 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Entropy Neural Networks for Physics-Aware Prediction
Jul 01, 2024This paper addresses the need for deep learning models to integrate well-defined constraints into their outputs, driven by their application in surrogate models, learning with limited data and partial information, and scenarios requiring flexible model behavior to incorporate non-data sample information. We introduce Bayesian Entropy Neural Networks (BENN), a framework grounded in Maximum Entropy (MaxEnt) principles, designed to impose constraints on Bayesian Neural Network (BNN) predictions. BENN is capable of constraining not only the predicted values but also their derivatives and variances, ensuring a more robust and reliable model output. To achieve simultaneous uncertainty quantification and constraint satisfaction, we employ the method of multipliers approach. This allows for the concurrent estimation of neural network parameters and the Lagrangian multipliers associated with the constraints. Our experiments, spanning diverse applications such as beam deflection modeling and microstructure generation, demonstrate the effectiveness of BENN. The results highlight significant improvements over traditional BNNs and showcase competitive performance relative to contemporary constrained deep learning methods.
Hierarchical Multi-label Classification for Fine-level Event Extraction from Aviation Accident Reports
Mar 26, 2024A large volume of accident reports is recorded in the aviation domain, which greatly values improving aviation safety. To better use those reports, we need to understand the most important events or impact factors according to the accident reports. However, the increasing number of accident reports requires large efforts from domain experts to label those reports. In order to make the labeling process more efficient, many researchers have started developing algorithms to identify the underlying events from accident reports automatically. This article argues that we can identify the events more accurately by leveraging the event taxonomy. More specifically, we consider the problem a hierarchical classification task where we first identify the coarse-level information and then predict the fine-level information. We achieve this hierarchical classification process by incorporating a novel hierarchical attention module into BERT. To further utilize the information from event taxonomy, we regularize the proposed model according to the relationship and distribution among labels. The effectiveness of our framework is evaluated with the data collected by National Transportation Safety Board (NTSB). It has been shown that fine-level prediction accuracy is highly improved, and the regularization term can be beneficial to the rare event identification problem.
Curvature Augmented Manifold Embedding and Learning
Mar 21, 2024A new dimensional reduction (DR) and data visualization method, Curvature-Augmented Manifold Embedding and Learning (CAMEL), is proposed. The key novel contribution is to formulate the DR problem as a mechanistic/physics model, where the force field among nodes (data points) is used to find an n-dimensional manifold representation of the data sets. Compared with many existing attractive-repulsive force-based methods, one unique contribution of the proposed method is to include a non-pairwise force. A new force field model is introduced and discussed, inspired by the multi-body potential in lattice-particle physics and Riemann curvature in topology. A curvature-augmented force is included in CAMEL. Following this, CAMEL formulation for unsupervised learning, supervised learning, semi-supervised learning/metric learning, and inverse learning are provided. Next, CAMEL is applied to many benchmark datasets by comparing existing models, such as tSNE, UMAP, TRIMAP, and PacMap. Both visual comparison and metrics-based evaluation are performed. 14 open literature and self-proposed metrics are employed for a comprehensive comparison. Conclusions and future work are suggested based on the current investigation. Related code and demonstration are available on https://github.com/ymlasu/CAMEL for interested readers to reproduce the results and other applications.
Machine Learning-Enhanced Aircraft Landing Scheduling under Uncertainties
Nov 27, 2023



This paper addresses aircraft delays, emphasizing their impact on safety and financial losses. To mitigate these issues, an innovative machine learning (ML)-enhanced landing scheduling methodology is proposed, aiming to improve automation and safety. Analyzing flight arrival delay scenarios reveals strong multimodal distributions and clusters in arrival flight time durations. A multi-stage conditional ML predictor enhances separation time prediction based on flight events. ML predictions are then integrated as safety constraints in a time-constrained traveling salesman problem formulation, solved using mixed-integer linear programming (MILP). Historical flight recordings and model predictions address uncertainties between successive flights, ensuring reliability. The proposed method is validated using real-world data from the Atlanta Air Route Traffic Control Center (ARTCC ZTL). Case studies demonstrate an average 17.2% reduction in total landing time compared to the First-Come-First-Served (FCFS) rule. Unlike FCFS, the proposed methodology considers uncertainties, instilling confidence in scheduling. The study concludes with remarks and outlines future research directions.
