 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-depth Look at Gemini's Language Abilities
Dec 24, 2023The recently released Google Gemini class of models are the first to comprehensively report results that rival the OpenAI GPT series across a wide variety of tasks. In this paper, we do an in-depth exploration of Gemini's language abilities, making two contributions. First, we provide a third-party, objective comparison of the abilities of the OpenAI GPT and Google Gemini models with reproducible code and fully transparent results. Second, we take a closer look at the results, identifying areas where one of the two model classes excels. We perform this analysis over 10 datasets testing a variety of language abilities, including reasoning, answering knowledge-based questions, solving math problems, translating between languages, generating code, and acting as instruction-following agents. From this analysis, we find that Gemini Pro achieves accuracy that is close but slightly inferior to the corresponding GPT 3.5 Turbo on all tasks that we benchmarked. We further provide explanations for some of this under-performance, including failures in mathematical reasoning with many digits, sensitivity to multiple-choice answer ordering, aggressive content filtering, and others. We also identify areas where Gemini demonstrates comparably high performance, including generation into non-English languages, and handling longer and more complex reasoning chains. Code and data for reproduction can be found at https://github.com/neulab/gemini-benchmark
Where Does My Model Underperform? A Human Evaluation of Slice Discovery Algorithms
Jun 13, 2023Machine learning (ML) models that achieve high average accuracy can still underperform on semantically coherent subsets (i.e. "slices") of data. This behavior can have significant societal consequences for the safety or bias of the model in deployment, but identifying these underperforming slices can be difficult in practice, especially in domains where practitioners lack access to group annotations to define coherent subsets of their data. Motivated by these challenges, ML researchers have developed new slice discovery algorithms that aim to group together coherent and high-error subsets of data. However, there has been little evaluation focused on whether these tools help humans form correct hypotheses about where (for which groups) their model underperforms. We conduct a controlled user study (N = 15) where we show 40 slices output by two state-of-the-art slice discovery algorithms to users, and ask them to form hypotheses about where an object detection model underperforms. Our results provide positive evidence that these tools provide some benefit over a naive baseline, and also shed light on challenges faced by users during the hypothesis formation step. We conclude by discussing design opportunities for ML and HCI researchers. Our findings point to the importance of centering users when designing and evaluating new tools for slice discovery.
Improving Human-AI Collaboration With Descriptions of AI Behavior
Jan 06, 2023
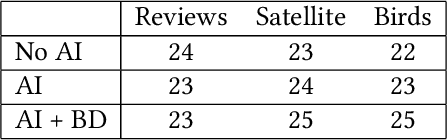

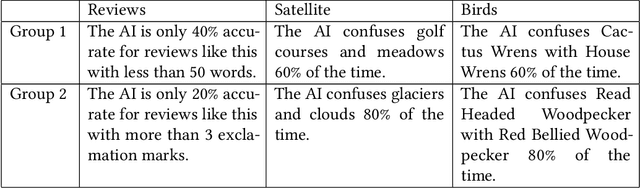
People work with AI systems to improve their decision making, but often under- or over-rely on AI predictions and perform worse than they would have unassisted. To help people appropriately rely on AI aids, we propose showing them behavior descriptions, details of how AI systems perform on subgroups of instances. We tested the efficacy of behavior descriptions through user studies with 225 participants in three distinct domains: fake review detection, satellite image classification, and bird classification. We found that behavior descriptions can increase human-AI accuracy through two mechanisms: helping people identify AI failures and increasing people's reliance on the AI when it is more accurate. These findings highlight the importance of people's mental models in human-AI collaboration and show that informing people of high-level AI behaviors can significantly improve AI-assisted decision making.
* 21 pages
Evaluating Systemic Error Detection Methods using Synthetic Images
Jul 08, 2022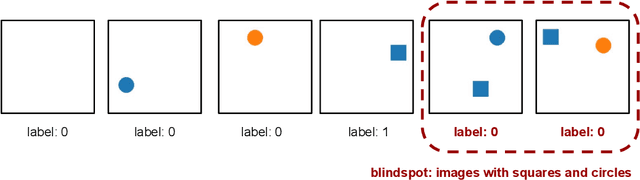
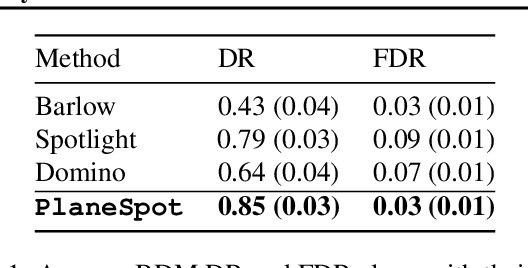
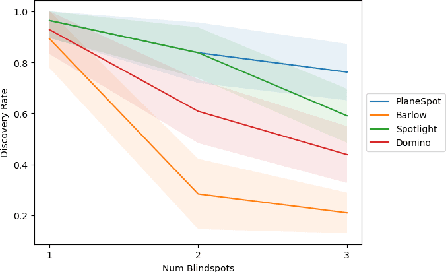

We introduce SpotCheck, a framework for generating synthetic datasets to use for evaluating methods for discovering blindspots (i.e., systemic errors) in image classifiers. We use SpotCheck to run controlled studies of how various factors influence the performance of blindspot discovery methods. Our experiments reveal several shortcomings of existing methods, such as relatively poor performance in settings with multiple blindspots and sensitivity to hyperparameters. Further, we find that a method based on dimensionality reduction, PlaneSpot, is competitive with existing methods, which has promising implications for the development of interactive tools.
