 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-targeted Membership Inference Attacks on Safety Classifiers
May 21, 2026Safety classifiers are essential safeguards within generative AI systems, filtering harmful content or identifying at-risk users when interacting with large language models. Despite their necessity, these models are trained on sensitive datasets including discussions of self-harm and mental health, raising important, yet poorly understood, privacy concerns. Membership inference attacks (MIAs) allow adversaries to infer membership of examples used to train models. In this work, we hypothesize that identifying the examples on which the classifier is least confident are informative for an adversary to infer membership. This reflects a localized failure of generalization, where the model relies on memorization to resolve ambiguity in the training set. To investigate this, we introduce a new boundary-targeted selection strategy that identifies low confidence examples that amplify the signal of an examples membership within a training set. Our experimental results show that an adversary can recover 19\% of the conversations a safety classifier flagged as indicating user distress, at a 5\% false-positive rate, on a classifier fine-tuned for detecting a user who may require emotional support. This is $3.5$ times more than attacking using state-of-the-art MIA methods alone. Finally, we characterize the boundary laying examples and show that content-based filtering is ineffective for protection, and existing noise strategies can effectively mitigate susceptibility of these examples.
More Than "Means to an End": Supporting Reasoning with Transparently Designed AI Data Science Processes
Mar 25, 2026Generative artificial intelligence (AI) tools can now help people perform complex data science tasks regardless of their expertise. While these tools have great potential to help more people work with data, their end-to-end approach does not support users in evaluating alternative approaches and reformulating problems, both critical to solving open-ended tasks in high-stakes domains. In this paper, we reflect on two AI data science systems designed for the medical setting and how they function as tools for thought. We find that success in these systems was driven by constructing AI workflows around intentionally-designed intermediate artifacts, such as readable query languages, concept definitions, or input-output examples. Despite opaqueness in other parts of the AI process, these intermediates helped users reason about important analytical choices, refine their initial questions, and contribute their unique knowledge. We invite the HCI community to consider when and how intermediate artifacts should be designed to promote effective data science thinking.
MM-SCALE: Grounded Multimodal Moral Reasoning via Scalar Judgment and Listwise Alignment
Feb 03, 2026Vision-Language Models (VLMs) continue to struggle to make morally salient judgments in multimodal and socially ambiguous contexts. Prior works typically rely on binary or pairwise supervision, which often fail to capture the continuous and pluralistic nature of human moral reasoning. We present MM-SCALE (Multimodal Moral Scale), a large-scale dataset for aligning VLMs with human moral preferences through 5-point scalar ratings and explicit modality grounding. Each image-scenario pair is annotated with moral acceptability scores and grounded reasoning labels by humans using an interface we tailored for data collection, enabling listwise preference optimization over ranked scenario sets. By moving from discrete to scalar supervision, our framework provides richer alignment signals and finer calibration of multimodal moral reasoning. Experiments show that VLMs fine-tuned on MM-SCALE achieve higher ranking fidelity and more stable safety calibration than those trained with binary signals.
Intelligent Reasoning Cues: A Framework and Case Study of the Roles of AI Information in Complex Decisions
Jan 30, 2026Artificial intelligence (AI)-based decision support systems can be highly accurate yet still fail to support users or improve decisions. Existing theories of AI-assisted decision-making focus on calibrating reliance on AI advice, leaving it unclear how different system designs might influence the reasoning processes underneath. We address this gap by reconsidering AI interfaces as collections of intelligent reasoning cues: discrete pieces of AI information that can individually influence decision-making. We then explore the roles of eight types of reasoning cues in a high-stakes clinical decision (treating patients with sepsis in intensive care). Through contextual inquiries with six teams and a think-aloud study with 25 physicians, we find that reasoning cues have distinct patterns of influence that can directly inform design. Our results also suggest that reasoning cues should prioritize tasks with high variability and discretion, adapt to ensure compatibility with evolving decision needs, and provide complementary, rigorous insights on complex cases.
Over-Relying on Reliance: Towards Realistic Evaluations of AI-Based Clinical Decision Support
Apr 10, 2025As AI-based clinical decision support (AI-CDS) is introduced in more and more aspects of healthcare services, HCI research plays an increasingly important role in designing for complementarity between AI and clinicians. However, current evaluations of AI-CDS often fail to capture when AI is and is not useful to clinicians. This position paper reflects on our work and influential AI-CDS literature to advocate for moving beyond evaluation metrics like Trust, Reliance, Acceptance, and Performance on the AI's task (what we term the "trap" of human-AI collaboration). Although these metrics can be meaningful in some simple scenarios, we argue that optimizing for them ignores important ways that AI falls short of clinical benefit, as well as ways that clinicians successfully use AI. As the fields of HCI and AI in healthcare develop new ways to design and evaluate CDS tools, we call on the community to prioritize ecologically valid, domain-appropriate study setups that measure the emergent forms of value that AI can bring to healthcare professionals.