Air Traffic Controller Workload Level Prediction using Conformalized Dynamical Graph Learning
Jul 22, 2023
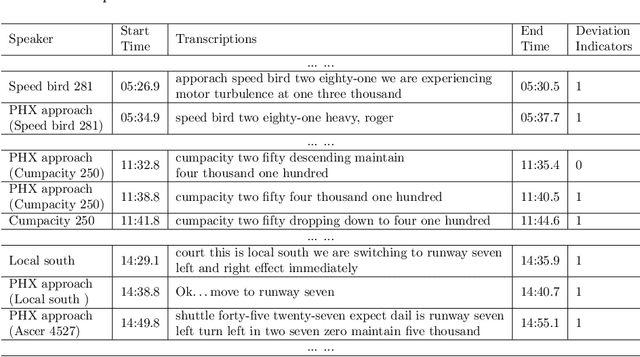
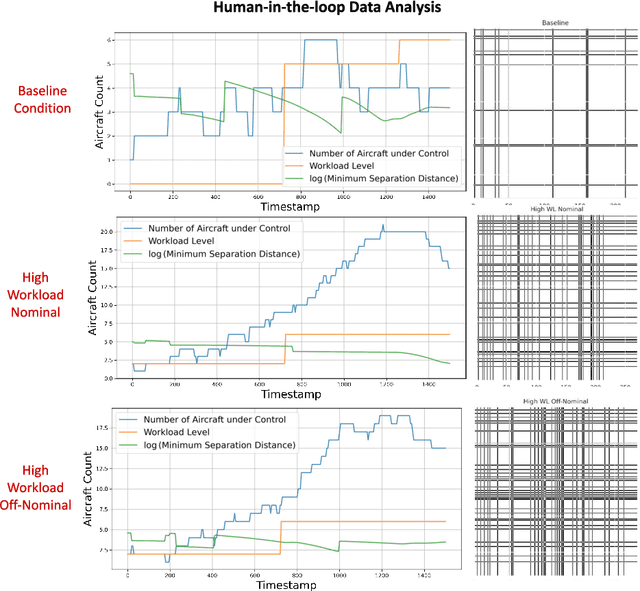

Air traffic control (ATC) is a safety-critical service system that demands constant attention from ground air traffic controllers (ATCos) to maintain daily aviation operations. The workload of the ATCos can have negative effects on operational safety and airspace usage. To avoid overloading and ensure an acceptable workload level for the ATCos, it is important to predict the ATCos' workload accurately for mitigation actions. In this paper, we first perform a review of research on ATCo workload, mostly from the air traffic perspective. Then, we briefly introduce the setup of the human-in-the-loop (HITL) simulations with retired ATCos, where the air traffic data and workload labels are obtained. The simulations are conducted under three Phoenix approach scenarios while the human ATCos are requested to self-evaluate their workload ratings (i.e., low-1 to high-7). Preliminary data analysis is conducted. Next, we propose a graph-based deep-learning framework with conformal prediction to identify the ATCo workload levels. The number of aircraft under the controller's control varies both spatially and temporally, resulting in dynamically evolving graphs. The experiment results suggest that (a) besides the traffic density feature, the traffic conflict feature contributes to the workload prediction capabilities (i.e., minimum horizontal/vertical separation distance); (b) directly learning from the spatiotemporal graph layout of airspace with graph neural network can achieve higher prediction accuracy, compare to hand-crafted traffic complexity features; (c) conformal prediction is a valuable tool to further boost model prediction accuracy, resulting a range of predicted workload labels. The code used is available at \href{https://github.com/ymlasu/para-atm-collection/blob/master/air-traffic-prediction/ATC-Workload-Prediction/}{$\mathsf{Link}$}.
