 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEditVis: A Visual Analytics System for Knowledge Editing of Large Language Models
Mar 31, 2026Large Language Models (LLMs) demonstrate exceptional capabilities in factual question answering, yet they sometimes provide incorrect responses. To address this issue, knowledge editing techniques have emerged as effective methods for correcting factual information in LLMs. However, typical knowledge editing workflows struggle with identifying the optimal set of model layers for editing and rely on summary indicators that provide insufficient guidance. This lack of transparency hinders effective comparison and identification of optimal editing strategies. In this paper, we present KEditVis, a novel visual analytics system designed to assist users in gaining a deeper understanding of knowledge editing through interactive visualizations, improving editing outcomes, and discovering valuable insights for the future development of knowledge editing algorithms. With KEditVis, users can select appropriate layers as the editing target, explore the reasons behind ineffective edits, and perform more targeted and effective edits. Our evaluation, including usage scenarios, expert interviews, and a user study, validates the effectiveness and usability of the system.
Do LLM-Driven Agents Exhibit Engagement Mechanisms? Controlled Tests of Information Load, Descriptive Norms, and Popularity Cues
Mar 21, 2026Large language models make agent-based simulation more behaviorally expressive, but they also sharpen a basic methodological tension: fluent, human-like output is not, by itself, evidence for theory. We evaluate what an LLM-driven simulation can credibly support using information engagement on social media as a test case. In a Weibo-like environment, we manipulate information load and descriptive norms, while allowing popularity cues (cumulative likes and Sina Weibo-style cumulative reshares) to evolve endogenously. We then ask whether simulated behavior changes in theoretically interpretable ways under these controlled variations, rather than merely producing plausible-looking traces. Engagement responds systematically to information load and descriptive norms, and sensitivity to popularity cues varies across contexts, indicating conditionality rather than rigid prompt compliance. We discuss methodological implications for simulation-based communication research, including multi-condition stress tests, explicit no-norm baselines because default prompts are not blank controls, and design choices that preserve endogenous feedback loops when studying bandwagon dynamics.
RiskAtlas: Exposing Domain-Specific Risks in LLMs through Knowledge-Graph-Guided Harmful Prompt Generation
Jan 08, 2026Large language models (LLMs) are increasingly applied in specialized domains such as finance and healthcare, where they introduce unique safety risks. Domain-specific datasets of harmful prompts remain scarce and still largely rely on manual construction; public datasets mainly focus on explicit harmful prompts, which modern LLM defenses can often detect and refuse. In contrast, implicit harmful prompts-expressed through indirect domain knowledge-are harder to detect and better reflect real-world threats. We identify two challenges: transforming domain knowledge into actionable constraints and increasing the implicitness of generated harmful prompts. To address them, we propose an end-to-end framework that first performs knowledge-graph-guided harmful prompt generation to systematically produce domain-relevant prompts, and then applies dual-path obfuscation rewriting to convert explicit harmful prompts into implicit variants via direct and context-enhanced rewriting. This framework yields high-quality datasets combining strong domain relevance with implicitness, enabling more realistic red-teaming and advancing LLM safety research. We release our code and datasets at GitHub.
CycleChart: A Unified Consistency-Based Learning Framework for Bidirectional Chart Understanding and Generation
Dec 22, 2025Current chart-specific tasks, such as chart question answering, chart parsing, and chart generation, are typically studied in isolation, preventing models from learning the shared semantics that link chart generation and interpretation. We introduce CycleChart, a consistency-based learning framework for bidirectional chart understanding and generation. CycleChart adopts a schema-centric formulation as a common interface across tasks. We construct a consistent multi-task dataset, where each chart sample includes aligned annotations for schema prediction, data parsing, and question answering. To learn cross-directional chart semantics, CycleChart introduces a generate-parse consistency objective: the model generates a chart schema from a table and a textual query, then learns to recover the schema and data from the generated chart, enforcing semantic alignment across directions. CycleChart achieves strong results on chart generation, chart parsing, and chart question answering, demonstrating improved cross-task generalization and marking a step toward more general chart understanding models.
