 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistopathology Image Normalization via Latent Manifold Compaction
Feb 27, 2026Batch effects arising from technical variations in histopathology staining protocols, scanners, and acquisition pipelines pose a persistent challenge for computational pathology, hindering cross-batch generalization and limiting reliable deployment of models across clinical sites. In this work, we introduce Latent Manifold Compaction (LMC), an unsupervised representation learning framework that performs image harmonization by learning batch-invariant embeddings from a single source dataset through explicit compaction of stain-induced latent manifolds. This allows LMC to generalize to target domain data unseen during training. Evaluated on three challenging public and in-house benchmarks, LMC substantially reduces batch-induced separations across multiple datasets and consistently outperforms state-of-the-art normalization methods in downstream cross-batch classification and detection tasks, enabling superior generalization.
Cross-Fusion Distance: A Novel Metric for Measuring Fusion and Separability Between Data Groups in Representation Space
Jan 29, 2026Quantifying degrees of fusion and separability between data groups in representation space is a fundamental problem in representation learning, particularly under domain shift. A meaningful metric should capture fusion-altering factors like geometric displacement between representation groups, whose variations change the extent of fusion, while remaining invariant to fusion-preserving factors such as global scaling and sampling-induced layout changes, whose variations do not. Existing distributional distance metrics conflate these factors, leading to measures that are not informative of