How Consistent are Clinicians? Evaluating the Predictability of Sepsis Disease Progression with Dynamics Models
Apr 10, 2024Reinforcement learning (RL) is a promising approach to generate treatment policies for sepsis patients in intensive care. While retrospective evaluation metrics show decreased mortality when these policies are followed, studies with clinicians suggest their recommendations are often spurious. We propose that these shortcomings may be due to lack of diversity in observed actions and outcomes in the training data, and we construct experiments to investigate the feasibility of predicting sepsis disease severity changes due to clinician actions. Preliminary results suggest incorporating action information does not significantly improve model performance, indicating that clinician actions may not be sufficiently variable to yield measurable effects on disease progression. We discuss the implications of these findings for optimizing sepsis treatment.
The Impact of Imperfect XAI on Human-AI Decision-Making
Jul 25, 2023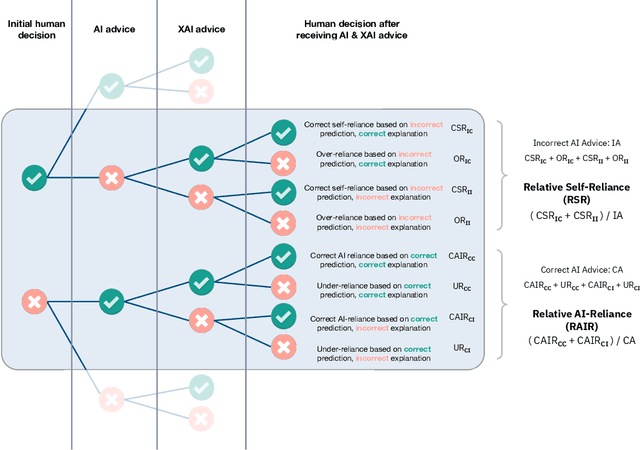
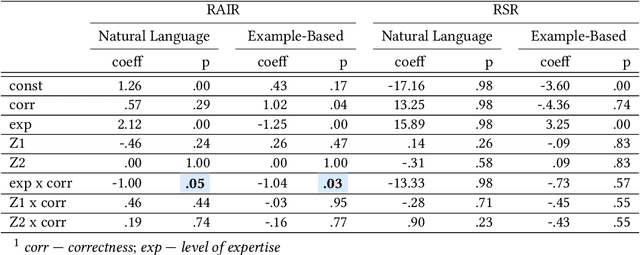
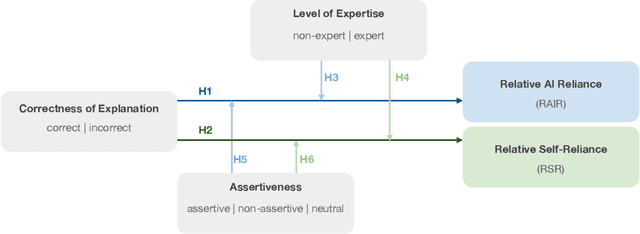
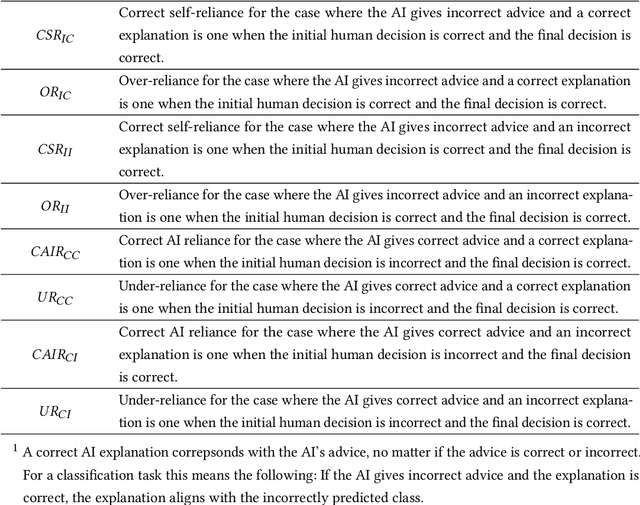
Explainability techniques are rapidly being developed to improve human-AI decision-making across various cooperative work settings. Consequently, previous research has evaluated how decision-makers collaborate with imperfect AI by investigating appropriate reliance and task performance with the aim of designing more human-centered computer-supported collaborative tools. Several human-centered explainable AI (XAI) techniques have been proposed in hopes of improving decision-makers' collaboration with AI; however, these techniques are grounded in findings from previous studies that primarily focus on the impact of incorrect AI advice. Few studies acknowledge the possibility for the explanations to be incorrect even if the AI advice is correct. Thus, it is crucial to understand how imperfect XAI affects human-AI decision-making. In this work, we contribute a robust, mixed-methods user study with 136 participants to evaluate how incorrect explanations influence humans' decision-making behavior in a bird species identification task taking into account their level of expertise and an explanation's level of assertiveness. Our findings reveal the influence of imperfect XAI and humans' level of expertise on their reliance on AI and human-AI team performance. We also discuss how explanations can deceive decision-makers during human-AI collaboration. Hence, we shed light on the impacts of imperfect XAI in the field of computer-supported cooperative work and provide guidelines for designers of human-AI collaboration systems.
