 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-Enhanced Aircraft Landing Scheduling under Uncertainties
Nov 27, 2023



This paper addresses aircraft delays, emphasizing their impact on safety and financial losses. To mitigate these issues, an innovative machine learning (ML)-enhanced landing scheduling methodology is proposed, aiming to improve automation and safety. Analyzing flight arrival delay scenarios reveals strong multimodal distributions and clusters in arrival flight time durations. A multi-stage conditional ML predictor enhances separation time prediction based on flight events. ML predictions are then integrated as safety constraints in a time-constrained traveling salesman problem formulation, solved using mixed-integer linear programming (MILP). Historical flight recordings and model predictions address uncertainties between successive flights, ensuring reliability. The proposed method is validated using real-world data from the Atlanta Air Route Traffic Control Center (ARTCC ZTL). Case studies demonstrate an average 17.2% reduction in total landing time compared to the First-Come-First-Served (FCFS) rule. Unlike FCFS, the proposed methodology considers uncertainties, instilling confidence in scheduling. The study concludes with remarks and outlines future research directions.
Air Traffic Controller Workload Level Prediction using Conformalized Dynamical Graph Learning
Jul 22, 2023
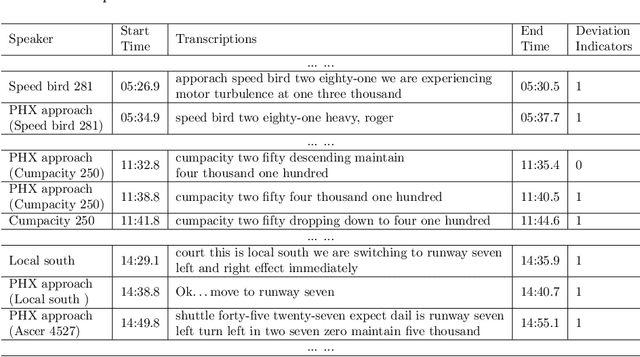
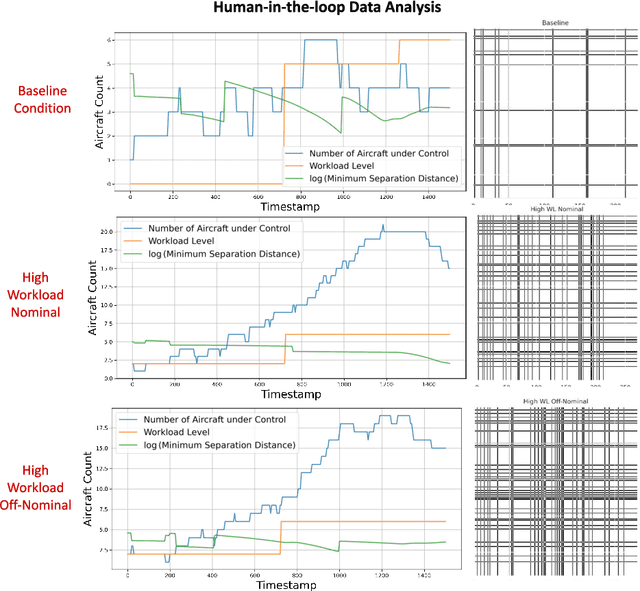

