 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Does My Model Underperform? A Human Evaluation of Slice Discovery Algorithms
Jun 13, 2023Machine learning (ML) models that achieve high average accuracy can still underperform on semantically coherent subsets (i.e. "slices") of data. This behavior can have significant societal consequences for the safety or bias of the model in deployment, but identifying these underperforming slices can be difficult in practice, especially in domains where practitioners lack access to group annotations to define coherent subsets of their data. Motivated by these challenges, ML researchers have developed new slice discovery algorithms that aim to group together coherent and high-error subsets of data. However, there has been little evaluation focused on whether these tools help humans form correct hypotheses about where (for which groups) their model underperforms. We conduct a controlled user study (N = 15) where we show 40 slices output by two state-of-the-art slice discovery algorithms to users, and ask them to form hypotheses about where an object detection model underperforms. Our results provide positive evidence that these tools provide some benefit over a naive baseline, and also shed light on challenges faced by users during the hypothesis formation step. We conclude by discussing design opportunities for ML and HCI researchers. Our findings point to the importance of centering users when designing and evaluating new tools for slice discovery.
Evaluating Systemic Error Detection Methods using Synthetic Images
Jul 08, 2022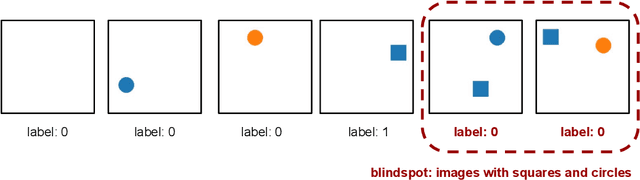
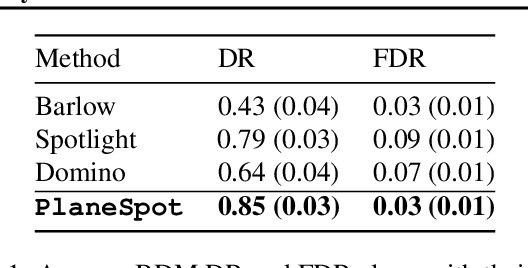
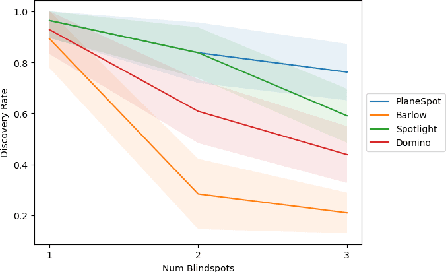

We introduce SpotCheck, a framework for generating synthetic datasets to use for evaluating methods for discovering blindspots (i.e., systemic errors) in image classifiers. We use SpotCheck to run controlled studies of how various factors influence the performance of blindspot discovery methods. Our experiments reveal several shortcomings of existing methods, such as relatively poor performance in settings with multiple blindspots and sensitivity to hyperparameters. Further, we find that a method based on dimensionality reduction, PlaneSpot, is competitive with existing methods, which has promising implications for the development of interactive tools.
Use-Case-Grounded Simulations for Explanation Evaluation