Reinforcement Learning With Reward Machines in Stochastic Games
May 27, 2023We investigate multi-agent reinforcement learning for stochastic games with complex tasks, where the reward functions are non-Markovian. We utilize reward machines to incorporate high-level knowledge of complex tasks. We develop an algorithm called Q-learning with reward machines for stochastic games (QRM-SG), to learn the best-response strategy at Nash equilibrium for each agent. In QRM-SG, we define the Q-function at a Nash equilibrium in augmented state space. The augmented state space integrates the state of the stochastic game and the state of reward machines. Each agent learns the Q-functions of all agents in the system. We prove that Q-functions learned in QRM-SG converge to the Q-functions at a Nash equilibrium if the stage game at each time step during learning has a global optimum point or a saddle point, and the agents update Q-functions based on the best-response strategy at this point. We use the Lemke-Howson method to derive the best-response strategy given current Q-functions. The three case studies show that QRM-SG can learn the best-response strategies effectively. QRM-SG learns the best-response strategies after around 7500 episodes in Case Study I, 1000 episodes in Case Study II, and 1500 episodes in Case Study III, while baseline methods such as Nash Q-learning and MADDPG fail to converge to the Nash equilibrium in all three case studies.
ArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4
May 12, 2023In recent years, large language models (LLMs) have made significant progress in natural language processing (NLP), with models like ChatGPT and GPT-4 achieving impressive capabilities in various linguistic tasks. However, training models on such a large scale is challenging, and finding datasets that match the model's scale is often difficult. Fine-tuning and training models with fewer parameters using novel methods have emerged as promising approaches to overcome these challenges. One such model is MiniGPT-4, which achieves comparable vision-language understanding to GPT-4 by leveraging novel pre-training models and innovative training strategies. However, the model still faces some challenges in image understanding, particularly in artistic pictures. A novel multimodal model called ArtGPT-4 has been proposed to address these limitations. ArtGPT-4 was trained on image-text pairs using a Tesla A100 device in just 2 hours, using only about 200 GB of data. The model can depict images with an artistic flair and generate visual code, including aesthetically pleasing HTML/CSS web pages. Furthermore, the article proposes novel benchmarks for evaluating the performance of vision-language models. In the subsequent evaluation methods, ArtGPT-4 scored more than 1 point higher than the current \textbf{state-of-the-art} model and was only 0.25 points lower than artists on a 6-point scale. Our code and pre-trained model are available at \url{https://huggingface.co/Tyrannosaurus/ArtGPT-4}.
CAMEL: Curvature-Augmented Manifold Embedding and Learning
Mar 05, 2023A novel method, named Curvature-Augmented Manifold Embedding and Learning (CAMEL), is proposed for high dimensional data classification, dimension reduction, and visualization. CAMEL utilizes a topology metric defined on the Riemannian manifold, and a unique Riemannian metric for both distance and curvature to enhance its expressibility. The method also employs a smooth partition of unity operator on the Riemannian manifold to convert localized orthogonal projection to global embedding, which captures both the overall topological structure and local similarity simultaneously. The local orthogonal vectors provide a physical interpretation of the significant characteristics of clusters. Therefore, CAMEL not only provides a low-dimensional embedding but also interprets the physics behind this embedding. CAMEL has been evaluated on various benchmark datasets and has shown to outperform state-of-the-art methods, especially for high-dimensional datasets. The method's distinct benefits are its high expressibility, interpretability, and scalability. The paper provides a detailed discussion on Riemannian distance and curvature metrics, physical interpretability, hyperparameter effect, manifold stability, and computational efficiency for a holistic understanding of CAMEL. Finally, the paper presents the limitations and future work of CAMEL along with key conclusions.