"Public(s)-in-the-Loop": Facilitating Deliberation of Algorithmic Decisions in Contentious Public Policy Domains
Apr 22, 2022This position paper offers a framework to think about how to better involve human influence in algorithmic decision-making of contentious public policy issues. Drawing from insights in communication literature, we introduce a "public(s)-in-the-loop" approach and enumerates three features that are central to this approach: publics as plural political entities, collective decision-making through deliberation, and the construction of publics. It explores how these features might advance our understanding of stakeholder participation in AI design in contentious public policy domains such as recidivism prediction. Finally, it sketches out part of a research agenda for the HCI community to support this work.
Symphony: Composing Interactive Interfaces for Machine Learning
Feb 18, 2022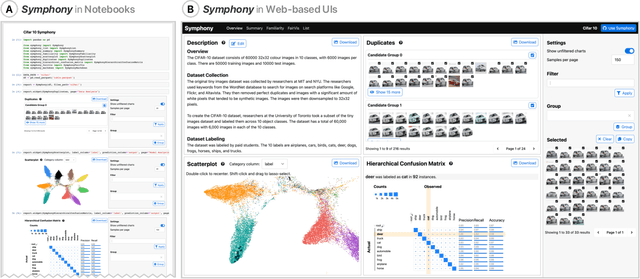
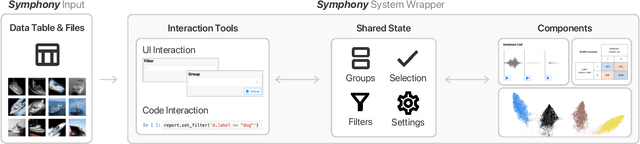
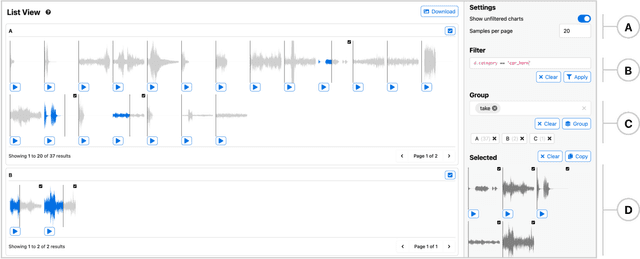
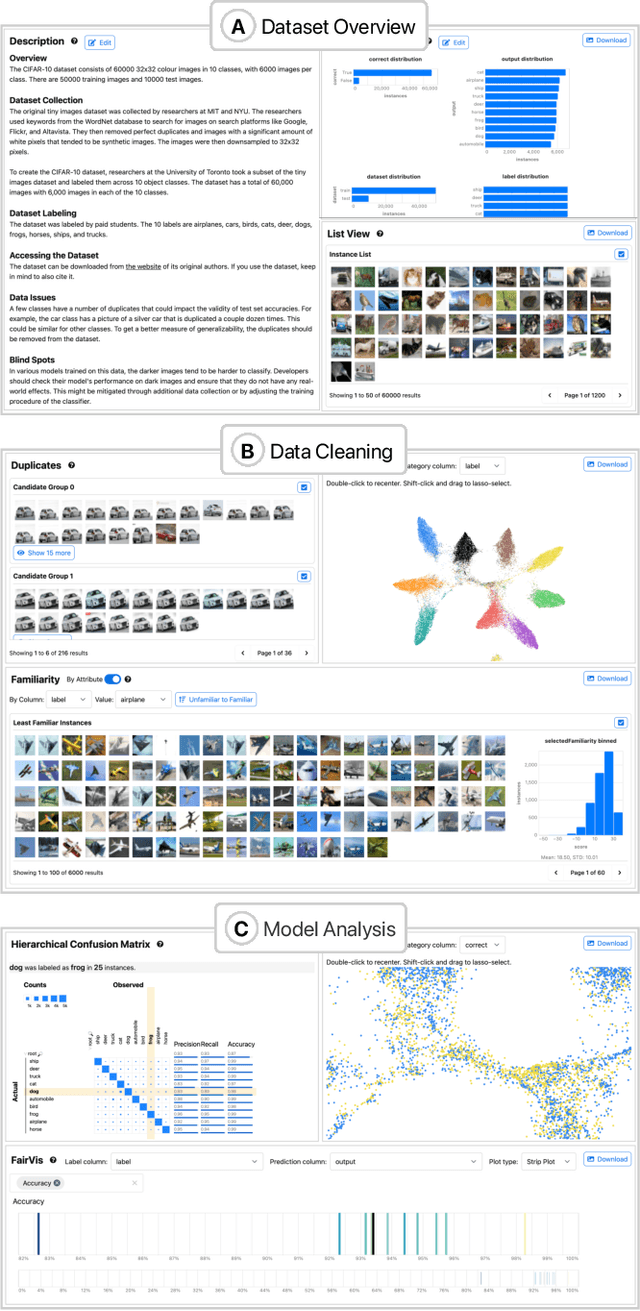
Interfaces for machine learning (ML), information and visualizations about models or data, can help practitioners build robust and responsible ML systems. Despite their benefits, recent studies of ML teams and our interviews with practitioners (n=9) showed that ML interfaces have limited adoption in practice. While existing ML interfaces are effective for specific tasks, they are not designed to be reused, explored, and shared by multiple stakeholders in cross-functional teams. To enable analysis and communication between different ML practitioners, we designed and implemented Symphony, a framework