D shape, material, and painting. We then illustrate a range of innovative methods for these representations, including quantified surface and capacity comparison, material analysis, image flattening from 3D objects, retrieval and comparison of shapes and paintings, and multidimensional data visualization. We also discuss challenges and future work in this area.
Large-Scale Evaluation of Topic Models and Dimensionality Reduction Methods for 2D Text Spatialization
Jul 17, 2023



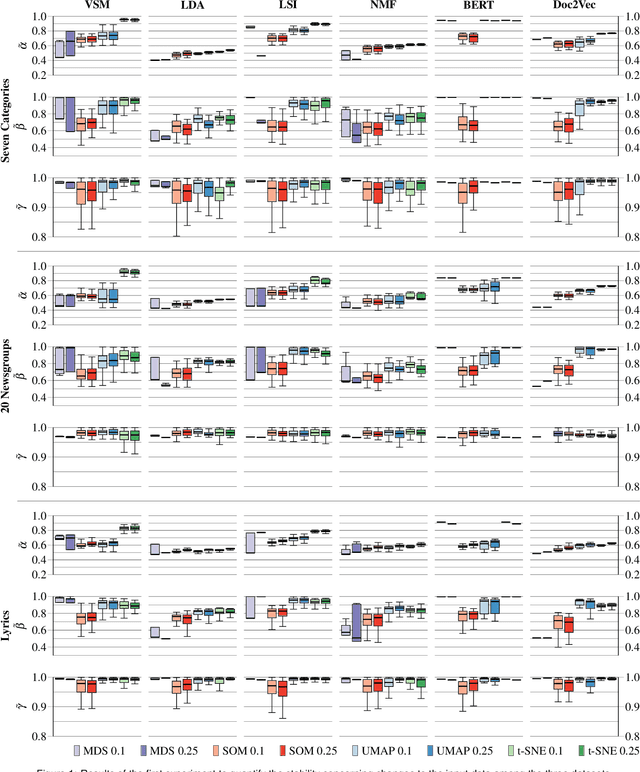
Topic models are a class of unsupervised learning algorithms for detecting the semantic structure within a text corpus. Together with a subsequent dimensionality reduction algorithm, topic models can be used for deriving spatializations for text corpora as two-dimensional scatter plots, reflecting semantic similarity between the documents and supporting corpus analysis. Although the choice of the topic model, the dimensionality reduction, and their underlying hyperparameters significantly impact the resulting layout, it is unknown which particular combinations result in high-quality layouts with respect to accuracy and perception metrics. To investigate the effectiveness of topic models and dimensionality reduction methods for the spatialization of corpora as two-dimensional scatter plots (or basis for landscape-type visualizations), we present a large-scale, benchmark-based computational evaluation. Our evaluation consists of (1) a set of corpora, (2) a set of layout algorithms that are combinations of topic models and dimensionality reductions, and (3) quality metrics for quantifying the resulting layout. The corpora are given as document-term matrices, and each document is assigned to a thematic class. The chosen metrics quantify the preservation of local and global properties and the perceptual effectiveness of the two-dimensional scatter plots. By evaluating the benchmark on a computing cluster, we derived a multivariate dataset with over 45 000 individual layouts and corresponding quality metrics. Based on the results, we propose guidelines for the effective design of text spatializations that are based on topic models and dimensionality reductions. As a main result, we show that interpretable topic models are beneficial for capturing the structure of text corpora. We furthermore recommend the use of t-SNE as a subsequent dimensionality reduction.
SMAP: A Joint Dimensionality Reduction Scheme for Secure Multi-Party Visualization
Jul 30, 2020
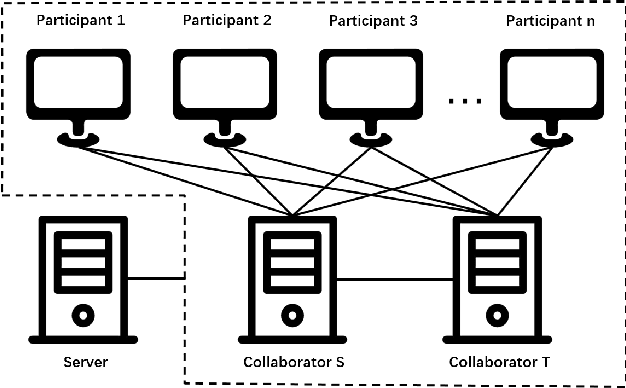

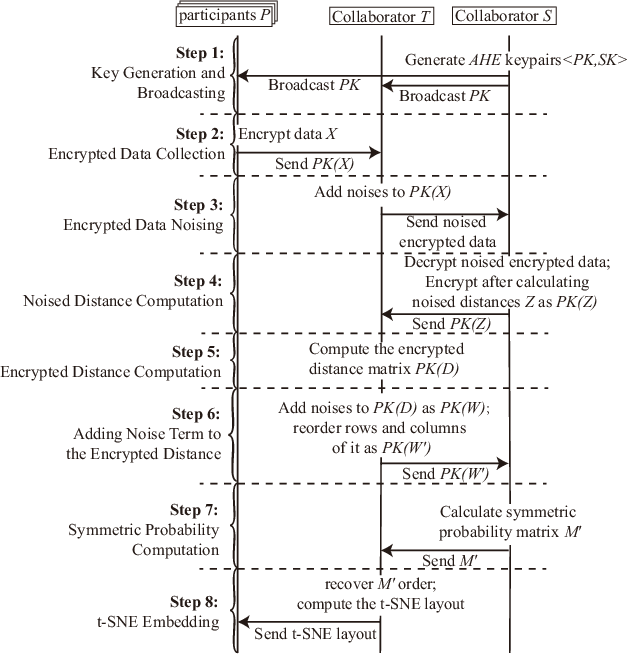
Nowadays, as data becomes increasingly complex and distributed, data analyses often involve several related datasets that are stored on different servers and probably owned by different stakeholders. While there is an emerging need to provide these stakeholders with a full picture of their data under a global context, conventional visual analytical methods, such as dimensionality reduction, could expose data privacy when multi-party datasets are fused into a single site to build point-level relationships. In this paper, we reformulate the conventional t-SNE method from the single-site mode into a secure distributed infrastructure. We present a secure multi-party scheme for joint t-SNE computation, which can minimize the risk of data leakage. Aggregated visualization can be optionally employed to hide disclosure of point-level relationships. We build a prototype system based on our method, SMAP, to support the organization, computation, and exploration of secure joint embedding. We demonstrate the effectiveness of our approach with three case studies, one of which is based on the deployment of our system in real-world applications.
