 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Conflict Management for UAM with Strategic Demand Capacity Balancing and Learning-based Tactical Deconfliction
May 17, 2023



Urban air mobility (UAM) has the potential to revolutionize our daily transportation, offering rapid and efficient deliveries of passengers and cargo between dedicated locations within and around the urban environment. Before the commercialization and adoption of this emerging transportation mode, however, aviation safety must be guaranteed, i.e., all the aircraft have to be safely separated by strategic and tactical deconfliction. Reinforcement learning has demonstrated effectiveness in the tactical deconfliction of en route commercial air traffic in simulation. However, its performance is found to be dependent on the traffic density. In this project, we propose a novel framework that combines demand capacity balancing (DCB) for strategic conflict management and reinforcement learning for tactical separation. By using DCB to precondition traffic to proper density levels, we show that reinforcement learning can achieve much better performance for tactical safety separation. Our results also indicate that this DCB preconditioning can allow target levels of safety to be met that are otherwise impossible. In addition, combining strategic DCB with reinforcement learning for tactical separation can meet these safety levels while achieving greater operational efficiency than alternative solutions.
Reward Function Optimization of a Deep Reinforcement Learning Collision Avoidance System
Dec 01, 2022The proliferation of unmanned aircraft systems (UAS) has caused airspace regulation authorities to examine the interoperability of these aircraft with collision avoidance systems initially designed for large transport category aircraft. Limitations in the currently mandated TCAS led the Federal Aviation Administration to commission the development of a new solution, the Airborne Collision Avoidance System X (ACAS X), designed to enable a collision avoidance capability for multiple aircraft platforms, including UAS. While prior research explored using deep reinforcement learning algorithms (DRL) for collision avoidance, DRL did not perform as well as existing solutions. This work explores the benefits of using a DRL collision avoidance system whose parameters are tuned using a surrogate optimizer. We show the use of a surrogate optimizer leads to DRL approach that can increase safety and operational viability and support future capability development for UAS collision avoidance.
AAM-Gym: Artificial Intelligence Testbed for Advanced Air Mobility
Jun 09, 2022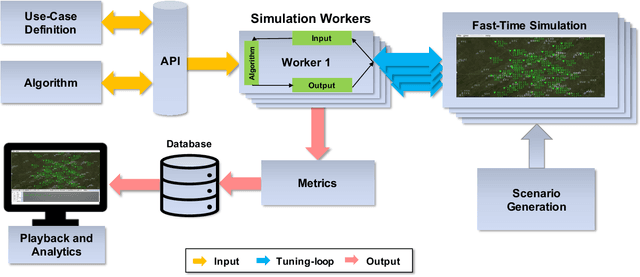
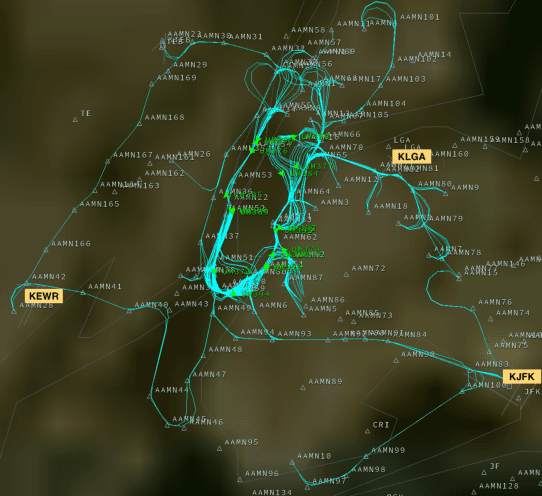
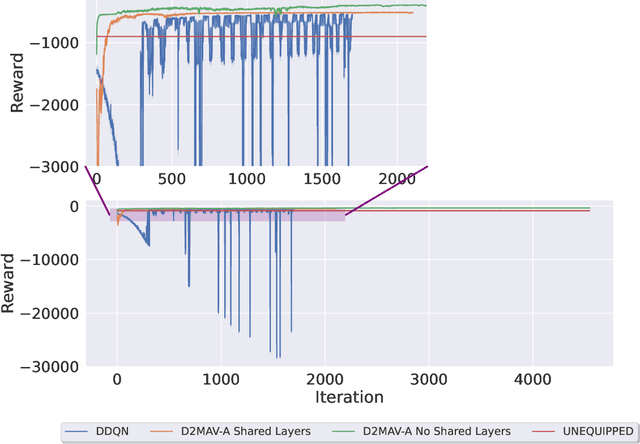
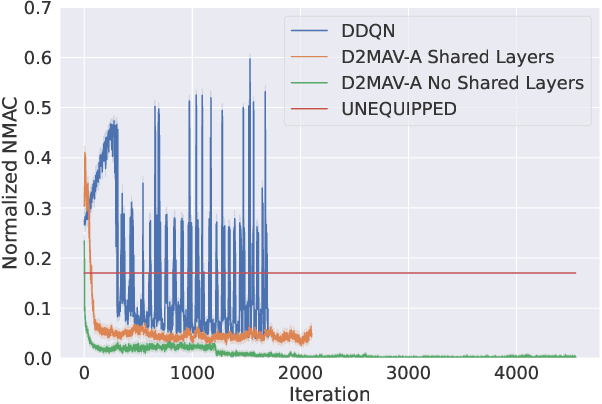