Improving Human-AI Collaboration With Descriptions of AI Behavior
Jan 06, 2023
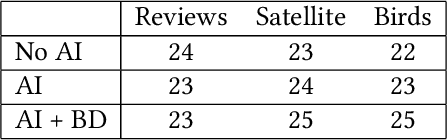

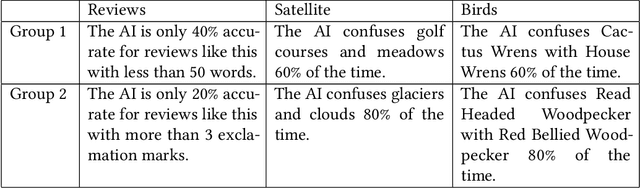
People work with AI systems to improve their decision making, but often under- or over-rely on AI predictions and perform worse than they would have unassisted. To help people appropriately rely on AI aids, we propose showing them behavior descriptions, details of how AI systems perform on subgroups of instances. We tested the efficacy of behavior descriptions through user studies with 225 participants in three distinct domains: fake review detection, satellite image classification, and bird classification. We found that behavior descriptions can increase human-AI accuracy through two mechanisms: helping people identify AI failures and increasing people's reliance on the AI when it is more accurate. These findings highlight the importance of people's mental models in human-AI collaboration and show that informing people of high-level AI behaviors can significantly improve AI-assisted decision making.
* 21 pages
"Public(s)-in-the-Loop": Facilitating Deliberation of Algorithmic Decisions in Contentious Public Policy Domains
Apr 22, 2022This position paper offers a framework to think about how to better involve human influence in algorithmic decision-making of contentious public policy issues. Drawing from insights in communication literature, we introduce a "public(s)-in-the-loop" approach and enumerates three features that are central to this approach: publics as plural political entities, collective decision-making through deliberation, and the construction of publics. It explores how these features might advance our understanding of stakeholder participation in AI design in contentious public policy domains such as recidivism prediction. Finally, it sketches out part of a research agenda for the HCI community to support this work.
Improving Human-AI Partnerships in Child Welfare: Understanding Worker Practices, Challenges, and Desires for Algorithmic Decision Support
Apr 05, 2022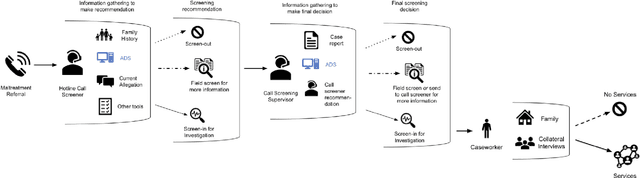
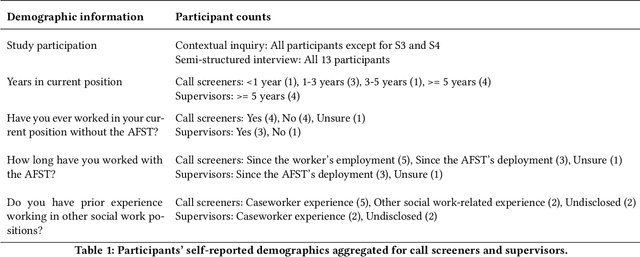
AI-based decision support tools (ADS) are increasingly used to augment human decision-making in high-stakes, social contexts. As public sector agencies begin to adopt ADS, it is critical that we understand workers' experiences with these systems in practice. In this paper, we present findings from a series of interviews and contextual inquiries at a child welfare agency, to understand how they currently make AI-assisted child maltreatment screening decisions. Overall, we observe how workers' reliance upon the ADS is guided by (1) their knowledge of rich, contextual information beyond what the AI model captures, (2) their beliefs about the ADS's capabilities and limitations relative to their own, (3) organizational pressures and incentives around the use of the ADS, and (4) awareness of misalignments between algorithmic predictions and their own decision-making objectives. Drawing upon these findings, we discuss design implications towards supporting more effective human-AI decision-making.