the true extent of fusion between data groups. We introduce Cross-Fusion Distance (CFD), a principled measure that isolates fusion-altering geometry while remaining robust to fusion-preserving variations, with linear computational complexity. We characterize the invariance and sensitivity properties of CFD theoretically and validate them in controlled synthetic experiments. For practical utility on real-world datasets with domain shift, CFD aligns more closely with downstream generalization degradation than commonly used alternatives. Overall, CFD provides a theoretically grounded and interpretable distance measure for representation learning.
Rapid and Accurate Diagnosis of Acute Aortic Syndrome using Non-contrast CT: A Large-scale, Retrospective, Multi-center and AI-based Study
Jun 25, 2024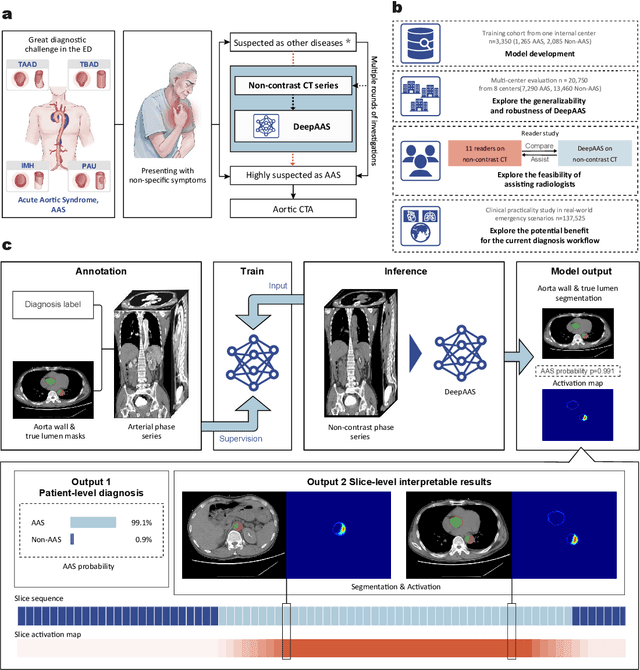
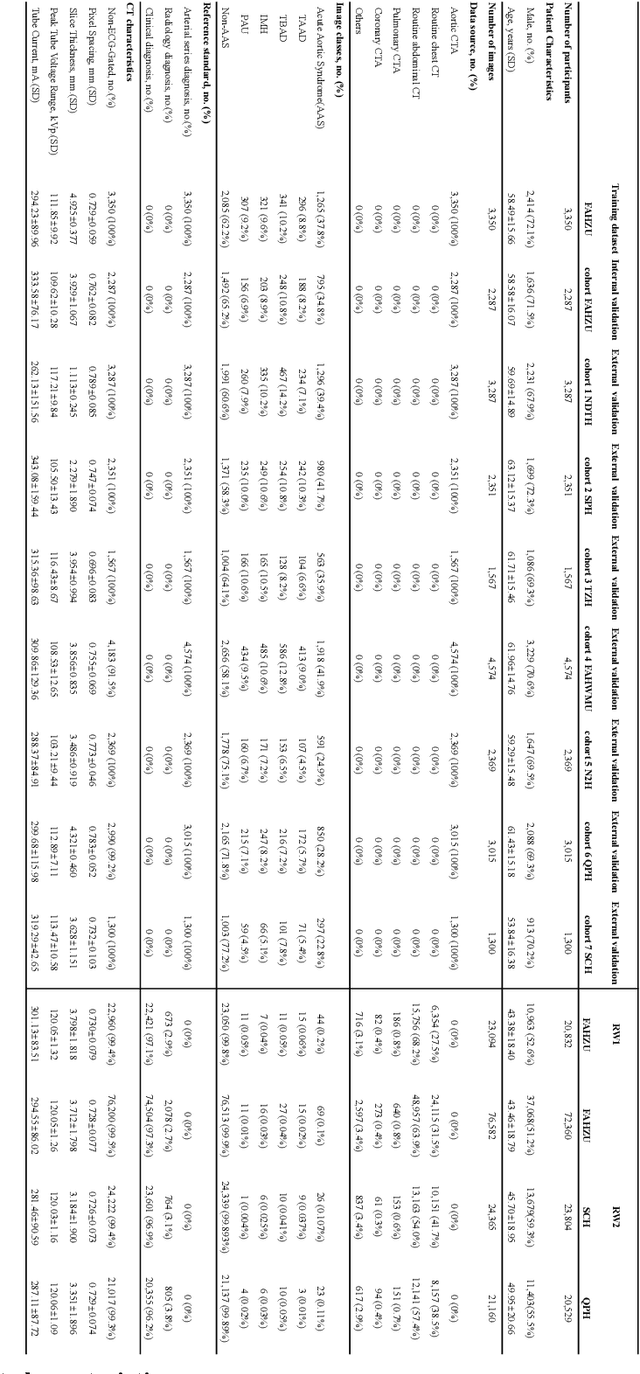
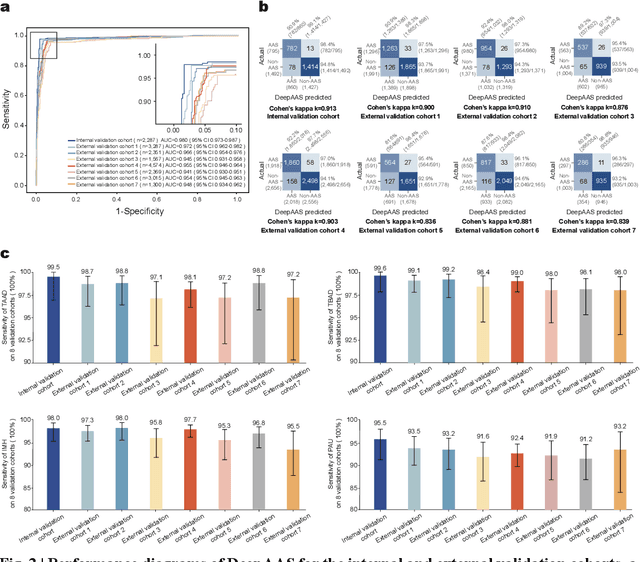
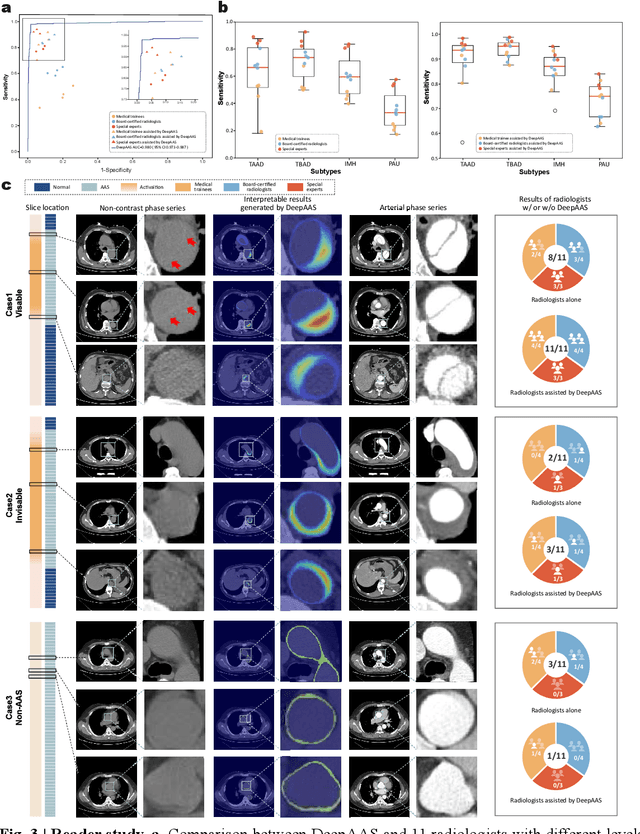
Chest pain symptoms are highly prevalent in emergency departments (EDs), where acute aortic syndrome (AAS) is a catastrophic cardiovascular emergency with a high fatality rate, especially when timely and accurate treatment is not administered. However, current triage practices in the ED can cause up to approximately half of patients with AAS to have an initially missed diagnosis or be misdiagnosed as having other acute chest pain conditions. Subsequently, these AAS patients will undergo clinically inaccurate or suboptimal differential diagnosis. Fortunately, even under these suboptimal protocols, nearly all these patients underwent non-contrast CT covering the aorta anatomy at the early stage of differential diagnosis. In this study, we developed an artificial intelligence model (DeepAAS) using non-contrast CT, which is