Linking Heterogeneous Data with Coordinated Agent Flows for Social Media Analysis
Oct 30, 2025Social media platforms generate massive volumes of heterogeneous data, capturing user behaviors, textual content, temporal dynamics, and network structures. Analyzing such data is crucial for understanding phenomena such as opinion dynamics, community formation, and information diffusion. However, discovering insights from this complex landscape is exploratory, conceptually challenging, and requires expertise in social media mining and visualization. Existing automated approaches, though increasingly leveraging large language models (LLMs), remain largely confined to structured tabular data and cannot adequately address the heterogeneity of social media analysis. We present SIA (Social Insight Agents), an LLM agent system that links heterogeneous multi-modal data -- including raw inputs (e.g., text, network, and behavioral data), intermediate outputs, mined analytical results, and visualization artifacts -- through coordinated agent flows. Guided by a bottom-up taxonomy that connects insight types with suitable mining and visualization techniques, SIA enables agents to plan and execute coherent analysis strategies. To ensure multi-modal integration, it incorporates a data coordinator that unifies tabular, textual, and network data into a consistent flow. Its interactive interface provides a transparent workflow where users can trace, validate, and refine the agent's reasoning, supporting both adaptability and trustworthiness. Through expert-centered case studies and quantitative evaluation, we show that SIA effectively discovers diverse and meaningful insights from social media while supporting human-agent collaboration in complex analytical tasks.
ProTAL: A Drag-and-Link Video Programming Framework for Temporal Action Localization
May 23, 2025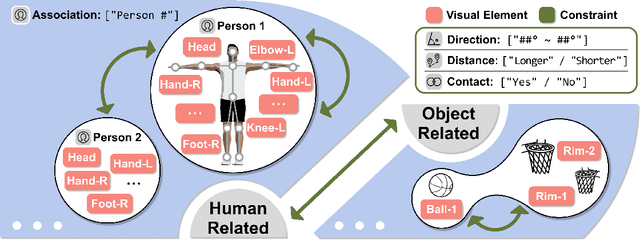
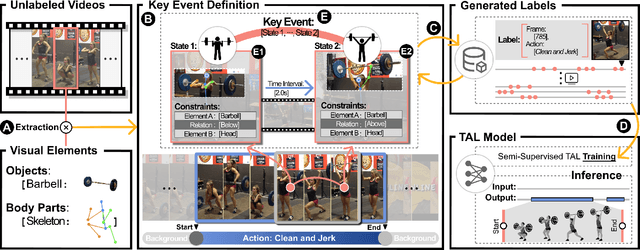
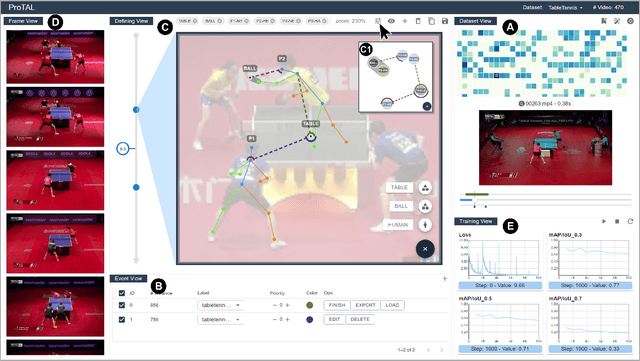
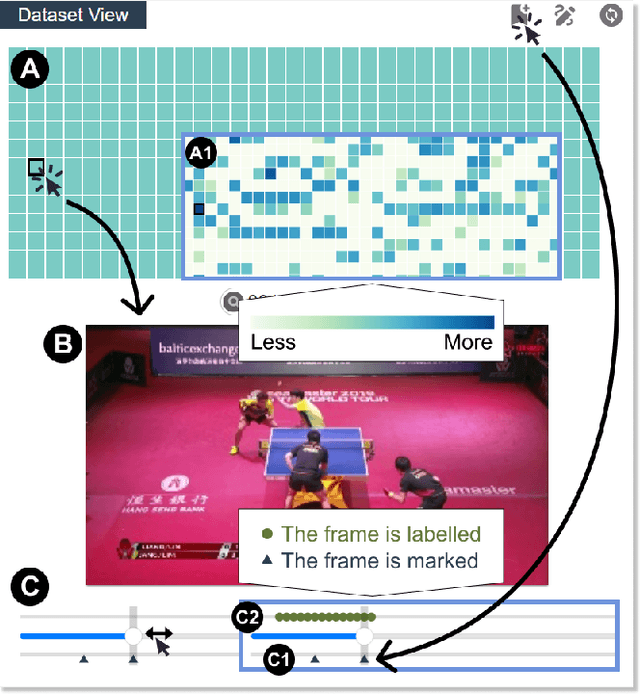
Temporal Action Localization (TAL) aims to detect the start and end timestamps of actions in a video. However, the training of TAL models requires a substantial amount of manually annotated data. Data programming is an efficient method to create training labels with a series of human-defined labeling functions. However, its application in TAL faces difficulties of defining complex actions in the context of temporal video frames. In this paper, we propose ProTAL, a drag-and-link video programming framework for TAL. ProTAL enables users to define \textbf{key events} by dragging nodes representing body parts and objects and linking them to constrain the relations (direction, distance, etc.). These definitions are used to generate action labels for large-scale unlabelled videos. A semi-supervised method is then employed to train TAL models with such labels. We demonstrate the effectiveness of ProTAL through a usage scenario and a user study, providing insights into designing video programming framework.
