 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEA-Swin: An Embedding-Agnostic Swin Transformer for AI-Generated Video Detection
Feb 19, 2026Recent advances in foundation video generators such as Sora2, Veo3, and other commercial systems have produced highly realistic synthetic videos, exposing the limitations of existing detection methods that rely on shallow embedding trajectories, image-based adaptation, or computationally heavy MLLMs. We propose EA-Swin, an Embedding-Agnostic Swin Transformer that models spatiotemporal dependencies directly on pretrained video embeddings via a factorized windowed attention design, making it compatible with generic ViT-style patch-based encoders. Alongside the model, we construct the EA-Video dataset, a benchmark dataset comprising 130K videos that integrates newly collected samples with curated existing datasets, covering diverse commercial and open-source generators and including unseen-generator splits for rigorous cross-distribution evaluation. Extensive experiments show that EA-Swin achieves 0.97-0.99 accuracy across major generators, outperforming prior SoTA methods (typically 0.8-0.9) by a margin of 5-20%, while maintaining strong generalization to unseen distributions, establishing a scalable and robust solution for modern AI-generated video detection.
Model Selection for Gaussian-gated Gaussian Mixture of Experts Using Dendrograms of Mixing Measures
May 19, 2025Mixture of Experts (MoE) models constitute a widely utilized class of ensemble learning approaches in statistics and machine learning, known for their flexibility and computational efficiency. They have become integral components in numerous state-of-the-art deep neural network architectures, particularly for analyzing heterogeneous data across diverse domains. Despite their practical success, the theoretical understanding of model selection, especially concerning the optimal number of mixture components or experts, remains limited and poses significant challenges. These challenges primarily stem from the inclusion of covariates in both the Gaussian gating functions and expert networks, which introduces intrinsic interactions governed by partial differential equations with respect to their parameters. In this paper, we revisit the concept of dendrograms of mixing measures and introduce a novel extension to Gaussian-gated Gaussian MoE models that enables consistent estimation of the true number of mixture components and achieves the pointwise optimal convergence rate for parameter estimation in overfitted scenarios. Notably, this approach circumvents the need to train and compare a range of models with varying numbers of components, thereby alleviating the computational burden, particularly in high-dimensional or deep neural network settings. Experimental results on synthetic data demonstrate the effectiveness of the proposed method in accurately recovering the number of experts. It outperforms common criteria such as the Akaike information criterion, the Bayesian information criterion, and the integrated completed likelihood, while achieving optimal convergence rates for parameter estimation and accurately approximating the regression function.
Dendrogram of mixing measures: Hierarchical clustering and model selection for finite mixture models
Mar 08, 2024We present a new way to summarize and select mixture models via the hierarchical clustering tree (dendrogram) constructed from an overfitted latent mixing measure. Our proposed method bridges agglomerative hierarchical clustering and mixture modeling. The dendrogram's construction is derived from the theory of convergence of the mixing measures, and as a result, we can both consistently select the true number of mixing components and obtain the pointwise optimal convergence rate for parameter estimation from the tree, even when the model parameters are only weakly identifiable. In theory, it explicates the choice of the optimal number of clusters in hierarchical clustering. In practice, the dendrogram reveals more information on the hierarchy of subpopulations compared to traditional ways of summarizing mixture models. Several simulation studies are carried out to support our theory. We also illustrate the methodology with an application to single-cell RNA sequence analysis.
Strong identifiability and parameter learning in regression with heterogeneous response
Dec 08, 2022



Mixtures of regression are a powerful class of models for regression learning with respect to a highly uncertain and heterogeneous response variable of interest. In addition to being a rich predictive model for the response given some covariates, the parameters in this model class provide useful information about the heterogeneity in the data population, which is represented by the conditional distributions for the response given the covariates associated with a number of distinct but latent subpopulations. In this paper, we investigate conditions of strong identifiability, rates of convergence for conditional density and parameter estimation, and the Bayesian posterior contraction behavior arising in finite mixture of regression models, under exact-fitted and over-fitted settings and when the number of components is unknown. This theory is applicable to common choices of link functions and families of conditional distributions employed by practitioners. We provide simulation studies and data illustrations, which shed some light on the parameter learning behavior found in several popular regression mixture models reported in the literature.
