 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDendrogram of mixing measures: Hierarchical clustering and model selection for finite mixture models
Mar 08, 2024We present a new way to summarize and select mixture models via the hierarchical clustering tree (dendrogram) constructed from an overfitted latent mixing measure. Our proposed method bridges agglomerative hierarchical clustering and mixture modeling. The dendrogram's construction is derived from the theory of convergence of the mixing measures, and as a result, we can both consistently select the true number of mixing components and obtain the pointwise optimal convergence rate for parameter estimation from the tree, even when the model parameters are only weakly identifiable. In theory, it explicates the choice of the optimal number of clusters in hierarchical clustering. In practice, the dendrogram reveals more information on the hierarchy of subpopulations compared to traditional ways of summarizing mixture models. Several simulation studies are carried out to support our theory. We also illustrate the methodology with an application to single-cell RNA sequence analysis.
Explaining Groups of Points in Low-Dimensional Representations
Mar 18, 2020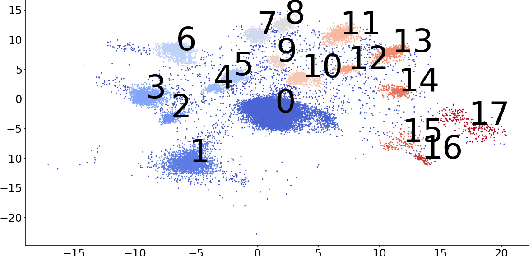
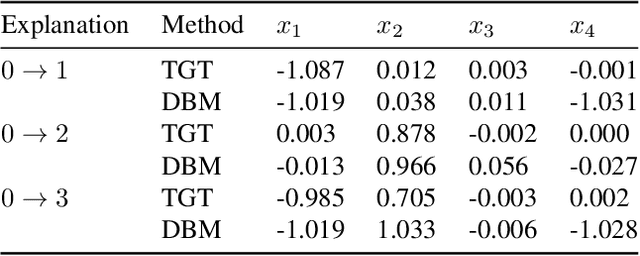
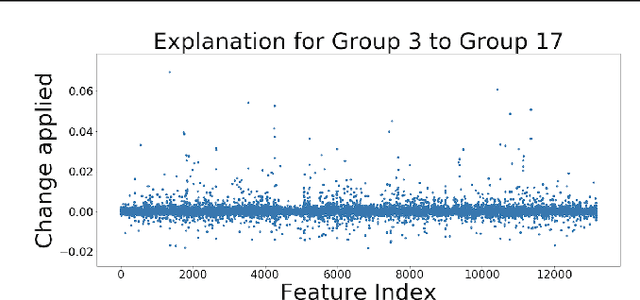
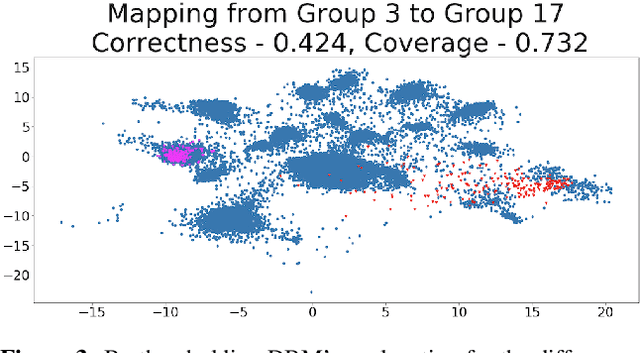
A common workflow in data exploration is to learn a low-dimensional representation of the data, identify groups of points in that representation, and examine the differences between the groups to determine what they represent. We treat this as an interpretable machine learning problem by leveraging the model that learned the low-dimensional representation to help identify the key differences between the groups. To solve this problem, we introduce a new type of explanation, a Global Counterfactual Explanation (GCE), and our algorithm, Transitive Global Translations (TGT), for computing GCEs. TGT identifies the differences between each pair of groups using compressed sensing but constrains those pairwise differences to be consistent among all of the groups. Empirically, we demonstrate that TGT is able to identify explanations that accurately explain the model while being relatively sparse, and that these explanations match real patterns in the data.
Communication-Efficient Distributed Dual Coordinate Ascent
Sep 29, 2014
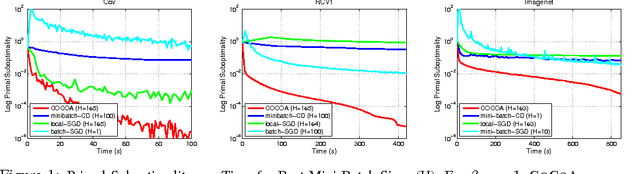
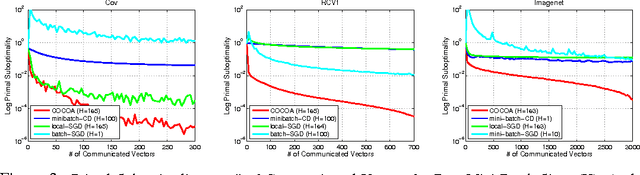
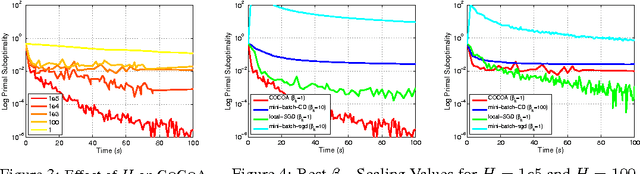
Communication remains the most significant bottleneck in the performance of distributed optimization algorithms for large-scale machine learning. In this paper, we propose a communication-efficient framework, CoCoA, that uses local computation in a primal-dual setting to dramatically reduce the amount of necessary communication. We provide a strong convergence rate analysis for this class of algorithms, as well as experiments on real-world distributed datasets with implementations in Spark. In our experiments, we find that as compared to state-of-the-art mini-batch versions of SGD and SDCA algorithms, CoCoA converges to the same .001-accurate solution quality on average 25x as quickly.