ReSpark: Leveraging Previous Data Reports as References to Generate New Reports with LLMs
Feb 04, 2025Creating data reports is time-consuming, as it requires iterative exploration and understanding of data, followed by summarizing the insights. While large language models (LLMs) are powerful tools for data processing and text generation, they often struggle to produce complete data reports that fully meet user expectations. One significant challenge is effectively communicating the entire analysis logic to LLMs. Moreover, determining a comprehensive analysis logic can be mentally taxing for users. To address these challenges, we propose ReSpark, an LLM-based method that leverages existing data reports as references for creating new ones. Given a data table, ReSpark searches for similar-topic reports, parses them into interdependent segments corresponding to analytical objectives, and executes them with new data. It identifies inconsistencies and customizes the objectives, data transformations, and textual descriptions. ReSpark allows users to review real-time outputs, insert new objectives, and modify report content. Its effectiveness was evaluated through comparative and user studies.
ViSTec: Video Modeling for Sports Technique Recognition and Tactical Analysis
Feb 25, 2024The immense popularity of racket sports has fueled substantial demand in tactical analysis with broadcast videos. However, existing manual methods require laborious annotation, and recent attempts leveraging video perception models are limited to low-level annotations like ball trajectories, overlooking tactics that necessitate an understanding of stroke techniques. State-of-the-art action segmentation models also struggle with technique recognition due to frequent occlusions and motion-induced blurring in racket sports videos. To address these challenges, We propose ViSTec, a Video-based Sports Technique recognition model inspired by human cognition that synergizes sparse visual data with rich contextual insights. Our approach integrates a graph to explicitly model strategic knowledge in stroke sequences and enhance technique recognition with contextual inductive bias. A two-stage action perception model is jointly trained to align with the contextual knowledge in the graph. Experiments demonstrate that our method outperforms existing models by a significant margin. Case studies with experts from the Chinese national table tennis team validate our model's capacity to automate analysis for technical actions and tactical strategies. More details are available at: https://ViSTec2024.github.io/.
EventAnchor: Reducing Human Interactions in Event Annotation of Racket Sports Videos
Jan 14, 2021

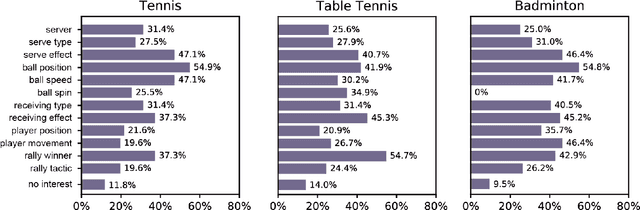
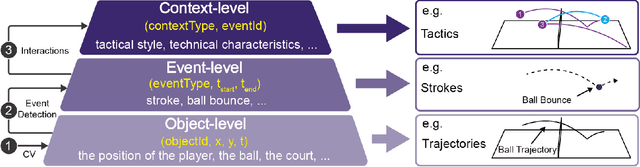
The popularity of racket sports (e.g., tennis and table tennis) leads to high demands for data analysis, such as notational analysis, on player performance. While sports videos offer many benefits for such analysis, retrieving accurate information from sports videos could be challenging. In this paper, we propose EventAnchor, a data analysis framework to facilitate interactive annotation of racket sports video with the support of computer vision algorithms. Our approach uses machine learning models in computer vision to help users acquire essential events from videos (e.g., serve, the ball bouncing on the court) and offers users a set of interactive tools for data annotation. An evaluation study on a table tennis annotation system built on this framework shows significant improvement of user performances in simple annotation tasks on objects of interest and complex annotation tasks requiring domain knowledge.