Beyond Black Box Densities: Parameter Learning for the Deviated Components
Feb 05, 2022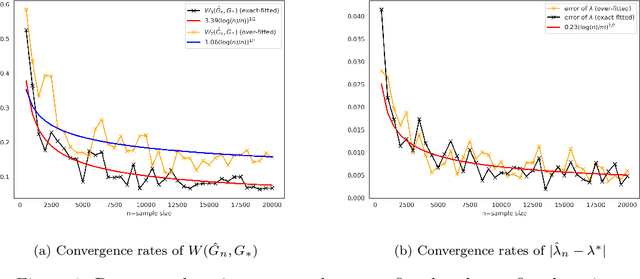
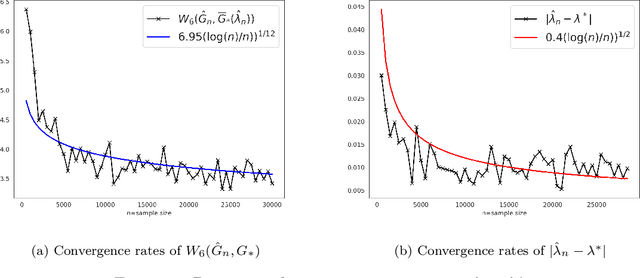
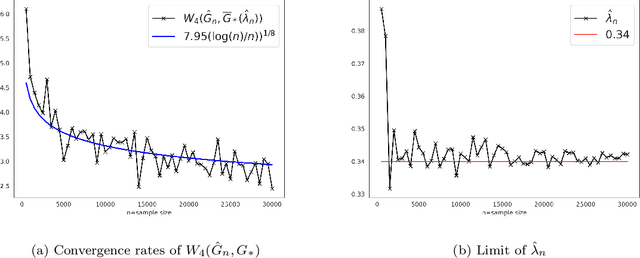
As we collect additional samples from a data population for which a known density function estimate may have been previously obtained by a black box method, the increased complexity of the data set may result in the true density being deviated from the known estimate by a mixture distribution. To model this phenomenon, we consider the \emph{deviating mixture model} $(1-\lambda^{*})h_0 + \lambda^{*} (\sum_{i = 1}^{k} p_{i}^{*} f(x|\theta_{i}^{*}))$, where $h_0$ is a known density function, while the deviated proportion $\lambda^{*}$ and latent mixing measure $G_{*} = \sum_{i = 1}^{k} p_{i}^{*} \delta_{\theta_i^{*}}$ associated with the mixture distribution are unknown. Via a novel notion of distinguishability between the known density $h_{0}$ and the deviated mixture distribution, we establish rates of convergence for the maximum likelihood estimates of $\lambda^{*}$ and $G^{*}$ under Wasserstein metric. Simulation studies are carried out to illustrate the theory.
On Label Shift in Domain Adaptation via Wasserstein Distance
Oct 29, 2021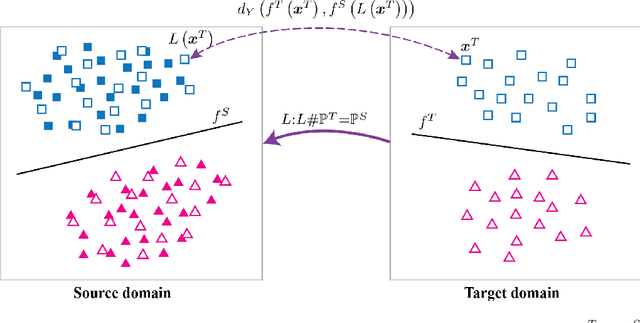
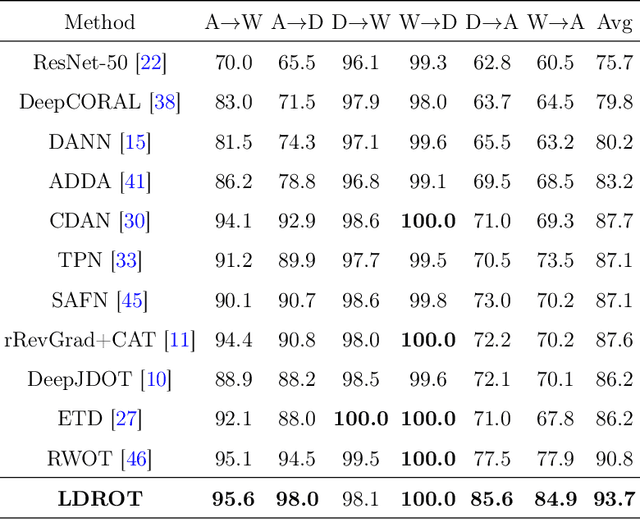
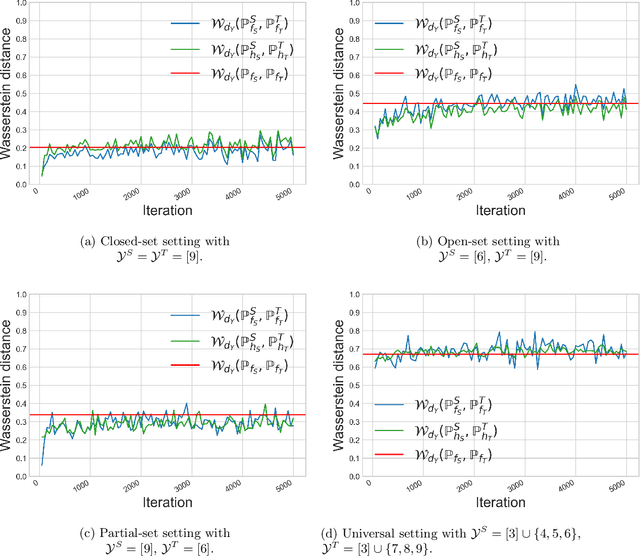
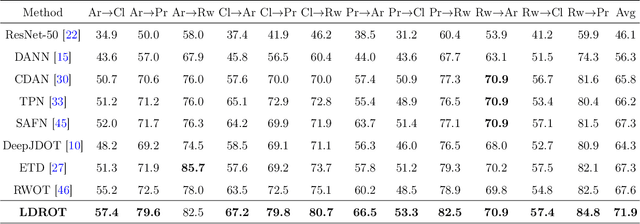