Air traffic control (ATC) is a safety-critical service system that demands constant attention from ground air traffic controllers (ATCos) to maintain daily aviation operations. The workload of the ATCos can have negative effects on operational safety and airspace usage. To avoid overloading and ensure an acceptable workload level for the ATCos, it is important to predict the ATCos' workload accurately for mitigation actions. In this paper, we first perform a review of research on ATCo workload, mostly from the air traffic perspective. Then, we briefly introduce the setup of the human-in-the-loop (HITL) simulations with retired ATCos, where the air traffic data and workload labels are obtained. The simulations are conducted under three Phoenix approach scenarios while the human ATCos are requested to self-evaluate their workload ratings (i.e., low-1 to high-7). Preliminary data analysis is conducted. Next, we propose a graph-based deep-learning framework with conformal prediction to identify the ATCo workload levels. The number of aircraft under the controller's control varies both spatially and temporally, resulting in dynamically evolving graphs. The experiment results suggest that (a) besides the traffic density feature, the traffic conflict feature contributes to the workload prediction capabilities (i.e., minimum horizontal/vertical separation distance); (b) directly learning from the spatiotemporal graph layout of airspace with graph neural network can achieve higher prediction accuracy, compare to hand-crafted traffic complexity features; (c) conformal prediction is a valuable tool to further boost model prediction accuracy, resulting a range of predicted workload labels. The code used is available at \href{https://github.com/ymlasu/para-atm-collection/blob/master/air-traffic-prediction/ATC-Workload-Prediction/}{$\mathsf{Link}$}.
Reinforcement Learning With Reward Machines in Stochastic Games
May 27, 2023We investigate multi-agent reinforcement learning for stochastic games with complex tasks, where the reward functions are non-Markovian. We utilize reward machines to incorporate high-level knowledge of complex tasks. We develop an algorithm called Q-learning with reward machines for stochastic games (QRM-SG), to learn the best-response strategy at Nash equilibrium for each agent. In QRM-SG, we define the Q-function at a Nash equilibrium in augmented state space. The augmented state space integrates the state of the stochastic game and the state of reward machines. Each agent learns the Q-functions of all agents in the system. We prove that Q-functions learned in QRM-SG converge to the Q-functions at a Nash equilibrium if the stage game at each time step during learning has a global optimum point or a saddle point, and the agents update Q-functions based on the best-response strategy at this point. We use the Lemke-Howson method to derive the best-response strategy given current Q-functions. The three case studies show that QRM-SG can learn the best-response strategies effectively. QRM-SG learns the best-response strategies after around 7500 episodes in Case Study I, 1000 episodes in Case Study II, and 1500 episodes in Case Study III, while baseline methods such as Nash Q-learning and MADDPG fail to converge to the Nash equilibrium in all three case studies.
Obstacle Avoidance for UAS in Continuous Action Space Using Deep Reinforcement Learning
Nov 13, 2021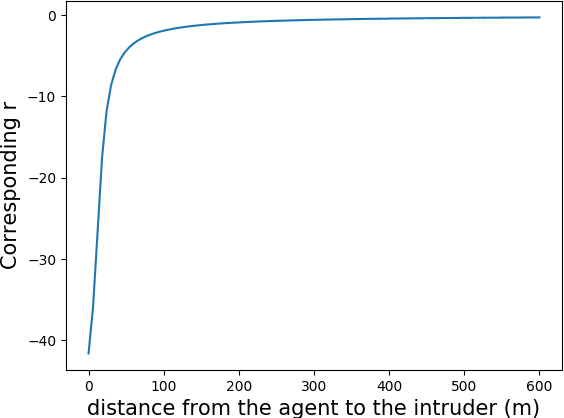

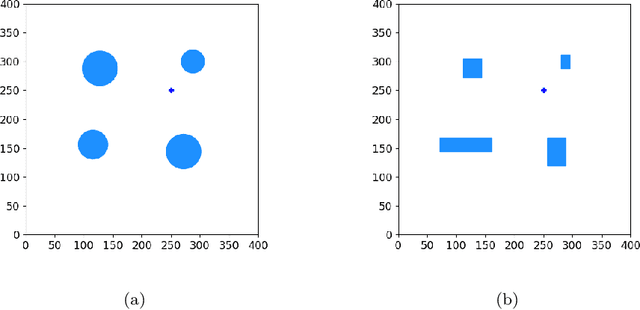

Obstacle avoidance for small unmanned aircraft is vital for the safety of future urban air mobility (UAM) and Unmanned Aircraft System (UAS) Traffic Management (UTM). There are many techniques for real-time robust drone guidance, but many of them solve in discretized airspace and control, which would require an additional path smoothing step to provide flexible commands for UAS. To provide a safe and efficient computational guidance of operations for unmanned aircraft, we explore the use of a deep reinforcement learning algorithm based on Proximal Policy Optimization (PPO) to guide autonomous UAS to their destinations while avoiding obstacles through continuous control. The proposed scenario state representation and reward function can map the continuous state space to continuous control for both heading angle and speed. To verify the performance of the proposed learning framework, we conducted numerical experiments with static and moving obstacles. Uncertainties associated with the environments and safety operation bounds are investigated in detail. Results show that the proposed model can provide accurate and robust guidance and resolve conflict with a success rate of over 99%.
Decentralized Graph-Based Multi-Agent Reinforcement Learning Using Reward Machines
Sep 30, 2021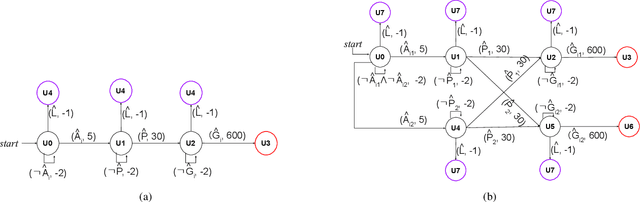
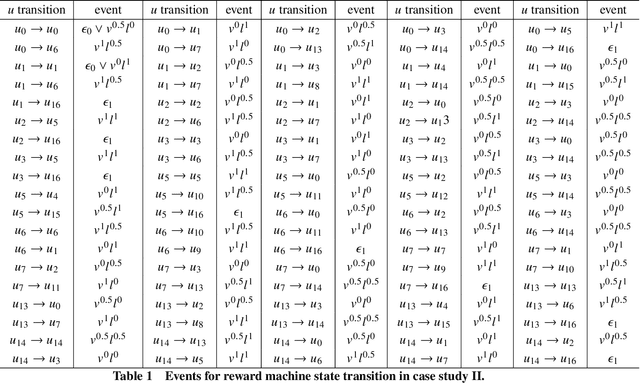