highly accurate for identifying AAS and provides interpretable results to assist in clinical decision-making. Performance was assessed in two major phases: a multi-center retrospective study (n = 20,750) and an exploration in real-world emergency scenarios (n = 137,525). In the multi-center cohort, DeepAAS achieved a mean area under the receiver operating characteristic curve of 0.958 (95% CI 0.950-0.967). In the real-world cohort, DeepAAS detected 109 AAS patients with misguided initial suspicion, achieving 92.6% (95% CI 76.2%-97.5%) in mean sensitivity and 99.2% (95% CI 99.1%-99.3%) in mean specificity. Our AI model performed well on non-contrast CT at all applicable early stages of differential diagnosis workflows, effectively reduced the overall missed diagnosis and misdiagnosis rate from 48.8% to 4.8% and shortened the diagnosis time for patients with misguided initial suspicion from an average of 681.8 (74-11,820) mins to 68.5 (23-195) mins. DeepAAS could effectively fill the gap in the current clinical workflow without requiring additional tests.
RPN: A Word Vector Level Data Augmentation Algorithm in Deep Learning for Language Understanding
Dec 12, 2022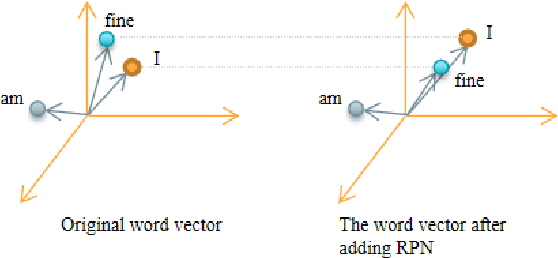
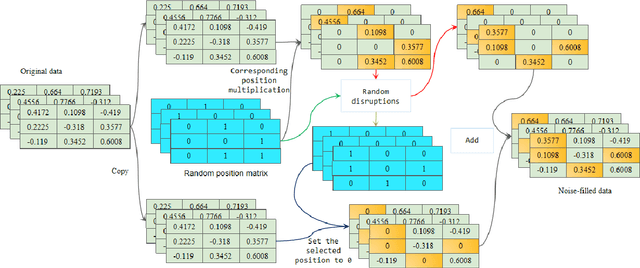
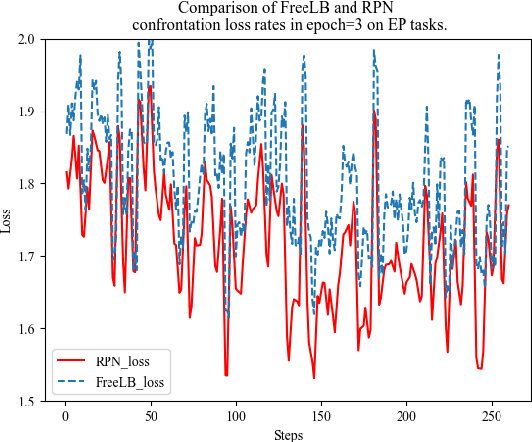
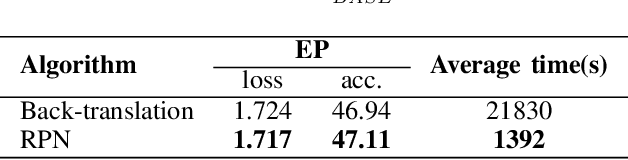
This paper presents a new data augmentation algorithm for natural understanding tasks, called RPN:Random Position Noise algorithm.Due to the relative paucity of current text augmentation methods. Few of the extant methods apply to natural language understanding tasks for all sentence-level tasks.RPN applies the traditional augmentation on the original text to the word vector level. The RPN algorithm makes a substitution in one or several dimensions