We study the label shift problem between the source and target domains in general domain adaptation (DA) settings. We consider transformations transporting the target to source domains, which enable us to align the source and target examples. Through those transformations, we define the label shift between two domains via optimal transport and develop theory to investigate the properties of DA under various DA settings (e.g., closed-set, partial-set, open-set, and universal settings). Inspired from the developed theory, we propose Label and Data Shift Reduction via Optimal Transport (LDROT) which can mitigate the data and label shifts simultaneously. Finally, we conduct comprehensive experiments to verify our theoretical findings and compare LDROT with state-of-the-art baselines.
Entropic Gromov-Wasserstein between Gaussian Distributions
Aug 24, 2021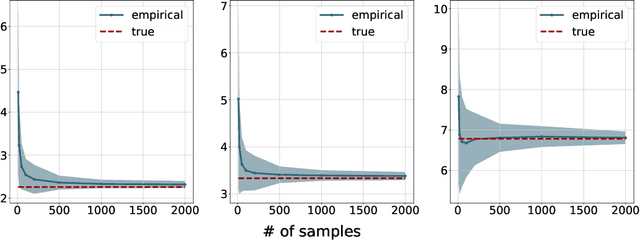
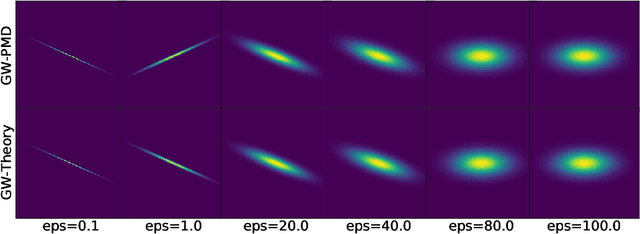
We study the entropic Gromov-Wasserstein and its unbalanced version between (unbalanced) Gaussian distributions with different dimensions. When the metric is the inner product, which we refer to as inner product Gromov-Wasserstein (IGW), we demonstrate that the optimal transportation plans of entropic IGW and its unbalanced variant are (unbalanced) Gaussian distributions. Via an application of von Neumann's trace inequality, we obtain closed-form expressions for the entropic IGW between these Gaussian distributions. Finally, we consider an entropic inner product Gromov-Wasserstein barycenter of multiple Gaussian distributions. We prove that the barycenter is Gaussian distribution when the entropic regularization parameter is small. We further derive closed-form expressions for the covariance matrix of the barycenter.