 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Control for Searching and Planning with a Learned Model
Jun 22, 2020
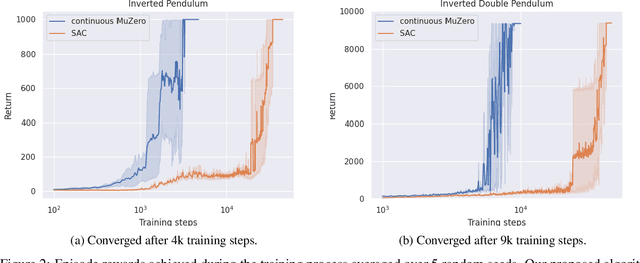
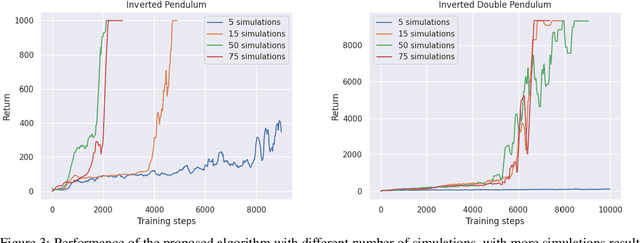
Decision-making agents with planning capabilities have achieved huge success in the challenging domain like Chess, Shogi, and Go. In an effort to generalize the planning ability to the more general tasks where the environment dynamics are not available to the agent, researchers proposed the MuZero algorithm that can learn the dynamical model through the interactions with the environment. In this paper, we provide a way and the necessary theoretical results to extend the MuZero algorithm to more generalized environments with continuous action space. Through numerical results on two relatively low-dimensional MuJoCo environments, we show the proposed algorithm outperforms the soft actor-critic (SAC) algorithm, a state-of-the-art model-free deep reinforcement learning algorithm.