of some word vectors. As a result, the RPN can introduce a certain degree of perturbation to the sample and can adjust the range of perturbation on different tasks. The augmented samples are then used to give the model training.This makes the model more robust. In subsequent experiments, we found that adding RPN to the training or fine-tuning model resulted in a stable boost on all 8 natural language processing tasks, including TweetEval, CoLA, and SST-2 datasets, and more significant improvements than other data augmentation algorithms.The RPN algorithm applies to all sentence-level tasks for language understanding and is used in any deep learning model with a word embedding layer.
EventAnchor: Reducing Human Interactions in Event Annotation of Racket Sports Videos
Jan 14, 2021

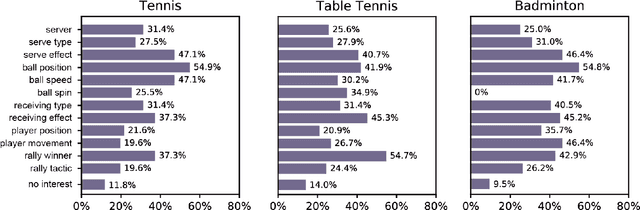
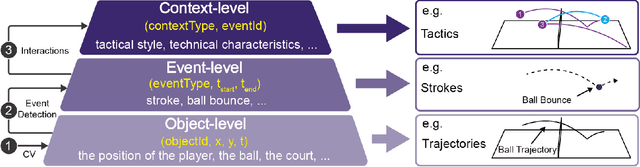
The popularity of racket sports (e.g., tennis and table tennis) leads to high demands for data analysis, such as notational analysis, on player performance. While sports videos offer many benefits for such analysis, retrieving accurate information from sports videos could be challenging. In this paper, we propose EventAnchor, a data analysis framework to facilitate interactive annotation of racket sports video with the support of computer vision algorithms. Our approach uses machine learning models in computer vision to help users acquire essential events from videos (e.g., serve, the ball bouncing on the court) and offers users a set of interactive tools for data annotation. An evaluation study on a table tennis annotation system built on this framework shows significant improvement of user performances in simple annotation tasks on objects of interest and complex annotation tasks requiring domain knowledge.
