 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObstacle Avoidance for UAS in Continuous Action Space Using Deep Reinforcement Learning
Nov 13, 2021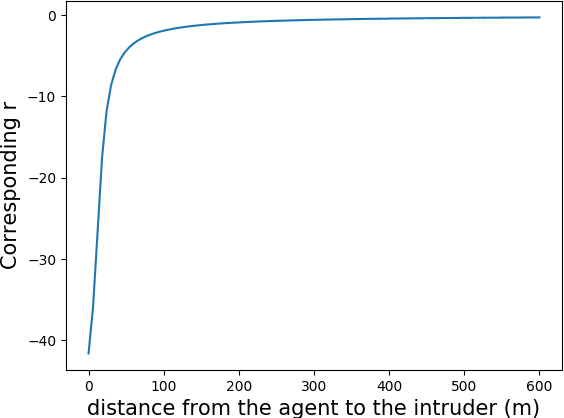


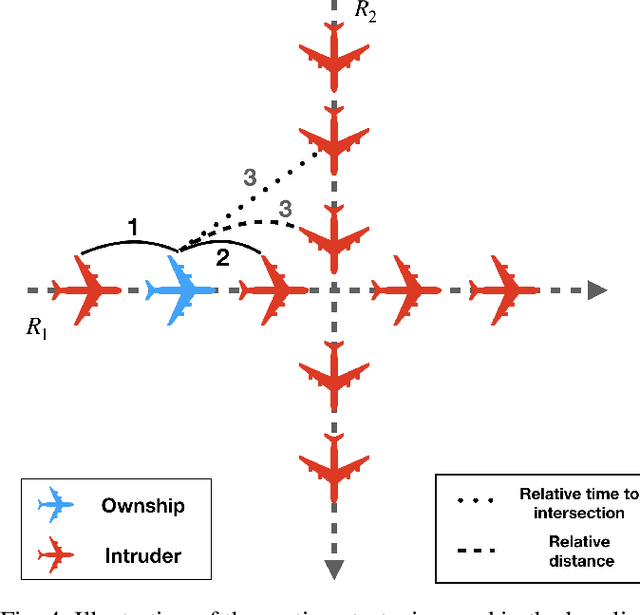
Obstacle avoidance for small unmanned aircraft is vital for the safety of future urban air mobility (UAM) and Unmanned Aircraft System (UAS) Traffic Management (UTM). There are many techniques for real-time robust drone guidance, but many of them solve in discretized airspace and control, which would require an additional path smoothing step to provide flexible commands for UAS. To provide a safe and efficient computational guidance of operations for unmanned aircraft, we explore the use of a deep reinforcement learning algorithm based on Proximal Policy Optimization (PPO) to guide autonomous UAS to their destinations while avoiding obstacles through continuous control. The proposed scenario state representation and reward function can map the continuous state space to continuous control for both heading angle and speed. To verify the performance of the proposed learning framework, we conducted numerical experiments with static and moving obstacles. Uncertainties associated with the environments and safety operation bounds are investigated in detail. Results show that the proposed model can provide accurate and robust guidance and resolve conflict with a success rate of over 99%.
Continuous Control for Searching and Planning with a Learned Model
Jun 22, 2020
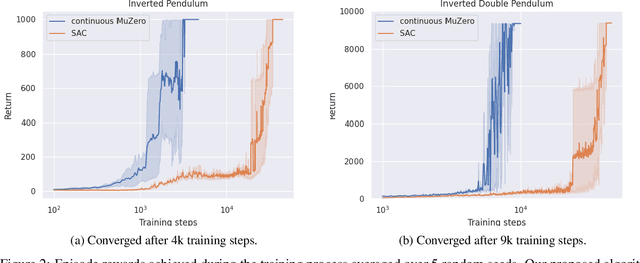
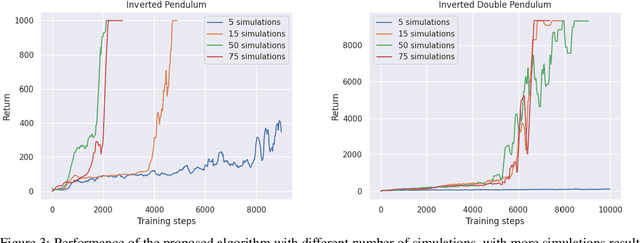
Decision-making agents with planning capabilities have achieved huge success in the challenging domain like Chess, Shogi, and Go. In an effort to generalize the planning ability to the more general tasks where the environment dynamics are not available to the agent, researchers proposed the MuZero algorithm that can learn the dynamical model through the interactions with the environment. In this paper, we provide a way and the necessary theoretical results to extend the MuZero algorithm to more generalized environments with continuous action space. Through numerical results on two relatively low-dimensional MuJoCo environments, we show the proposed algorithm outperforms the soft actor-critic (SAC) algorithm, a state-of-the-art model-free deep reinforcement learning algorithm.