VisImages: A Large-scale, High-quality Image Corpus in Visualization Publications
Jul 10, 2020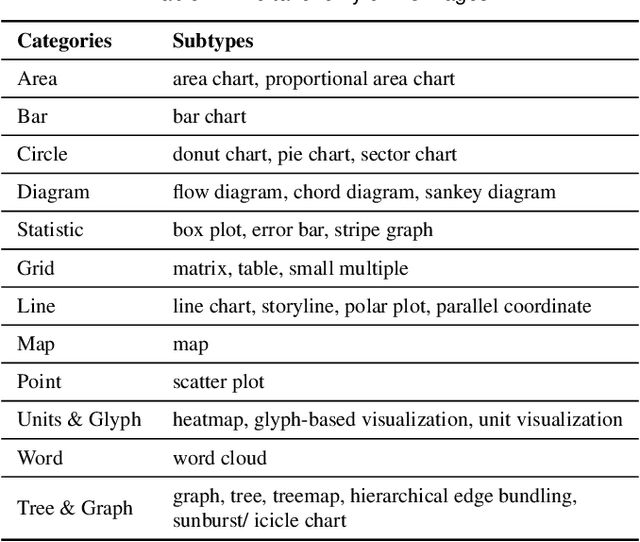
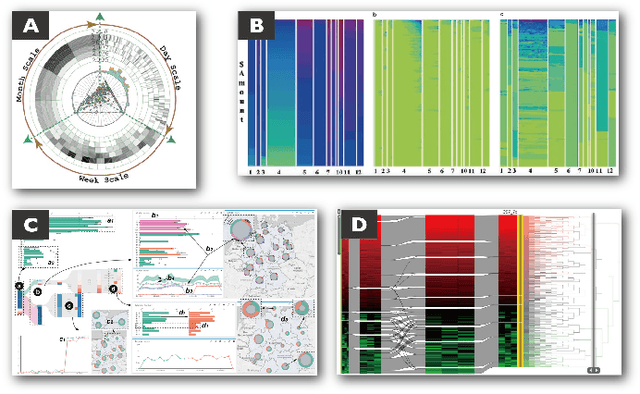

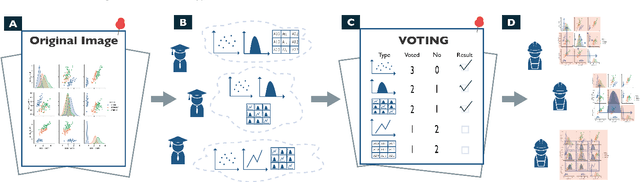
Images in visualization publications contain rich information, such as novel visual designs, model details, and experiment results. Constructing such an image corpus can contribute to the community in many aspects, including literature analysis from the perspective of visual representations, empirical studies on visual memorability, and machine learning research for chart detection. This study presents VisImages, a high-quality and large-scale image corpus collected from visualization publications. VisImages contain fruitful and diverse annotations for each image, including captions, types of visual representations, and bounding boxes. First, we algorithmically extract the images associated with captions and manually correct the errors. Second, to categorize visualizations in publications, we extend and iteratively refine the existing taxonomy through a multi-round pilot study. Third, guided by this taxonomy, we invite senior visualization practitioners to annotate visual representations that appear in each image. In this process, we borrow techniques such as "gold standards" and majority voting for quality control. Finally, we recruit the crowd to draw bounding boxes for visual representations in the images. The resulting corpus contains 35,096 annotated visualizations from 12,267 images with 12,057 captions in 1397 papers from VAST and InfoVis. We demonstrate the usefulness of VisImages through the following four use cases: 1) analysis of color usage in VAST and InfoVis papers across years, 2) discussion of the researcher preference on visualization types, 3) spatial distribution analysis of visualizations in visual analytic systems, and 4) training visualization detection models.