We introduce AAM-Gym, a research and development testbed for Advanced Air Mobility (AAM). AAM has the potential to revolutionize travel by reducing ground traffic and emissions by leveraging new types of aircraft such as electric vertical take-off and landing (eVTOL) aircraft and new advanced artificial intelligence (AI) algorithms. Validation of AI algorithms require representative AAM scenarios, as well as a fast time simulation testbed to evaluate their performance. Until now, there has been no such testbed available for AAM to enable a common research platform for individuals in government, industry, or academia. MIT Lincoln Laboratory has developed AAM-Gym to address this gap by providing an ecosystem to develop, train, and validate new and established AI algorithms across a wide variety of AAM use-cases. In this paper, we use AAM-Gym to study the performance of two reinforcement learning algorithms on an AAM use-case, separation assurance in AAM corridors. The performance of the two algorithms is demonstrated based on a series of metrics provided by AAM-Gym, showing the testbed's utility to AAM research.
Collision Risk and Operational Impact of Speed Change Advisories as Aircraft Collision Avoidance Maneuvers
Apr 29, 2022
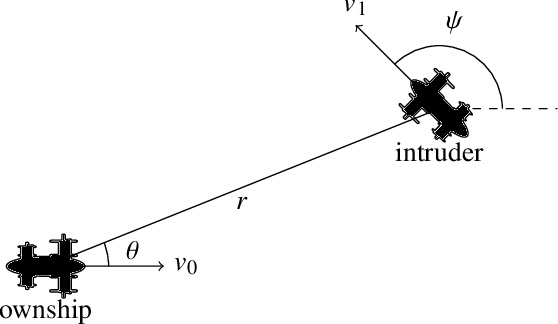

Aircraft collision avoidance systems have long been a key factor in keeping our airspace safe. Over the past decade, the FAA has supported the development of a new family of collision avoidance systems called the Airborne Collision Avoidance System X (ACAS X), which model the collision avoidance problem as a Markov decision process (MDP). Variants of ACAS X have been created for both manned (ACAS Xa) and unmanned aircraft (ACAS Xu and ACAS sXu). The variants primarily differ in the types of collision avoidance maneuvers they issue. For example, ACAS Xa issues vertical collision avoidance advisories, while ACAS Xu and ACAS sXu allow for horizontal advisories due to reduced aircraft performance capabilities. Currently, a new variant of ACAS X, called ACAS Xr, is being developed to provide collision avoidance capability to rotorcraft and Advanced Air Mobility (AAM) vehicles. Due to the desire to minimize deviation from the prescribed flight path of these aircraft, speed adjustments have been proposed as a potential collision avoidance maneuver for aircraft using ACAS Xr. In this work, we investigate the effect of speed change advisories on the safety and operational efficiency of collision avoidance systems. We develop an MDP-based collision avoidance logic that issues speed advisories and compare its performance to that of horizontal and vertical logics through Monte Carlo simulation on existing airspace encounter models. Our results show that while speed advisories are able to reduce collision risk, they are neither as safe nor as efficient as their horizontal and vertical counterparts.