for composing interactive ML interfaces with task-specific, data-driven components that can be used across platforms such as computational notebooks and web dashboards. We developed Symphony through participatory design sessions with 10 teams (n=31), and discuss our findings from deploying Symphony to 3 production ML projects at Apple. Symphony helped ML practitioners discover previously unknown issues like data duplicates and blind spots in models while enabling them to share insights with other stakeholders.
Discovering and Validating AI Errors With Crowdsourced Failure Reports
Sep 23, 2021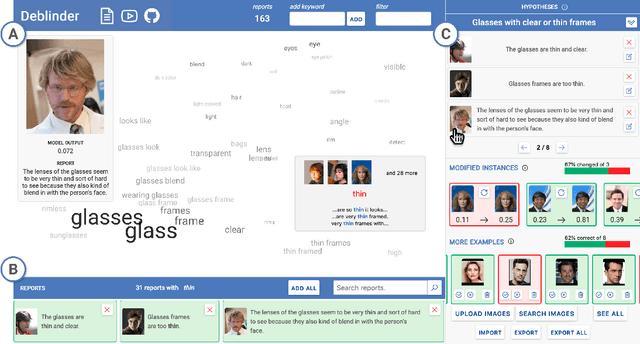
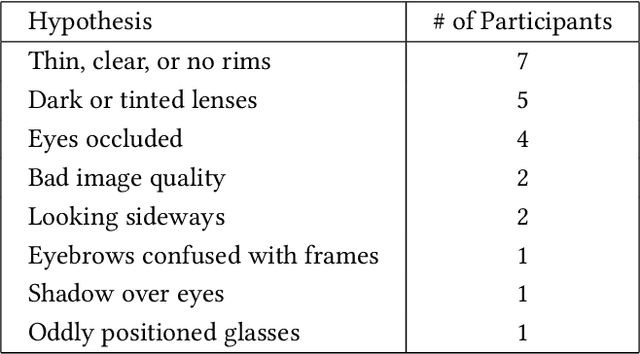
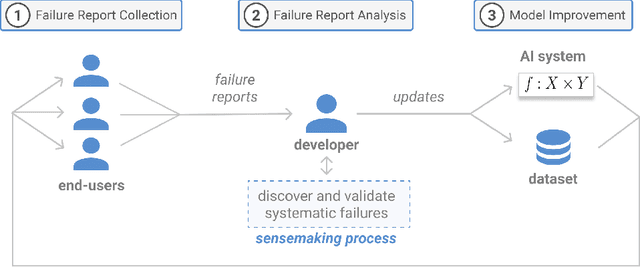

AI systems can fail to learn important behaviors, leading to real-world issues like safety concerns and biases. Discovering these systematic failures often requires significant developer attention, from hypothesizing potential edge cases to collecting evidence and validating patterns. To scale and streamline this process, we introduce crowdsourced failure reports, end-user descriptions of how or why a model failed, and show how developers can use them to detect AI errors. We also design and implement Deblinder, a visual analytics system for synthesizing failure reports that developers can use to discover and validate systematic failures. In semi-structured interviews and think-aloud studies with 10 AI practitioners, we explore the affordances of the Deblinder system and the applicability of failure reports in real-world settings. Lastly, we show how collecting additional data from the groups identified by developers can improve model performance.