A Deep Multi-Agent Reinforcement Learning Approach to Autonomous Separation Assurance
Mar 17, 2020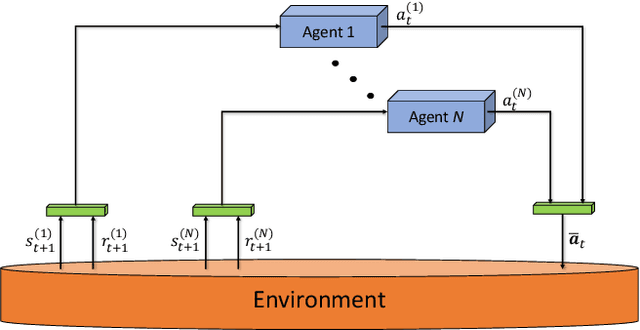
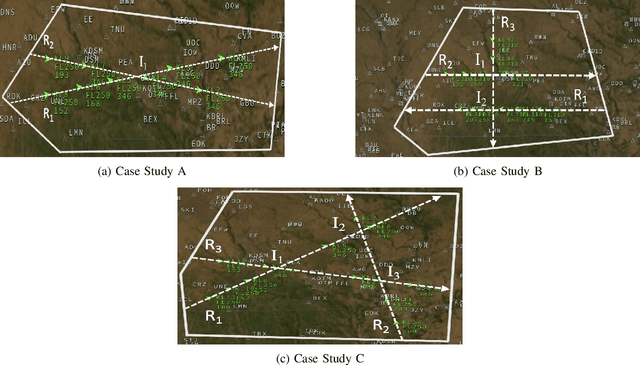
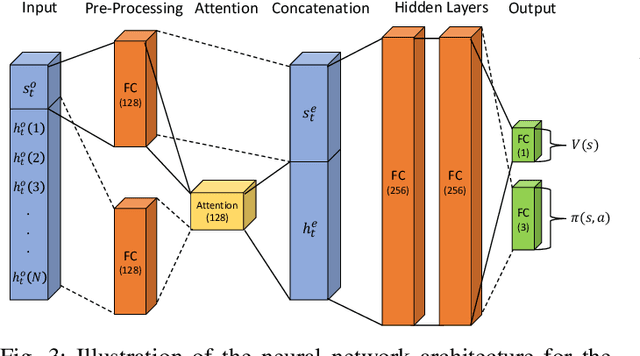
A novel deep multi-agent reinforcement learning framework is proposed to identify and resolve conflicts among a variable number of aircraft in a high-density, stochastic, and dynamic sector in en route airspace. Currently the sector capacity is limited by human air traffic controller's cognitive limitation. In order to scale up to a high-density airspace, in this work we investigate the feasibility of a new concept (autonomous separation assurance) and a new approach (multi-agent reinforcement learning) to push the sector capacity above human cognitive limitation. We propose the concept of using distributed vehicle autonomy to ensure separation, instead of a centralized sector air traffic controller. Our proposed framework utilizes an actor-critic model, Proximal Policy Optimization (PPO) that we customize to incorporate an attention network. By using the attention network, we are able to encode the information from a variable number of intruder aircraft into a fixed length vector and allow the agents to learn which intruder aircraft's information is critical to achieve the optimal performance. This allows the agents to have access to variable aircraft information in the sector in a scalable, efficient approach to achieve high traffic throughput under uncertainty. The agents are trained using a centralized learning, decentralized execution scheme where one neural network is learned and shared by all agents in the environment. To validate the proposed framework, we designed three challenging case studies in the BlueSky air traffic control environment. Numerical results show the proposed framework significantly reduces the offline training time without sacrificing performance.