Exploring Image Enhancement for Salient Object Detection in Low Light Images
Jul 31, 2020
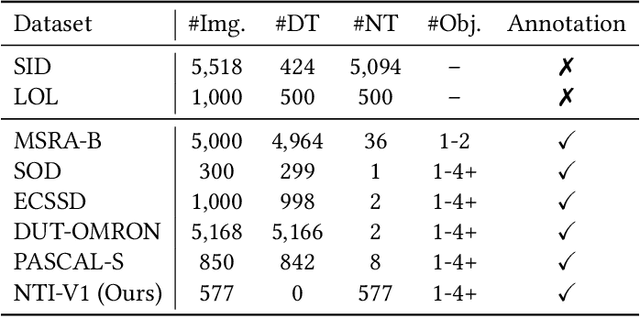
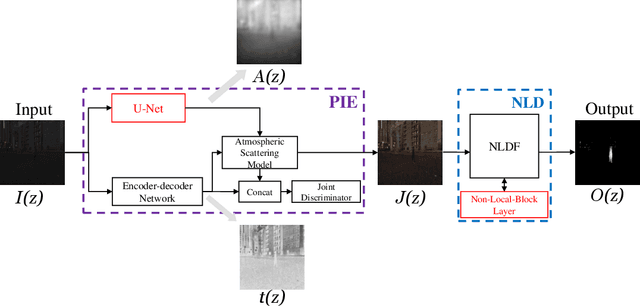
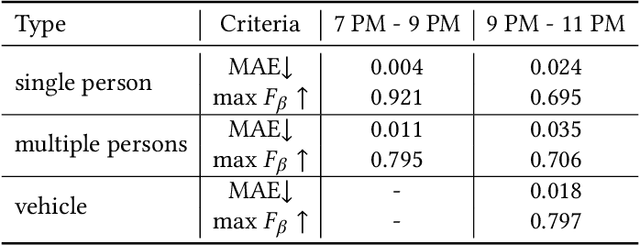
Low light images captured in a non-uniform illumination environment usually are degraded with the scene depth and the corresponding environment lights. This degradation results in severe object information loss in the degraded image modality, which makes the salient object detection more challenging due to low contrast property and artificial light influence. However, existing salient object detection models are developed based on the assumption that the images are captured under a sufficient brightness environment, which is impractical in real-world scenarios. In this work, we propose an image enhancement approach to facilitate the salient object detection in low light images. The proposed model directly embeds the physical lighting model into the deep neural network to describe the degradation of low light images, in which the environment light is treated as a point-wise variate and changes with local content. Moreover, a Non-Local-Block Layer is utilized to capture the difference of local content of an object against its local neighborhood favoring regions. To quantitative evaluation, we construct a low light Images dataset with pixel-level human-labeled ground-truth annotations and report promising results on four public datasets and our benchmark dataset.
SMAP: A Joint Dimensionality Reduction Scheme for Secure Multi-Party Visualization
Jul 30, 2020
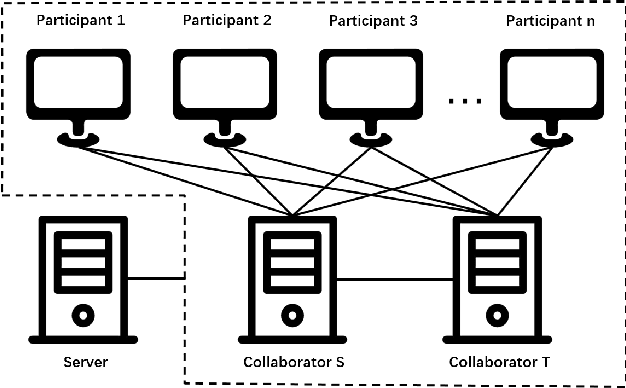

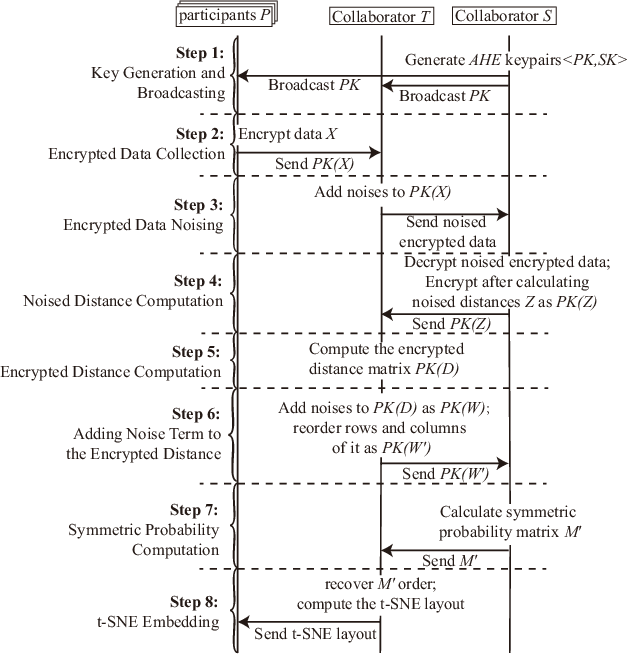
Nowadays, as data becomes increasingly complex and distributed, data analyses often involve several related datasets that are stored on different servers and probably owned by different stakeholders. While there is an emerging need to provide these stakeholders with a full picture of their data under a global context, conventional visual analytical methods, such as dimensionality reduction, could expose data privacy when multi-party