 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4
May 12, 2023In recent years, large language models (LLMs) have made significant progress in natural language processing (NLP), with models like ChatGPT and GPT-4 achieving impressive capabilities in various linguistic tasks. However, training models on such a large scale is challenging, and finding datasets that match the model's scale is often difficult. Fine-tuning and training models with fewer parameters using novel methods have emerged as promising approaches to overcome these challenges. One such model is MiniGPT-4, which achieves comparable vision-language understanding to GPT-4 by leveraging novel pre-training models and innovative training strategies. However, the model still faces some challenges in image understanding, particularly in artistic pictures. A novel multimodal model called ArtGPT-4 has been proposed to address these limitations. ArtGPT-4 was trained on image-text pairs using a Tesla A100 device in just 2 hours, using only about 200 GB of data. The model can depict images with an artistic flair and generate visual code, including aesthetically pleasing HTML/CSS web pages. Furthermore, the article proposes novel benchmarks for evaluating the performance of vision-language models. In the subsequent evaluation methods, ArtGPT-4 scored more than 1 point higher than the current \textbf{state-of-the-art} model and was only 0.25 points lower than artists on a 6-point scale. Our code and pre-trained model are available at \url{https://huggingface.co/Tyrannosaurus/ArtGPT-4}.
RPN: A Word Vector Level Data Augmentation Algorithm in Deep Learning for Language Understanding
Dec 12, 2022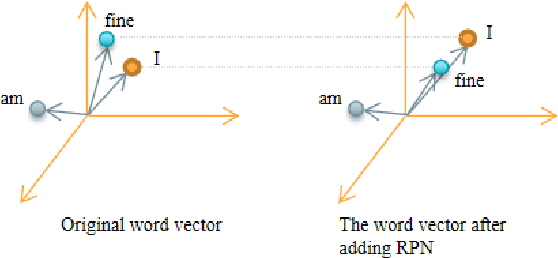
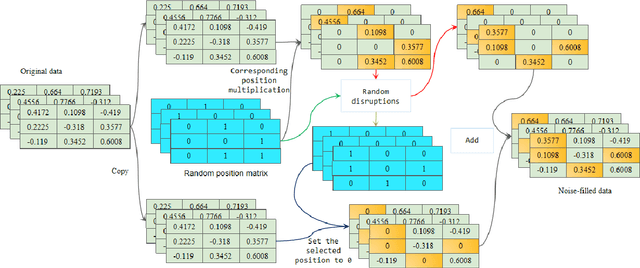
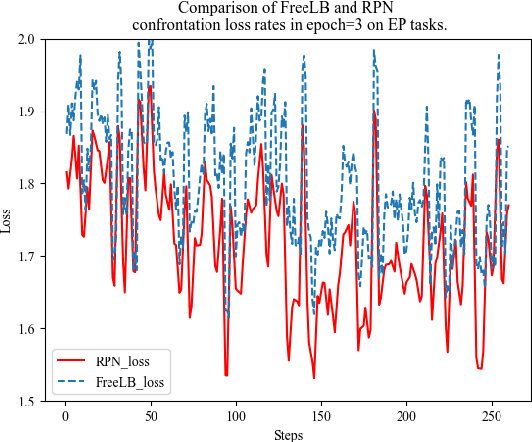
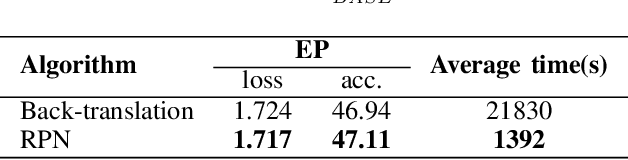
This paper presents a new data augmentation algorithm for natural understanding tasks, called RPN:Random Position Noise algorithm.Due to the relative paucity of current text augmentation methods. Few of the extant methods apply to natural language understanding tasks for all sentence-level tasks.RPN applies the traditional augmentation on the original text to the word vector level. The RPN algorithm makes a substitution in one or several dimensions of some word vectors. As a result, the RPN can introduce a certain degree of perturbation to the sample and can adjust the range of perturbation on different tasks. The augmented samples are then used to give the model training.This makes the model more robust. In subsequent experiments, we found that adding RPN to the training or fine-tuning model resulted in a stable boost on all 8 natural language processing tasks, including TweetEval, CoLA, and SST-2 datasets, and more significant improvements than other data augmentation algorithms.The RPN algorithm applies to all sentence-level tasks for language understanding and is used in any deep learning model with a word embedding layer.