Prioritized Sequence Experience Replay
May 25, 2019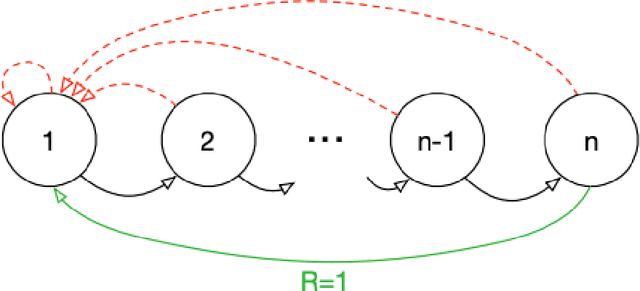

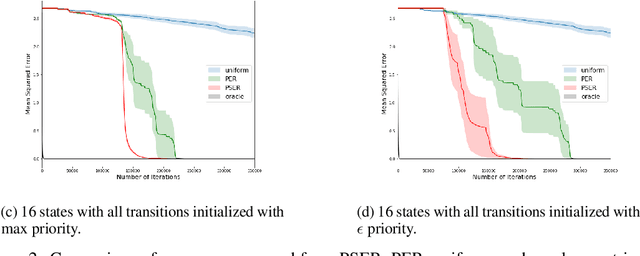
Experience replay is widely used in deep reinforcement learning algorithms and allows agents to remember and learn from experiences from the past. In an effort to learn more efficiently, researchers proposed prioritized experience replay (PER) which samples important transitions more frequently. In this paper, we propose Prioritized Sequence Experience Replay (PSER) a framework for prioritizing sequences of experience in an attempt to both learn more efficiently and to obtain better performance. We compare performance of uniform, PER and PSER sampling techniques in DQN on the Atari 2600 benchmark and show DQN with PSER substantially outperforms PER and uniform sampling.
Fast Online Exact Solutions for Deterministic MDPs with Sparse Rewards
May 17, 2018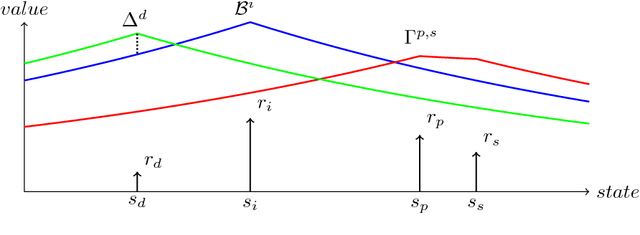
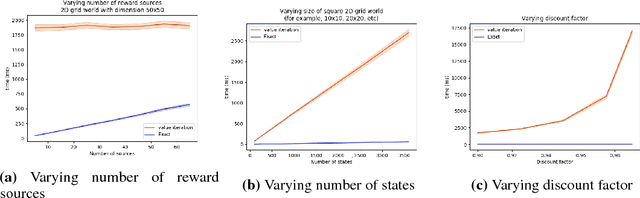
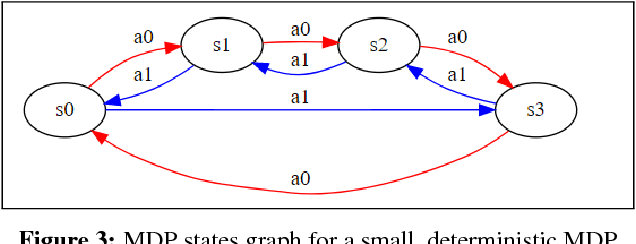
Markov Decision Processes (MDPs) are a mathematical framework for modeling sequential decision making under uncertainty. The classical approaches for solving MDPs are well known and have been widely studied, some of which rely on approximation techniques to solve MDPs with large state space and/or action space. However, most of these classical solution approaches and their approximation techniques still take much computation time to converge and usually must be re-computed if the reward function is changed. This paper introduces a novel alternative approach for exactly and efficiently solving deterministic, continuous MDPs with sparse reward sources. When the environment is such that the "distance" between states can be determined in constant time, e.g. grid world, our algorithm offers $O( |R|^2 \times |A|^2 \times |S|)$, where $|R|$ is the number of reward sources, $|A|$ is the number of actions, and $|S|$ is the number of states. Memory complexity for the algorithm is $O( |S| + |R| \times |A|)$. This new approach opens new avenues for boosting computational performance for certain classes of MDPs and is of tremendous value for MDP applications such as robotics and unmanned systems. This paper describes the algorithm and presents numerical experiment results to demonstrate its powerful computational performance. We also provide rigorous mathematical description of the approach.