datasets are fused into a single site to build point-level relationships. In this paper, we reformulate the conventional t-SNE method from the single-site mode into a secure distributed infrastructure. We present a secure multi-party scheme for joint t-SNE computation, which can minimize the risk of data leakage. Aggregated visualization can be optionally employed to hide disclosure of point-level relationships. We build a prototype system based on our method, SMAP, to support the organization, computation, and exploration of secure joint embedding. We demonstrate the effectiveness of our approach with three case studies, one of which is based on the deployment of our system in real-world applications.
RIS-GAN: Explore Residual and Illumination with Generative Adversarial Networks for Shadow Removal
Dec 24, 2019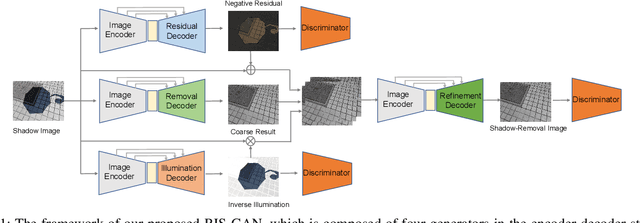
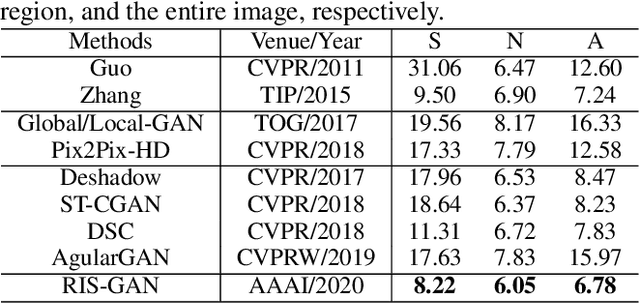

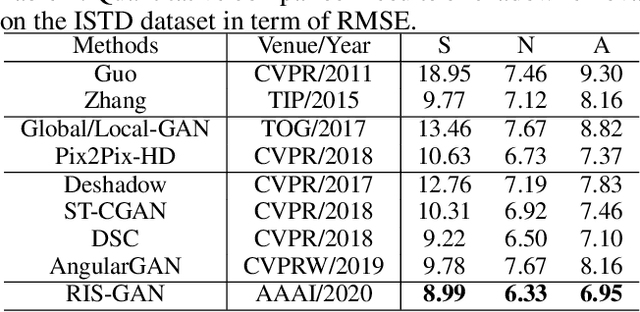
Residual images and illumination estimation have been proved very helpful in image enhancement. In this paper, we propose a general and novel framework RIS-GAN which explores residual and illumination with Generative Adversarial Networks for shadow removal. Combined with the coarse shadow-removal image, the estimated negative residual images and inverse illumination maps can be used to generate indirect shadow-removal images to refine the coarse shadow-removal result to the fine shadow-free image in a coarse-to-fine fashion. Three discriminators are designed to distinguish whether the predicted negative residual images, shadow-removal images, and the inverse illumination maps are real or fake jointly compared with the corresponding ground-truth information. To our best knowledge, we are the first one to explore residual and illumination for shadow removal. We evaluate our proposed method on two benchmark datasets, i.e., SRD and ISTD, and the extensive experiments demonstrate that our proposed method achieves the superior performance to state-of-the-arts, although we have no particular shadow-aware components designed in our generators.