Jun 05, 2022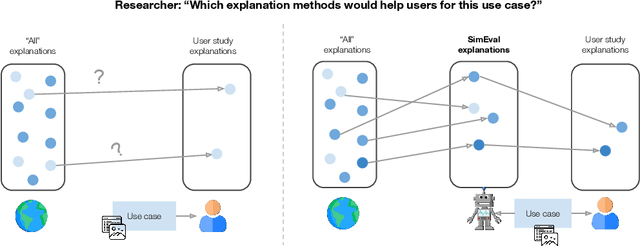
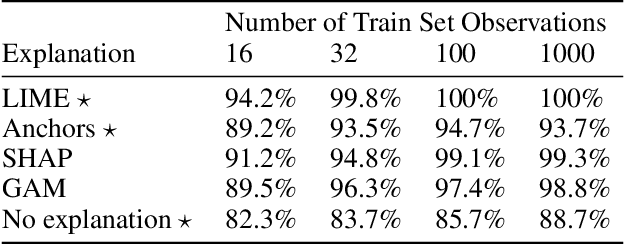
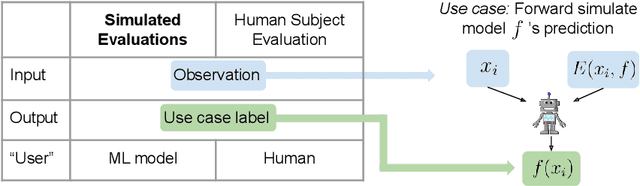
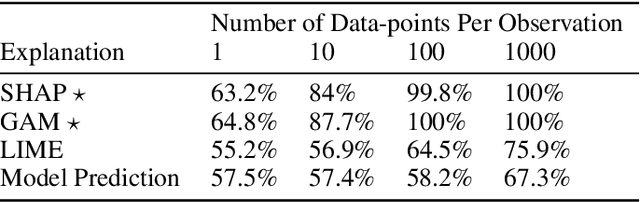
A growing body of research runs human subject evaluations to study whether providing users with explanations of machine learning models can help them with practical real-world use cases. However, running user studies is challenging and costly, and consequently each study typically only evaluates a limited number of different settings, e.g., studies often only evaluate a few arbitrarily selected explanation methods. To address these challenges and aid user study design, we introduce Use-Case-Grounded Simulated Evaluations (SimEvals). SimEvals involve training algorithmic agents that take as input the information content (such as model explanations) that would be presented to each participant in a human subject study, to predict answers to the use case of interest. The algorithmic agent's test set accuracy provides a measure of the predictiveness of the information content for the downstream use case. We run a comprehensive evaluation on three real-world use cases (forward simulation, model debugging, and counterfactual reasoning) to demonstrate that Simevals can effectively identify which explanation methods will help humans for each use case. These results provide evidence that SimEvals can be used to efficiently screen an important set of user study design decisions, e.g. selecting which explanations should be presented to the user, before running a potentially costly user study.
Finding and Fixing Spurious Patterns with Explanations
Jun 03, 2021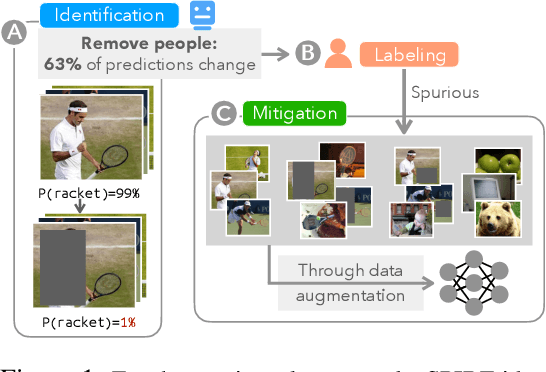
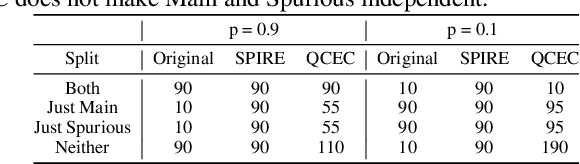

Machine learning models often use spurious patterns such as "relying on the presence of a person to detect a tennis racket," which do not generalize. In this work, we present an end-to-end pipeline for identifying and mitigating spurious patterns for image classifiers. We start by finding patterns such as "the model's prediction for tennis racket changes 63% of the time if we hide the people." Then, if a pattern is spurious, we mitigate it via a novel form of data augmentation. We demonstrate that this approach identifies a diverse set of spurious patterns and that it mitigates them by producing a model that is both more accurate on a distribution where the spurious pattern is not helpful and more robust to distribution shift.