Safety Enhancement for Deep Reinforcement Learning in Autonomous Separation Assurance
May 05, 2021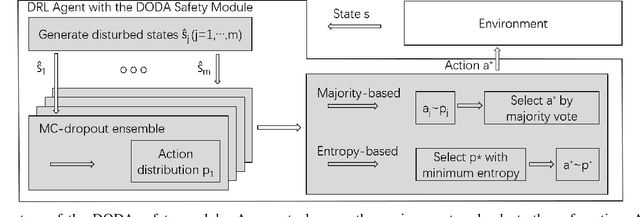

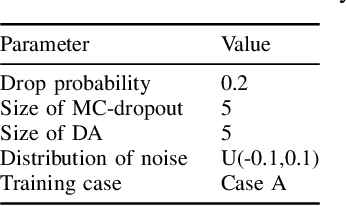
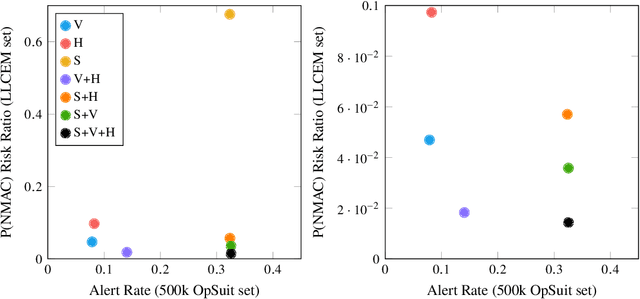
The separation assurance task will be extremely challenging for air traffic controllers in a complex and high density airspace environment. Deep reinforcement learning (DRL) was used to develop an autonomous separation assurance framework in our previous work where the learned model advised speed maneuvers. In order to improve the safety of this model in unseen environments with uncertainties, in this work we propose a safety module for DRL in autonomous separation assurance applications. The proposed module directly addresses both model uncertainty and state uncertainty to improve safety. Our safety module consists of two sub-modules: (1) the state safety sub-module is based on the execution-time data augmentation method to introduce state disturbances in the model input state; (2) the model safety sub-module is a Monte-Carlo dropout extension that learns the posterior distribution of the DRL model policy. We demonstrate the effectiveness of the two sub-modules in an open-source air traffic simulator with challenging environment settings. Through extensive numerical experiments, our results show that the proposed sub-safety modules help the DRL agent significantly improve its safety performance in an autonomous separation assurance task.