Hulk: Graph Neural Networks for Optimizing Regionally Distributed Computing Systems
Feb 27, 2023Large deep learning models have shown great potential for delivering exceptional results in various applications. However, the training process can be incredibly challenging due to the models' vast parameter sizes, often consisting of hundreds of billions of parameters. Common distributed training methods, such as data parallelism, tensor parallelism, and pipeline parallelism, demand significant data communication throughout the process, leading to prolonged wait times for some machines in physically distant distributed systems. To address this issue, we propose a novel solution called Hulk, which utilizes a modified graph neural network to optimize distributed computing systems. Hulk not only optimizes data communication efficiency between different countries or even different regions within the same city, but also provides optimal distributed deployment of models in parallel. For example, it can place certain layers on a machine in a specific region or pass specific parameters of a model to a machine in a particular location. By using Hulk in experiments, we were able to improve the time efficiency of training large deep learning models on distributed systems by more than 20\%. Our open source collection of unlabeled data:https://github.com/DLYuanGod/Hulk.
B-BACN: Bayesian Boundary-Aware Convolutional Network for Crack Characterization
Feb 17, 2023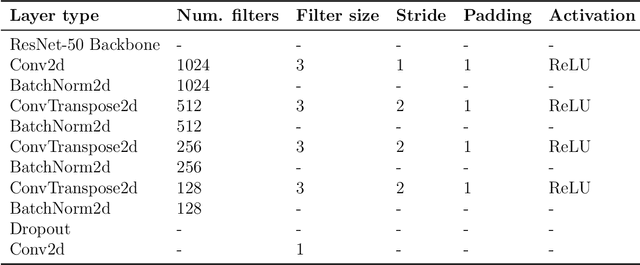
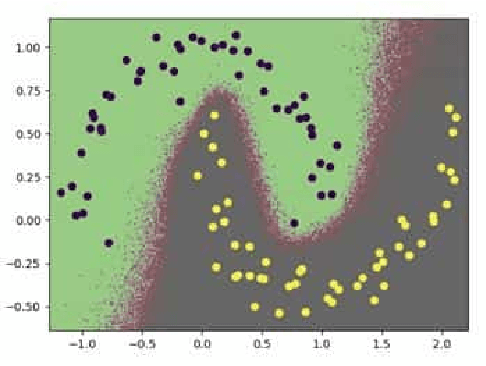
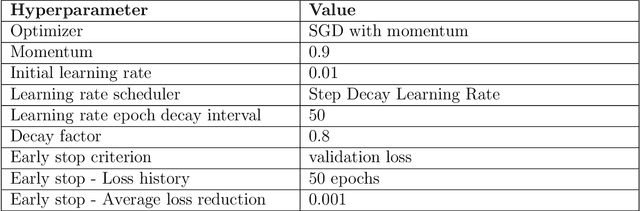
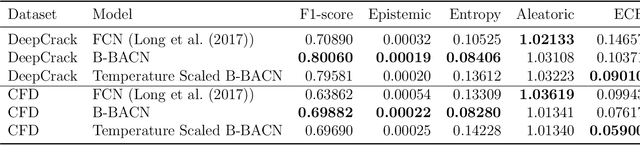
The accurate detection of crack boundaries is crucial for various purposes, such as condition monitoring, prognostics, and maintenance scheduling. To address this issue, we introduce a Bayesian Boundary-Aware Convolutional Network (B-BACN) that emphasizes the significance of both uncertainty quantification and boundary refinement to generate precise and reliable defect boundary detections. Our inspection model employs a multi-task learning approach, where we use Monte Carlo Dropout to learn the epistemic uncertainty and a Gaussian sampling function to predict each sample's aleatoric uncertainty. Moreover, we include a boundary refinement loss to B-BACN to enhance the determination of defect boundaries. The experimental results illustrate the effectiveness of our proposed approach in identifying crack boundaries with high accuracy, minimizing misclassification rate, and improving model calibration capabilities.