Sanity Simulations for Saliency Methods
May 13, 2021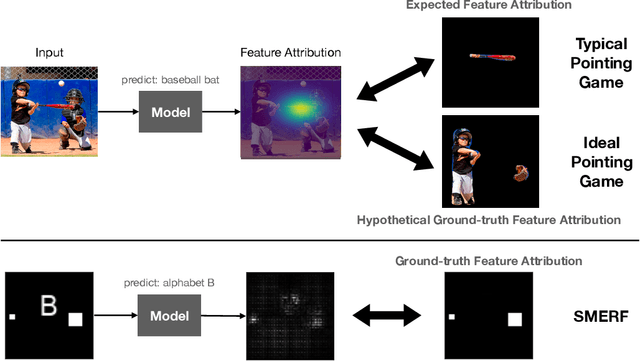
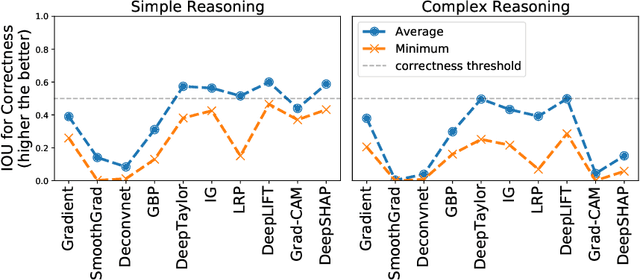
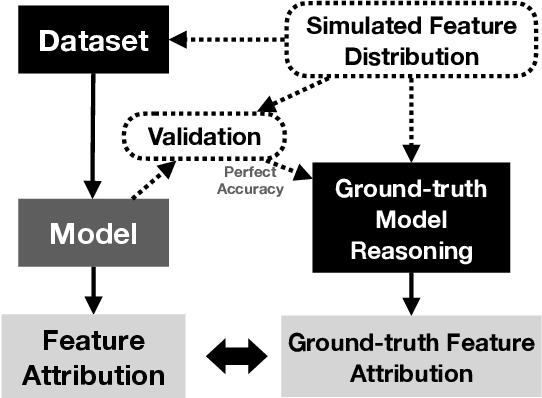
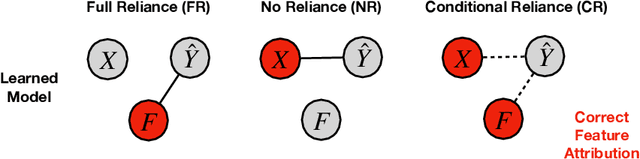
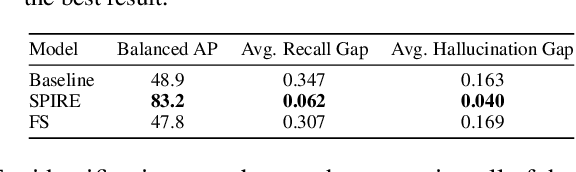
Saliency methods are a popular class of feature attribution tools that aim to capture a model's predictive reasoning by identifying "important" pixels in an input image. However, the development and adoption of saliency methods are currently hindered by the lack of access to underlying model reasoning, which prevents accurate method evaluation. In this work, we design a synthetic evaluation framework, SMERF, that allows us to perform ground-truth-based evaluation of saliency methods while controlling the underlying complexity of model reasoning. Experimental evaluations via SMERF reveal significant limitations in existing saliency methods, especially given the relative simplicity of SMERF's synthetic evaluation tasks. Moreover, the SMERF benchmarking suite represents a useful tool in the development of new saliency methods to potentially overcome these limitations.
Towards Connecting Use Cases and Methods in Interpretable Machine Learning
Mar 10, 2021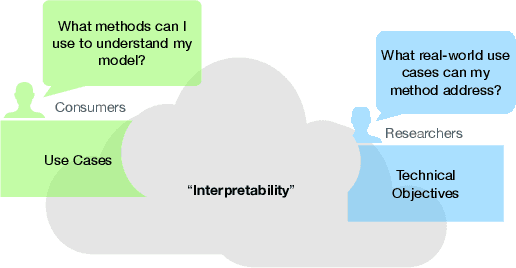

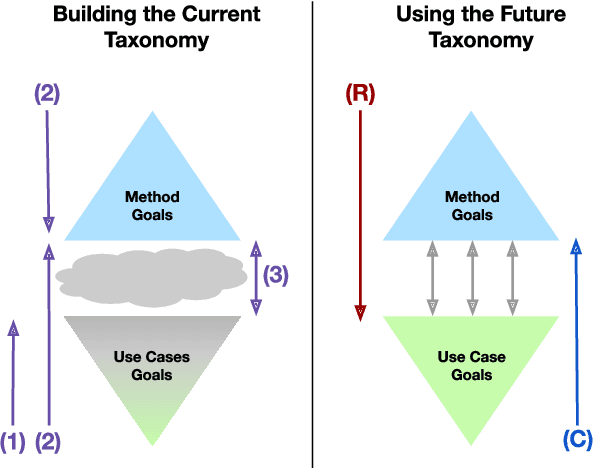
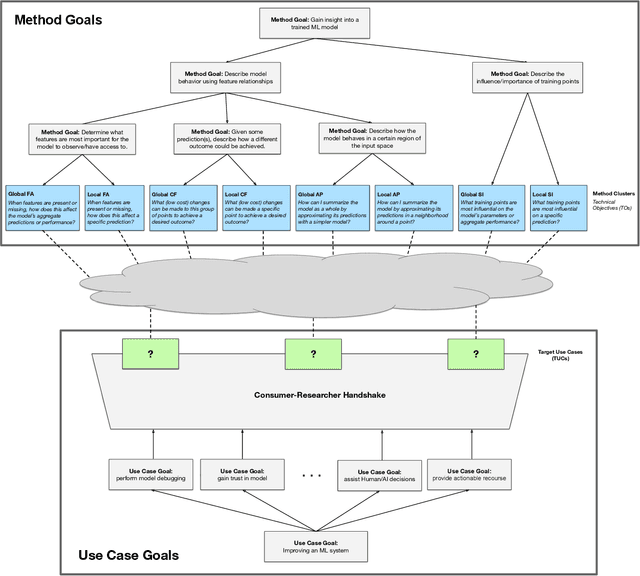