A Deep Multi-Agent Reinforcement Learning Approach to Autonomous Separation Assurance
Mar 17, 2020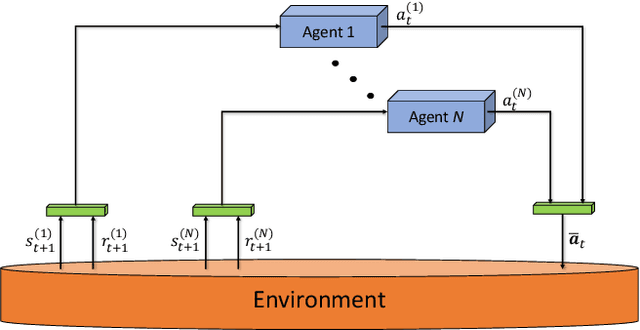
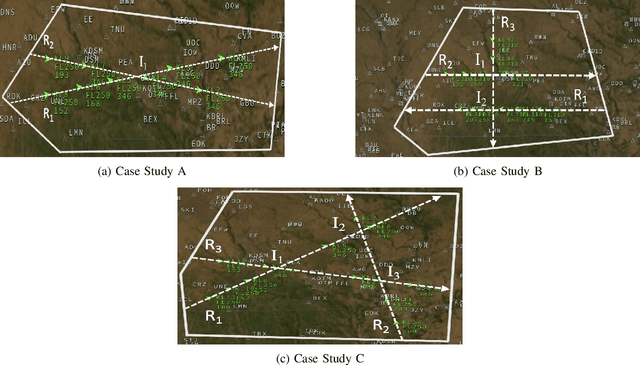
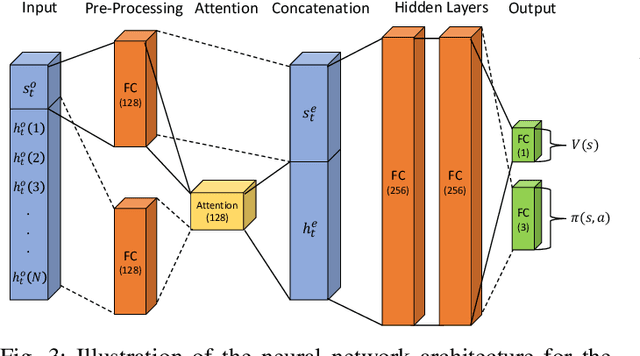
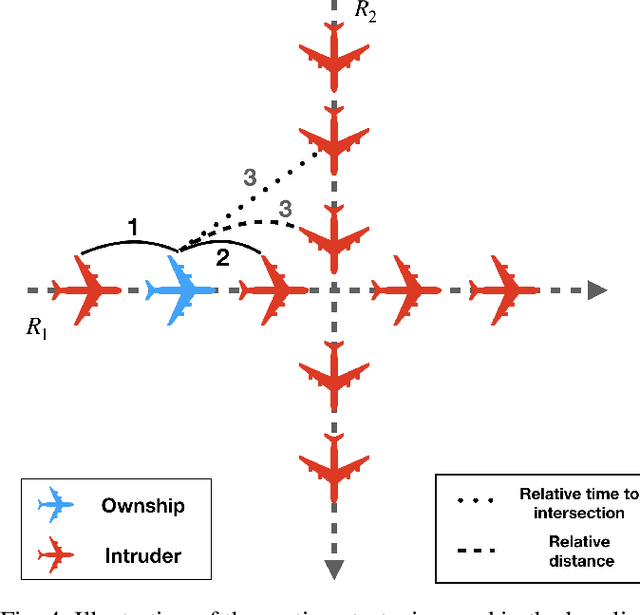
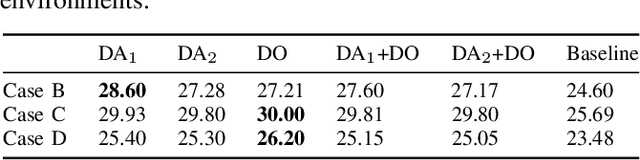
A novel deep multi-agent reinforcement learning framework is proposed to identify and resolve conflicts among a variable number of aircraft in a high-density, stochastic, and dynamic sector in en route airspace. Currently the sector capacity is limited by human air traffic controller's cognitive limitation. In order to scale up to a high-density airspace, in this work we investigate the feasibility of a new concept (autonomous separation assurance) and a new approach (multi-agent reinforcement learning) to push the sector capacity above human cognitive limitation. We propose the concept of using distributed vehicle autonomy to ensure separation, instead of a centralized sector air traffic controller. Our proposed framework utilizes an actor-critic model, Proximal Policy Optimization (PPO) that we customize to incorporate an attention network. By using the attention network, we are able to encode the information from a variable number of intruder aircraft into a fixed length vector and allow the agents to learn which intruder aircraft's information is critical to achieve the optimal performance. This allows the agents to have access to variable aircraft information in the sector in a scalable, efficient approach to achieve high traffic throughput under uncertainty. The agents are trained using a centralized learning, decentralized execution scheme where one neural network is learned and shared by all agents in the environment. To validate the proposed framework, we designed three challenging case studies in the BlueSky air traffic control environment. Numerical results show the proposed framework significantly reduces the offline training time without sacrificing performance.