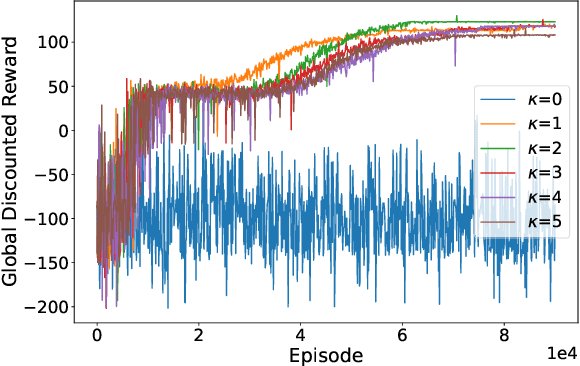
In multi-agent reinforcement learning (MARL), it is challenging for a collection of agents to learn complex temporally extended tasks. The difficulties lie in computational complexity and how to learn the high-level ideas behind reward functions. We study the graph-based Markov Decision Process (MDP) where the dynamics of neighboring agents are coupled. We use a reward machine (RM) to encode each agent's task and expose reward function internal structures. RM has the capacity to describe high-level knowledge and encode non-Markovian reward functions. We propose a decentralized learning algorithm to tackle computational complexity, called decentralized graph-based reinforcement learning using reward machines (DGRM), that equips each agent with a localized policy, allowing agents to make decisions independently, based on the information available to the agents. DGRM uses the actor-critic structure, and we introduce the tabular Q-function for discrete state problems. We show that the dependency of Q-function on other agents decreases exponentially as the distance between them increases. Furthermore, the complexity of DGRM is related to the local information size of the largest $\kappa$-hop neighborhood, and DGRM can find an $O(\rho^{\kappa+1})$-approximation of a stationary point of the objective function. To further improve efficiency, we also propose the deep DGRM algorithm, using deep neural networks to approximate the Q-function and policy function to solve large-scale or continuous state problems. The effectiveness of the proposed DGRM algorithm is evaluated by two case studies, UAV package delivery and COVID-19 pandemic mitigation. Experimental results show that local information is sufficient for DGRM and agents can accomplish complex tasks with the help of RM. DGRM improves the global accumulated reward by 119% compared to the baseline in the case of COVID-19 pandemic mitigation.
Evaluating the Robustness of Bayesian Neural Networks Against Different Types of Attacks
Jun 17, 2021

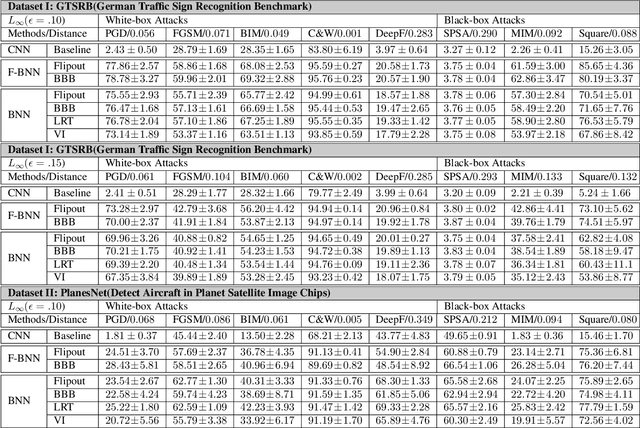

To evaluate the robustness gain of Bayesian neural networks on image classification tasks, we perform input perturbations, and adversarial attacks to the state-of-the-art Bayesian neural networks, with a benchmark CNN model as reference. The attacks are selected to simulate signal interference and cyberattacks towards CNN-based machine learning systems. The result shows that a Bayesian neural network achieves significantly higher robustness against adversarial attacks generated against a deterministic neural network model, without adversarial training. The Bayesian posterior can act as the safety precursor of ongoing malicious activities. Furthermore, we show that the stochastic classifier after the deterministic CNN extractor has sufficient robustness enhancement rather than a stochastic feature extractor before the stochastic classifier. This advises on utilizing stochastic layers in building decision-making pipelines within a safety-critical domain.