Despite increasing interest in the field of Interpretable Machine Learning (IML), a significant gap persists between the technical objectives targeted by researchers' methods and the high-level goals of consumers' use cases. In this work, we synthesize foundational work on IML methods and evaluation into an actionable taxonomy. This taxonomy serves as a tool to conceptualize the gap between researchers and consumers, illustrated by the lack of connections between its methods and use cases components. It also provides the foundation from which we describe a three-step workflow to better enable researchers and consumers to work together to discover what types of methods are useful for what use cases. Eventually, by building on the results generated from this workflow, a more complete version of the taxonomy will increasingly allow consumers to find relevant methods for their target use cases and researchers to identify applicable use cases for their proposed methods.
A Learning Theoretic Perspective on Local Explainability
Nov 02, 2020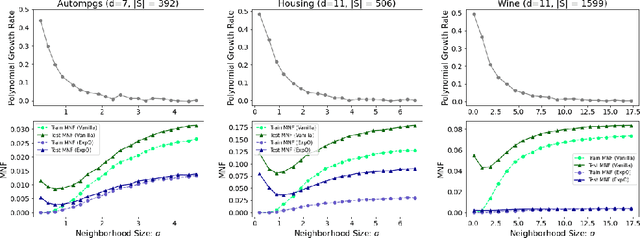
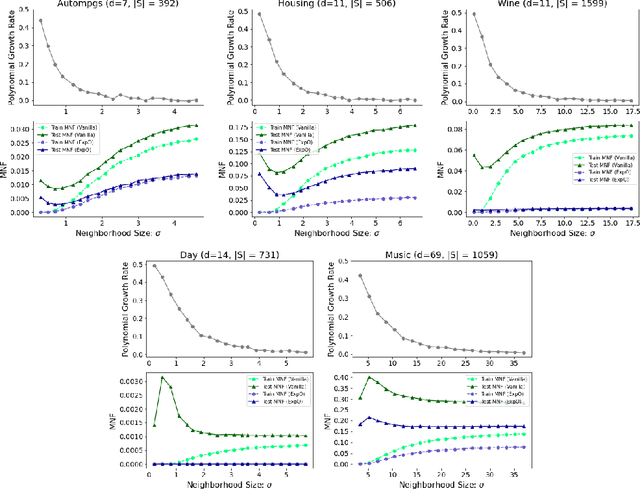
In this paper, we explore connections between interpretable machine learning and learning theory through the lens of local approximation explanations. First, we tackle the traditional problem of performance generalization and bound the test-time accuracy of a model using a notion of how locally explainable it is. Second, we explore the novel problem of explanation generalization which is an important concern for a growing class of finite sample-based local approximation explanations. Finally, we validate our theoretical results empirically and show that they reflect what can be seen in practice.