Prioritized Sequence Experience Replay
May 25, 2019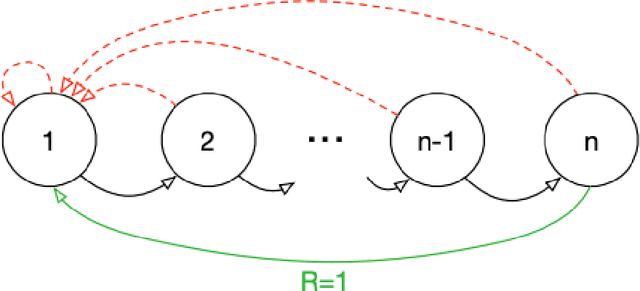

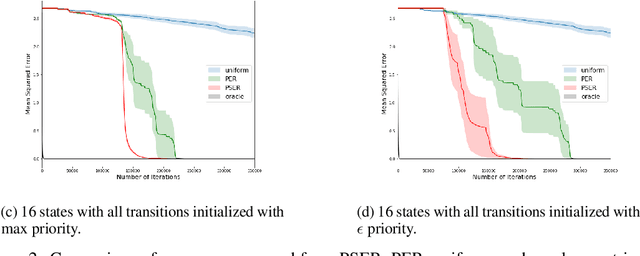
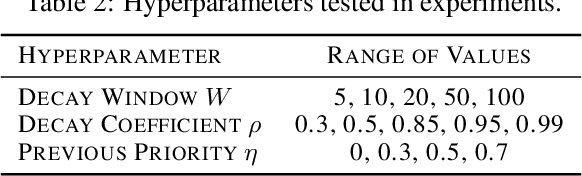
Experience replay is widely used in deep reinforcement learning algorithms and allows agents to remember and learn from experiences from the past. In an effort to learn more efficiently, researchers proposed prioritized experience replay (PER) which samples important transitions more frequently. In this paper, we propose Prioritized Sequence Experience Replay (PSER) a framework for prioritizing sequences of experience in an attempt to both learn more efficiently and to obtain better performance. We compare performance of uniform, PER and PSER sampling techniques in DQN on the Atari 2600 benchmark and show DQN with PSER substantially outperforms PER and uniform sampling.
Autonomous Air Traffic Controller: A Deep Multi-Agent Reinforcement Learning Approach
May 02, 2019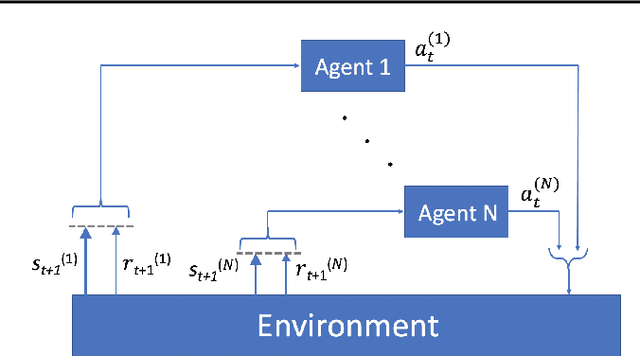
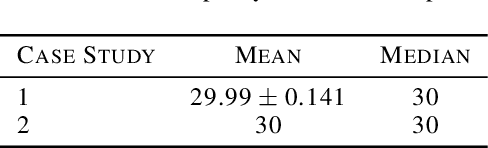
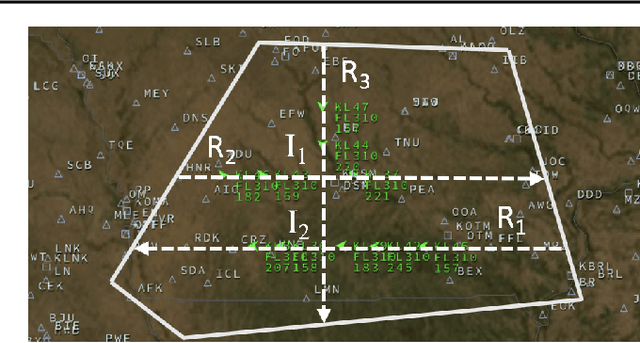
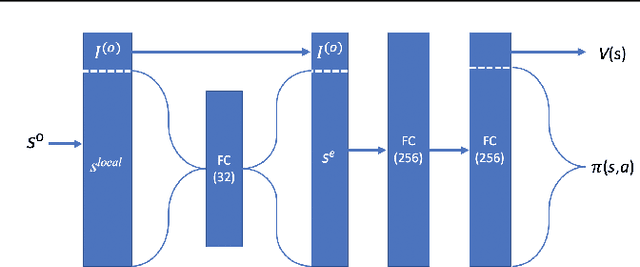
Air traffic control is a real-time safety-critical decision making process in highly dynamic and stochastic environments. In today's aviation practice, a human air traffic controller monitors and directs many aircraft flying through its designated airspace sector. With the fast growing air traffic complexity in traditional (commercial airliners) and low-altitude (drones and eVTOL aircraft) airspace, an autonomous air traffic control system is needed to accommodate high density air traffic and ensure safe separation between aircraft. We propose a deep multi-agent reinforcement learning framework that is able to identify and resolve conflicts between aircraft in a high-density, stochastic, and dynamic en-route sector with multiple