 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Online Exact Solutions for Deterministic MDPs with Sparse Rewards
Paper and Code
May 17, 2018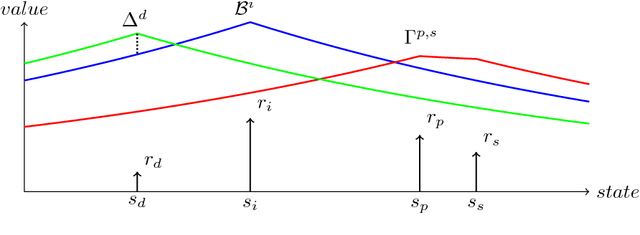
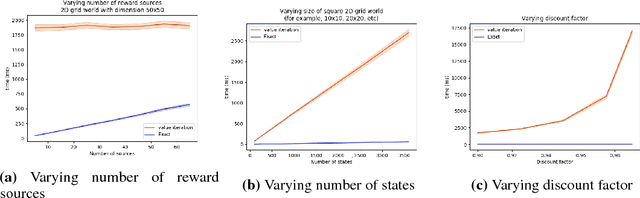
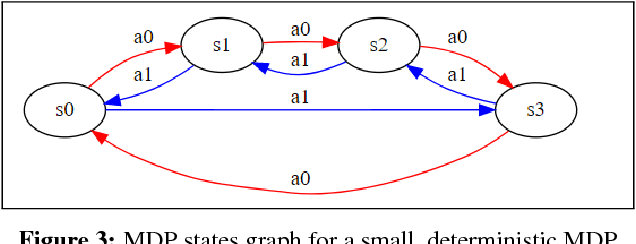
Markov Decision Processes (MDPs) are a mathematical framework for modeling sequential decision making under uncertainty. The classical approaches for solving MDPs are well known and have been widely studied, some of which rely on approximation techniques to solve MDPs with large state space and/or action space. However, most of these classical solution approaches and their approximation techniques still take much computation time to converge and usually must be re-computed if the reward function is changed. This paper introduces a novel alternative approach for exactly and efficiently solving deterministic, continuous MDPs with sparse reward sources. When the environment is such that the "distance" between states can be determined in constant time, e.g. grid world, our algorithm offers $O( |R|^2 \times |A|^2 \times |S|)$, where $|R|$ is the number of reward sources, $|A|$ is the number of actions, and $|S|$ is the number of states. Memory complexity for the algorithm is $O( |S| + |R| \times |A|)$. This new approach opens new avenues for boosting computational performance for certain classes of MDPs and is of tremendous value for MDP applications such as robotics and unmanned systems. This paper describes the algorithm and presents numerical experiment results to demonstrate its powerful computational performance. We also provide rigorous mathematical description of the approach.