FDive: Learning Relevance Models using Pattern-based Similarity Measures
Jul 30, 2019
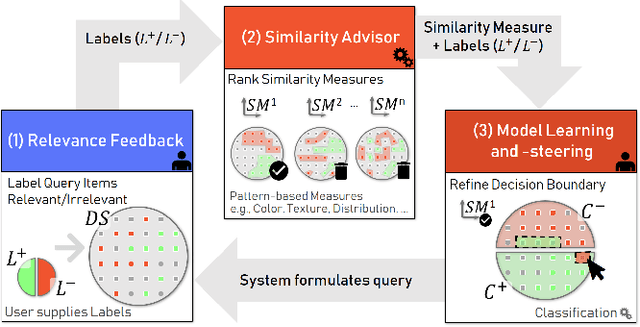
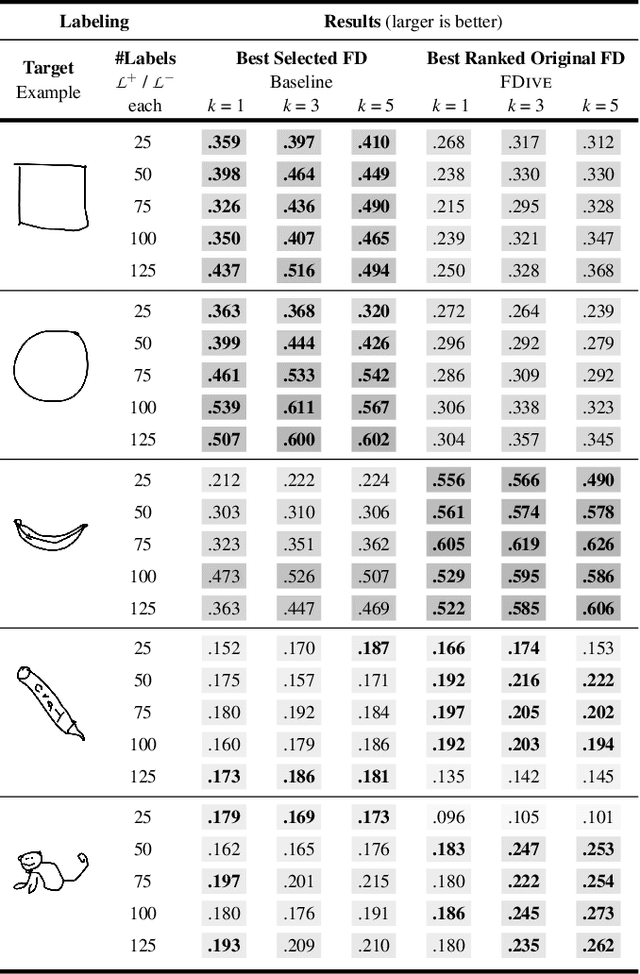
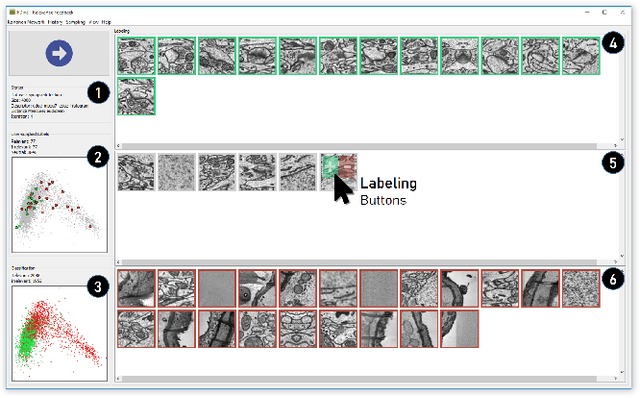
The detection of interesting patterns in large high-dimensional datasets is difficult because of their dimensionality and pattern complexity. Therefore, analysts require automated support for the extraction of relevant patterns. In this paper, we present FDive, a visual active learning system that helps to create visually explorable relevance models, assisted by learning a pattern-based similarity. We use a small set of user-provided labels to rank similarity measures, consisting of feature descriptor and distance function combinations, by their ability to distinguish relevant from irrelevant data. Based on the best-ranked similarity measure, the system calculates an interactive Self-Organizing Map-based relevance model, which classifies data according to the cluster affiliation. It also automatically prompts further relevance feedback to improve its accuracy. Uncertain areas, especially near the decision boundaries, are highlighted and can be refined by the user. We evaluate our approach by comparison to state-of-the-art feature selection techniques and demonstrate the usefulness of our approach by a case study classifying electron microscopy images of brain cells. The results show that FDive enhances both the quality and understanding of relevance models and can thus lead to new insights for brain research.