Explaining Groups of Points in Low-Dimensional Representations
Mar 18, 2020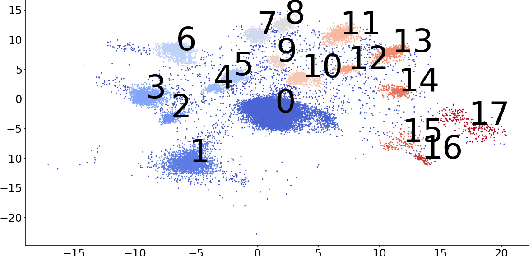
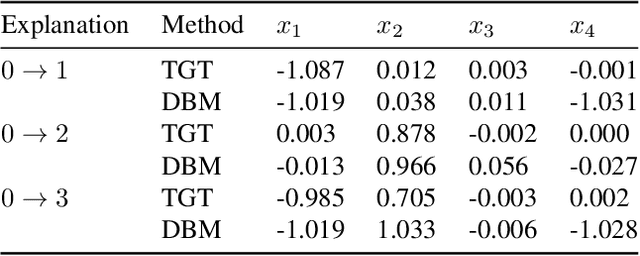
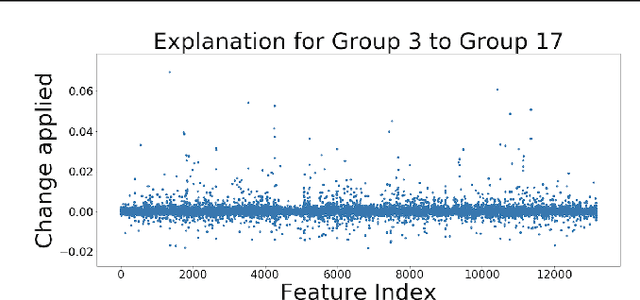
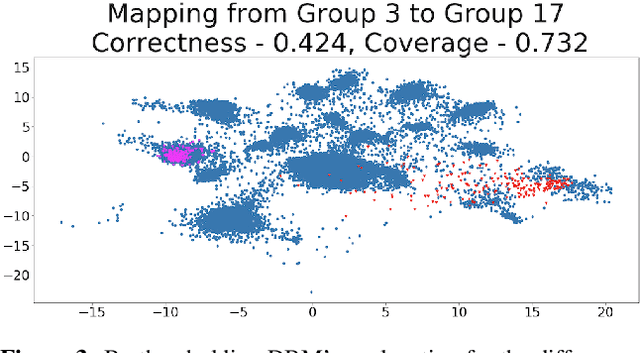
A common workflow in data exploration is to learn a low-dimensional representation of the data, identify groups of points in that representation, and examine the differences between the groups to determine what they represent. We treat this as an interpretable machine learning problem by leveraging the model that learned the low-dimensional representation to help identify the key differences between the groups. To solve this problem, we introduce a new type of explanation, a Global Counterfactual Explanation (GCE), and our algorithm, Transitive Global Translations (TGT), for computing GCEs. TGT identifies the differences between each pair of groups using compressed sensing but constrains those pairwise differences to be consistent among all of the groups. Empirically, we demonstrate that TGT is able to identify explanations that accurately explain the model while being relatively sparse, and that these explanations match real patterns in the data.
Regularizing Black-box Models for Improved Interpretability (HILL 2019 Version)
May 31, 2019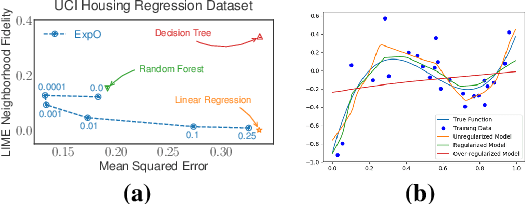
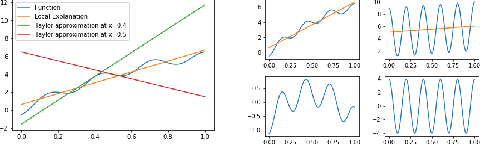
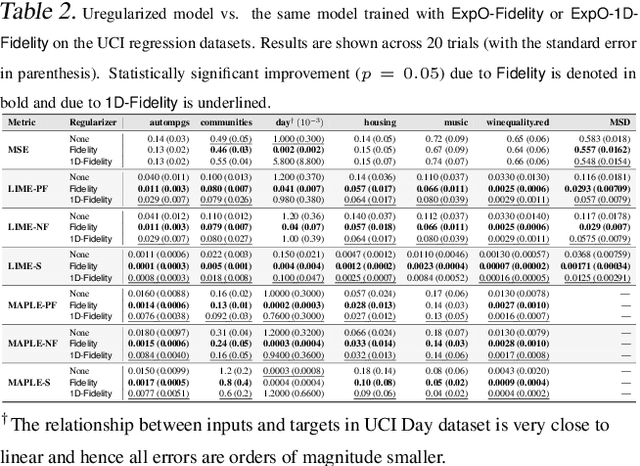
Most of the work on interpretable machine learning has focused on designing either inherently interpretable models, which typically trade-off accuracy for interpretability, or post-hoc explanation systems, which lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: (i) the model's innate explainability, (ii) the explanation system used at test time, and (iii) the metrics that measure explanation quality. Our regularization results in substantial improvement in terms of the explanation fidelity and stability metrics across a range of datasets and black-box explanation systems while slightly improving accuracy. Further, if the resulting model is still not sufficiently interpretable, the weight of the regularization term can be adjusted to achieve the desired trade-off between accuracy and interpretability. Finally, we justify theoretically that the benefits of explanation-based regularization generalize to unseen points.