intersections and merging points. The proposed framework utilizes an actor-critic model, A2C that incorporates the loss function from Proximal Policy Optimization (PPO) to help stabilize the learning process. In addition we use a centralized learning, decentralized execution scheme where one neural network is learned and shared by all agents in the environment. We show that our framework is both scalable and efficient for large number of incoming aircraft to achieve extremely high traffic throughput with safety guarantee. We evaluate our model via extensive simulations in the BlueSky environment. Results show that our framework is able to resolve 99.97% and 100% of all conflicts both at intersections and merging points, respectively, in extreme high-density air traffic scenarios.
Hierarchical Reinforcement Learning with Deep Nested Agents
May 18, 2018
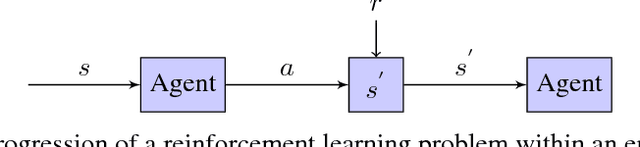

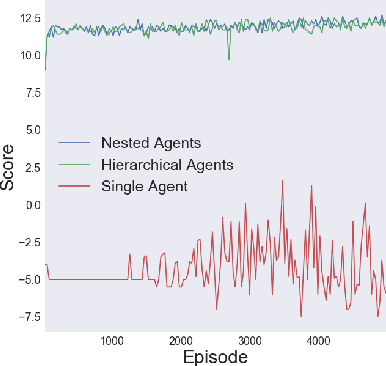
Deep hierarchical reinforcement learning has gained a lot of attention in recent years due to its ability to produce state-of-the-art results in challenging environments where non-hierarchical frameworks fail to learn useful policies. However, as problem domains become more complex, deep hierarchical reinforcement learning can become inefficient, leading to longer convergence times and poor performance. We introduce the Deep Nested Agent framework, which is a variant of deep hierarchical reinforcement learning where information from the main agent is propagated to the low level $nested$ agent by incorporating this information into the nested agent's state. We demonstrate the effectiveness and performance of the Deep Nested Agent framework by applying it to three scenarios in Minecraft with comparisons to a deep non-hierarchical single agent framework, as well as, a deep hierarchical framework.