FairVis: Visual Analytics for Discovering Intersectional Bias in Machine Learning
Apr 10, 2019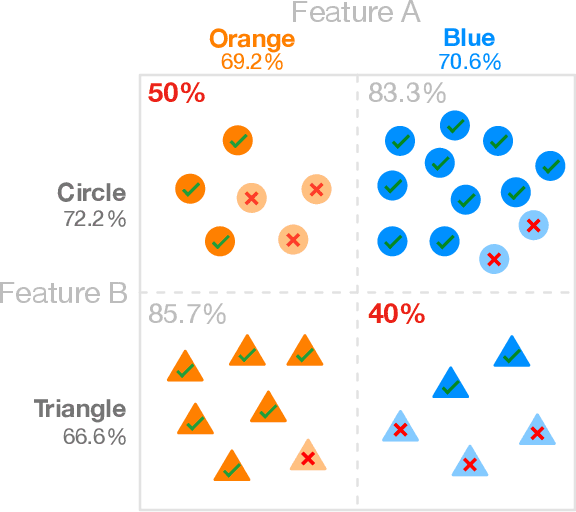
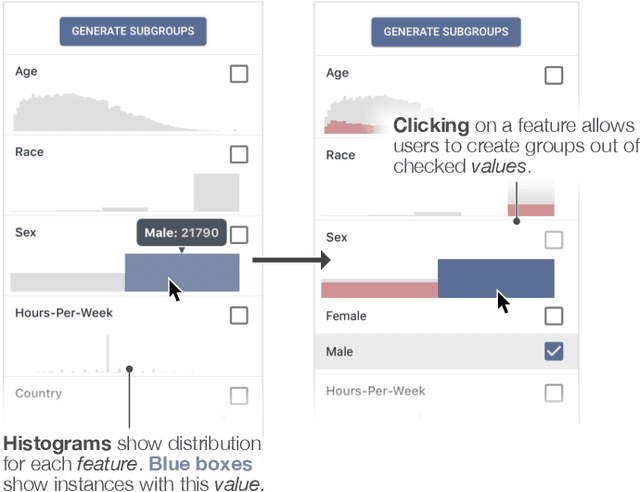
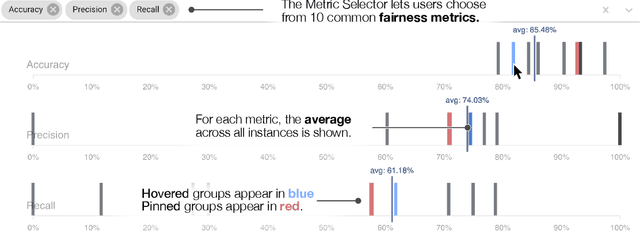
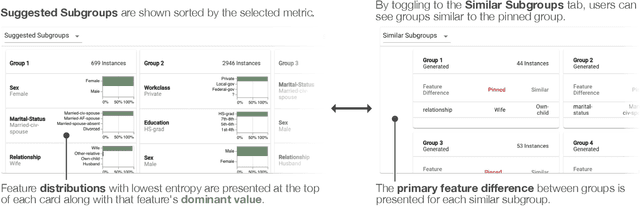
The growing capability and accessibility of machine learning has led to its application to many real-world domains and data about people. Despite the benefits algorithmic systems may bring, models can reflect, inject, or exacerbate implicit and explicit societal biases into their outputs, disadvantaging certain demographic subgroups. Discovering which biases a machine learning model has introduced is a great challenge, due to the numerous definitions of fairness and the large number of potentially impacted subgroups. We present FairVis, a mixed-initiative visual analytics system that integrates a novel subgroup discovery technique for users to audit the fairness of machine learning models. Through FairVis, users can apply domain knowledge to generate and investigate known subgroups, and explore suggested and similar subgroups. FairVis' coordinated views enable users to explore a high-level overview of subgroup performance and subsequently drill down into detailed investigation of specific subgroups. We show how FairVis helps to discover biases in two real datasets used in predicting income and recidivism. As a visual analytics system devoted to discovering bias in machine learning, FairVis demonstrates how interactive visualization may help data scientists and the general public in understanding and creating more equitable algorithmic systems.