 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritized Sequence Experience Replay
May 25, 2019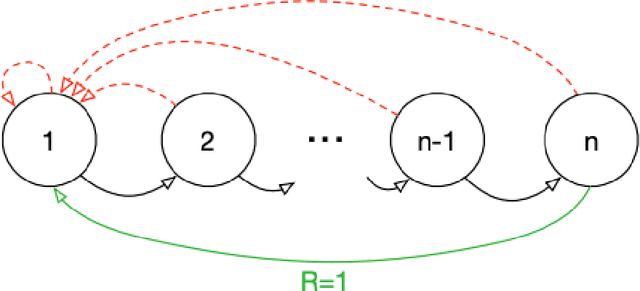

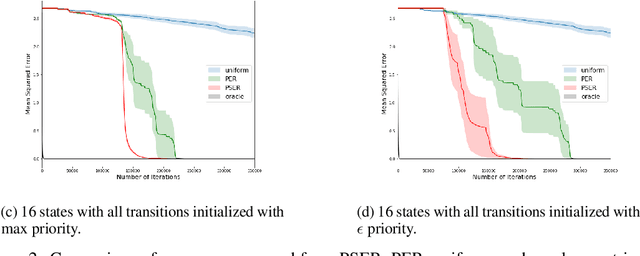
Experience replay is widely used in deep reinforcement learning algorithms and allows agents to remember and learn from experiences from the past. In an effort to learn more efficiently, researchers proposed prioritized experience replay (PER) which samples important transitions more frequently. In this paper, we propose Prioritized Sequence Experience Replay (PSER) a framework for prioritizing sequences of experience in an attempt to both learn more efficiently and to obtain better performance. We compare performance of uniform, PER and PSER sampling techniques in DQN on the Atari 2600 benchmark and show DQN with PSER substantially outperforms PER and uniform sampling.
Explainable Deterministic MDPs
Jun 09, 2018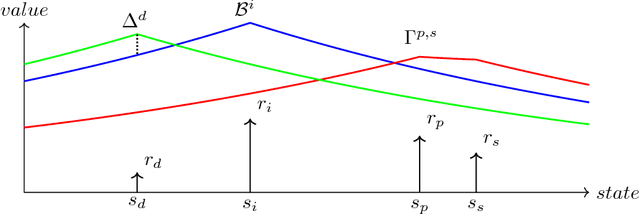
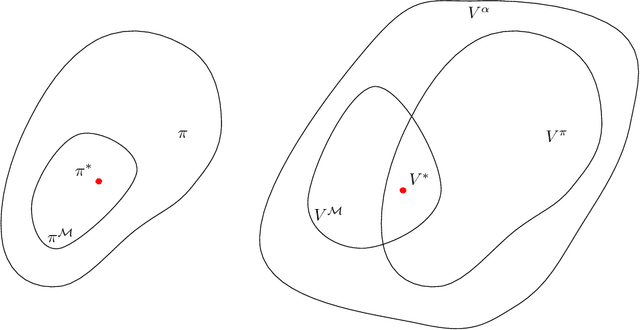

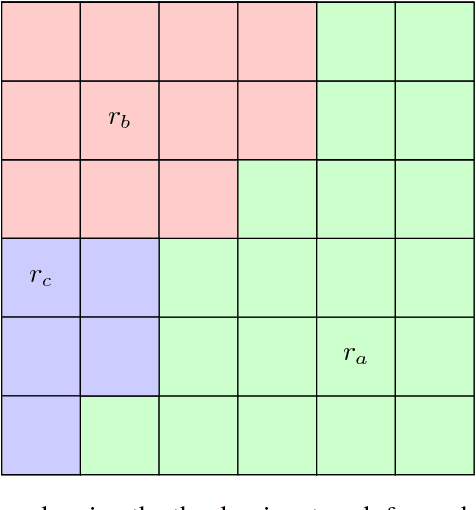
We present a method for a certain class of Markov Decision Processes (MDPs) that can relate the optimal policy back to one or more reward sources in the environment. For a given initial state, without fully computing the value function, q-value function, or the optimal policy the algorithm can determine which rewards will and will not be collected, whether a given reward will be collected only once or continuously, and which local maximum within the value function the initial state will ultimately lead to. We demonstrate that the method can be used to map the state space to identify regions that are dominated by one reward source and can fully analyze the state space to explain all actions. We provide a mathematical framework to show how all of this is possible without first computing the optimal policy or value function.