Regularizing Black-box Models for Improved Interpretability
Feb 18, 2019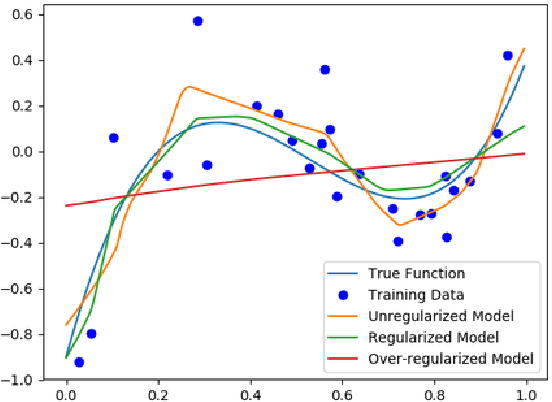
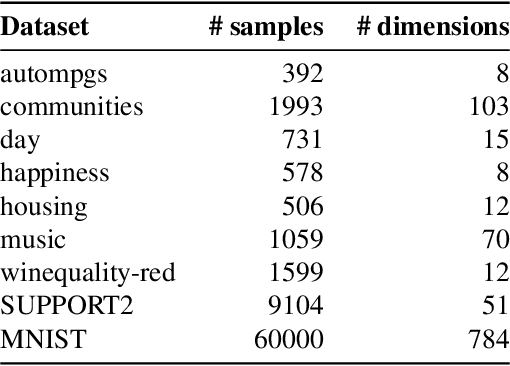
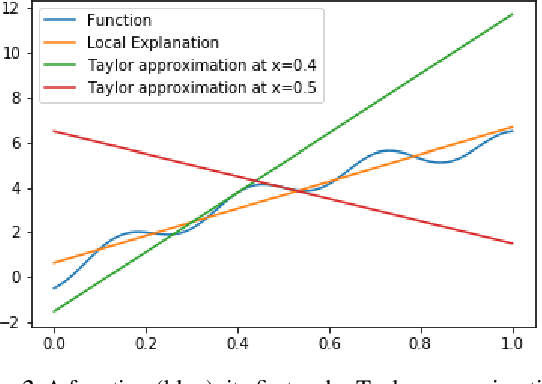
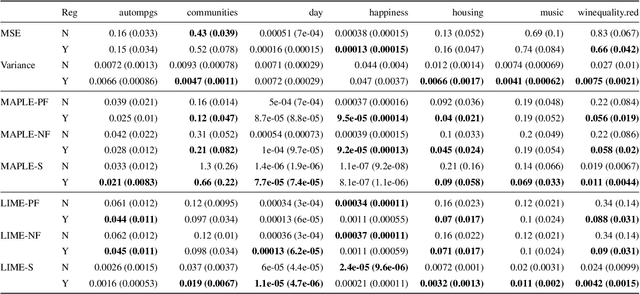
Most work on interpretability in machine learning has focused on designing either inherently interpretable models, that typically trade-off interpretability for accuracy, or post-hoc explanation systems, that lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: the model's innate explainability, the explanation system used at test time, and the metrics that measure explanation quality. Our regularization results in substantial (up to orders of magnitude) improvement in terms of explanation fidelity and stability metrics across a range of datasets, models, and black-box explanation systems. Remarkably, our regularizers also slightly improve predictive accuracy on average across the nine datasets we consider. Further, we show that the benefits of our novel regularizers on explanation quality provably generalize to unseen test points.